
3 years after Data mesh: lessons learnt from early believers of the mesh


Back in 2019. At that time, I was deploying a data lake strategy inside Michelin and we had decided to build the main one as a platform to enable more data use case. I was having a coffee while reading my mail. In my box came an email from one of my best colleagues.
“Hey,
I have just read this article from Zhamak Dehghani,
https://martinfowler.com/articles/data-monolith-to-mesh.html
It seems we are not the only one trying to push platform in the data world. This architecture approach at Thoughtwork is becoming more and more popular. My view is that we should talk about it and see where it is leading us.”
And so, we started reading the article in depth, considering how to adapt or complete our current strategy, and we completely adopted the mesh approach.
0 – How it all began: a distributed software architecture
In 2019, we had been removing IT software monolith for over five years. Instead, we deployed a distributed architecture from manufacturing to CRM and all along our supply chain. This architecture pattern proved very helpful to provide flexibility in the decommissioning, it also provides a better resilience in the solution and avoids bottleneck effect. In parallel, we had also acknowledged that one size no longer fits all, and we were introducing less and less standardization in the way we manage our processes.
This context encouraged us to create an important number of analytics products to reconcile the data from those different distributed products. We were, as usual, calculating plenty of KPI to steer our processes, but data was coming from more systems than before.
It has led 80% of our analytics effort around 10 to 15 key group analytics solution that were facing difficulties to consolidate and reconcile the different data at the pace they were emerging.
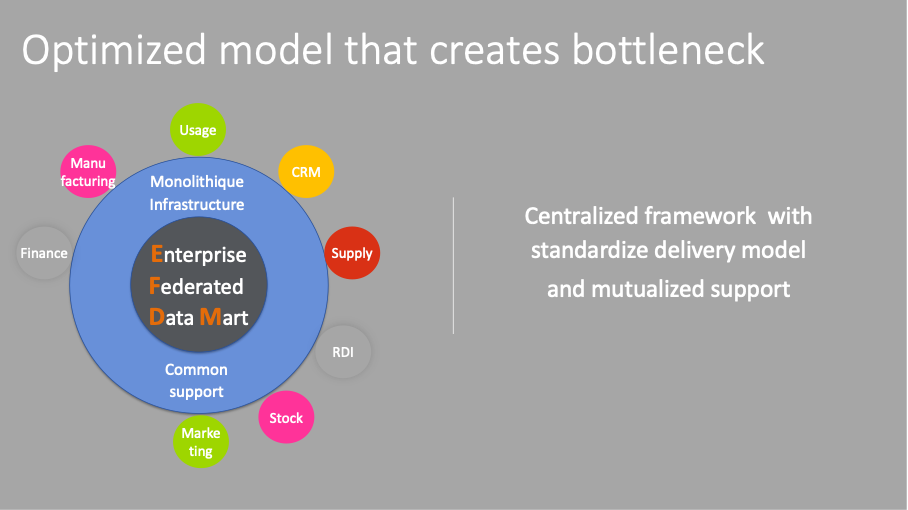
To build these analytics products we had created an optimized framework to ensure a common development methodology and a centralized support. This on-premises framework was very efficient to ensure standardization, but delivery was slow and expensive, and it couldn’t take into accounts the worldwide requirements.
1 - Previously on data mesh: Yet another article explaining the theory?
If you are interested in data but if you did not have access to internet for the last 3 years, it is very likely that you are probably not aware of the data mesh architecture paradigm. I will quickly remind you of what is in it. I will then tell you what we did and where we stand now on the different pillars.
If you already know about the data mesh, please move to the next section.
In a world where companies want to be data driven and to do data science, a data mesh is an architecture that supports the increasing number of use cases leveraging data. It is at core, the distribution of responsibility to people who are closest to the data in order to support continuous change and scalability.
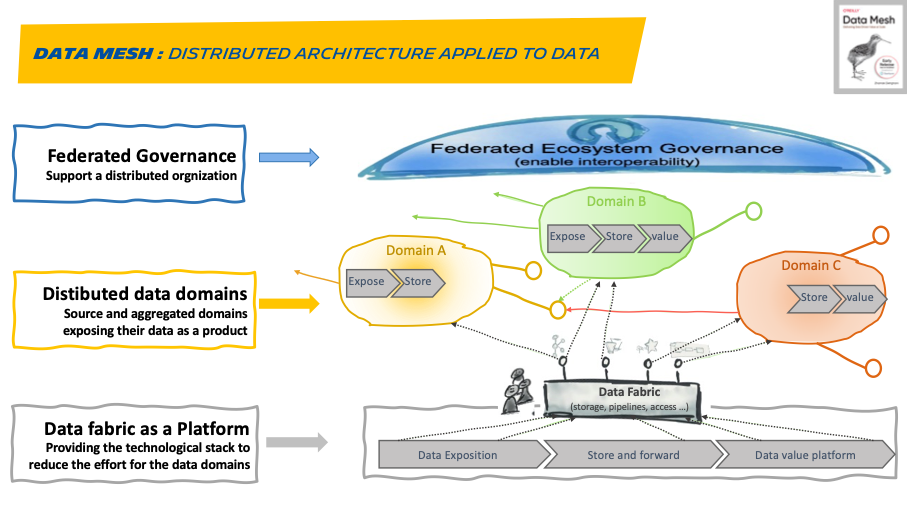
The mesh is developed around 3 pillars:
· Distributed data domains: Instead of flowing the data from domains into a centrally owned data lake that would create a bottleneck, domains need to host and serve their datasets in an easily consumable way. They must apply product thinking to their datasets to make them Discoverable, Addressable, Trustworthy (defined and monitored SLO’s), Self-describing, Inter operable and Secure. A data domain is managed by a data owner who makes decisions around the vision and the roadmap for the data products, focusing on consumer satisfaction and continuously measuring the quality of the data he produces
· Federated Governance: Data Mesh creates a collection of independent data products, but for most part of the value interoperating between the different domain is required. Data domain product owners as well as data platform product owner must apply a set of common rules. Maintaining a balance between autonomy and global rules is a hard job for the governance. Federated governance of the mesh, in contrast with the traditional governance, embraces change and multiple interpretive contexts.
· Data fabric as a platform: A fair bit of infrastructure needs to be provisioned and run to support data pipelines. It would be difficult to replicate in each domain the highly specialized skills required to provision this infrastructure. That’s why, to simplify the on-boarding of the different domains, the data mesh promotes the creation of a self-served data infrastructure. Domains providing data as products still needs to be increased with new skill sets such as data engineers but focused on pipeline creation and with a lower complexity. A wonderful side effect of such cross-functional organization is cross pollination of different skills (software and data).
Ultimately, Data must be treated a foundational piece of any software ecosystem.
At Michelin, we were lucky to be highly encouraged and supported to move in this direction by our CIO and his Chief enterprise architect. Let me now explain the different steps of our journey.
2 - Govern the data domains: One mesh to rule them all.
In 2019, the business data governance did not exist at all at Michelin. The different IT products were managed independently, asking either the integration team or the master data management team to manage their interoperability and asking the analytics teams to collect and reconcile their data.
Data Custodian: data governance starts with IT. There is no need for a business governance to start taking care of your data. It is our responsibility as IT to ensure that the data we push on the lake or the events we publish are under control. For this reason, we have introduced data custodian as the first layer of governance.
It does not require a full time Job, but it is a role given to an IT analytics team member (most of the time the best functional expert). Their role is to define technical standards (naming of the objects, metadata to capture), ensure dataset are classified and documented in the different products. They must cover all the data products, but we only have custodians in the key domains, and they have representatives in the sub-domains spending less time on this role activity.
As such, they are organized into a network led by a lead data custodian who ensures that there is a data custodian representative in each data products and animates regular ceremonies.
Business data governance: Connecting business to their data products.
At Michelin, one of the first goals of our chief data officer was to setup this global governance covering and connecting the different domains of the enterprise.
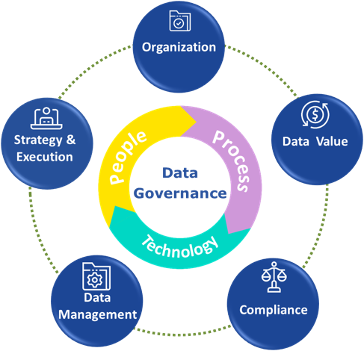
The data governance main missions are:
- Defining the semantic of the different items
- Informing users on security policies and monitor access rights
- Defining and monitor data quality expectation
- Evaluating the completeness of the exposition and build a roadmap
- Using the catalog to link the semantics with the data products
- Working with the other domains to ensure interoperability
We have introduced new roles to ensure those different missions, but in the business team this time. Who are they ?
Data owners who manage the data lifecycle and who define quality and security rules in their domain. They are organized in a network animated by a lead data owner and in direct link with the process owners and the Chief data officer. At Michelin, there are 4 lead data owners animating 3 to 10 data owners. Their domains are Manufacturing, Research and development, Services and solution and Business services for all the other domains in the enterprise.
Data steward defining data semantics in the catalog, implementing IT product exposition and quality features. This is not a mandatory job, this role can sometimes be played by the product owner of an existing IT product.
Data administrator creating, updating, removing and auditing system values, access and ensuring data quality.

Creating these different roles begins to prove powerful if they act as a network, meeting and sharing in different ceremonies. The key initiative that the governance manages as a network is implementing the data catalog around Collibra.
The data catalog is the place where the business semantics is deployed and creates a lot of interesting discussion on how to organize the common data. But the data catalog is also a key tool for the data custodian to document their datasets and will become a one stop shop for data access. To ease the search on the catalog, the business items are linked to the datasets hosting the data so that they become connected to their data products.
3 - Data domains exposing their data as a product
To begin with, let’s try to understand what a data product could look like. A data product exists to serve a consumer who wants to make a decision based on data. Our Data enterprise architect always reminds me that famous expression “Without data, you’re just another person with an opinion” from W. Edwards Deming.
A data product short definition could be a published data set that can be accessed by others. It acknowledges the fact that it exists consumers of the data beyond the domain who creates it.
To ease the understanding and usage of the data products, metadata like owner, frequency data sensitivity and models needs to be described. The domain team producing or aggregating the data is in charge to operate the product during its entire lifecycle and ensure the data quality.
But it has much more characteristics that are described in the schema below and where we still need to progress on definitions and deliverables.
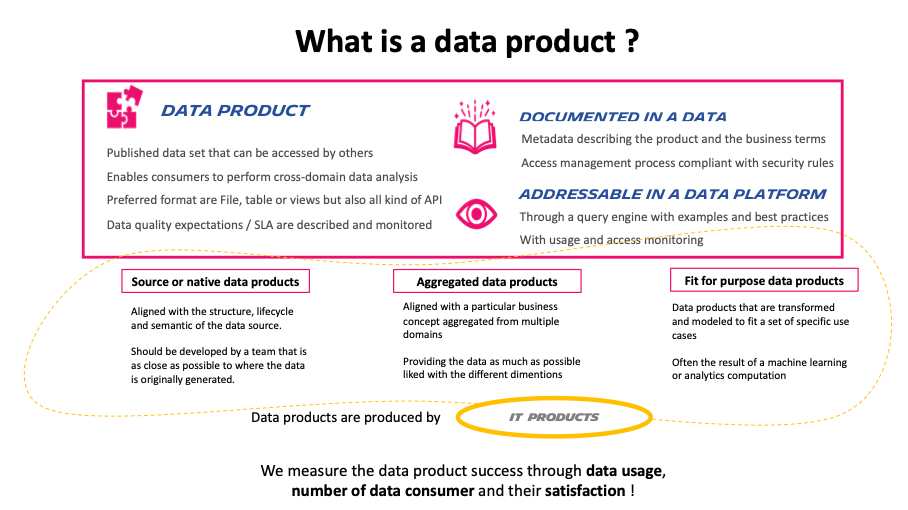
At Michelin, what we push for is ensuring that data owners govern source and aggregated products well. They should measure their success by the number of Fit for purpose products they serve. We begin by measuring the platform usage, but we are now able to measure usage on some of the key data products (number of users and number of sessions) and this has revealed difference between products that was totally unexpected.
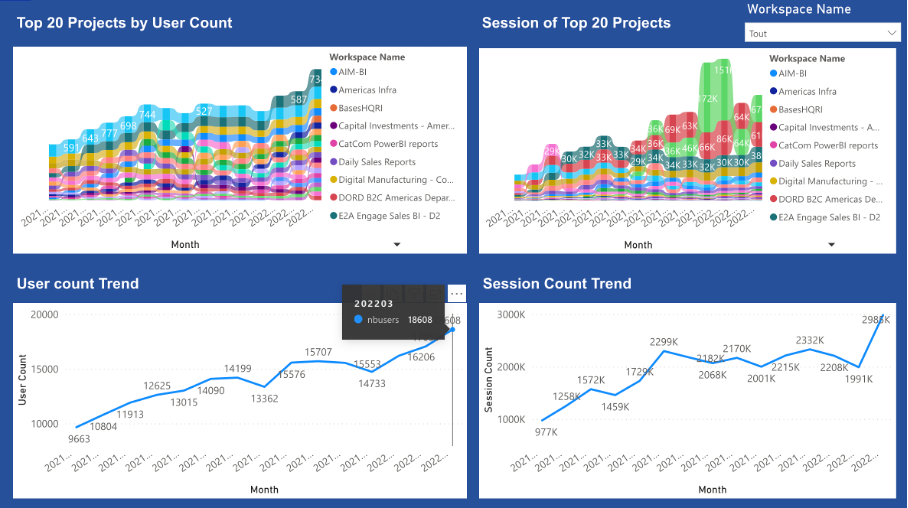
All our products do not look like this, but some of them do and others improve every day. Where we plan to make progress this year is on the data quality. We would like to develop a practice around frameworks such as greatexpectations.io for example.
To ensure that source data products will expose their data, we have edited a new architecture principle that any data producer must apply.

With this principle any IT system is in charge of exposing its data to the platform. The exposition can be event based of course, but also needs to serve analytics use cases with files or tables storage. To help these two transformations (Event driven architecture and data driven) to take place we need to ease the path for a team to move from events to the lake.
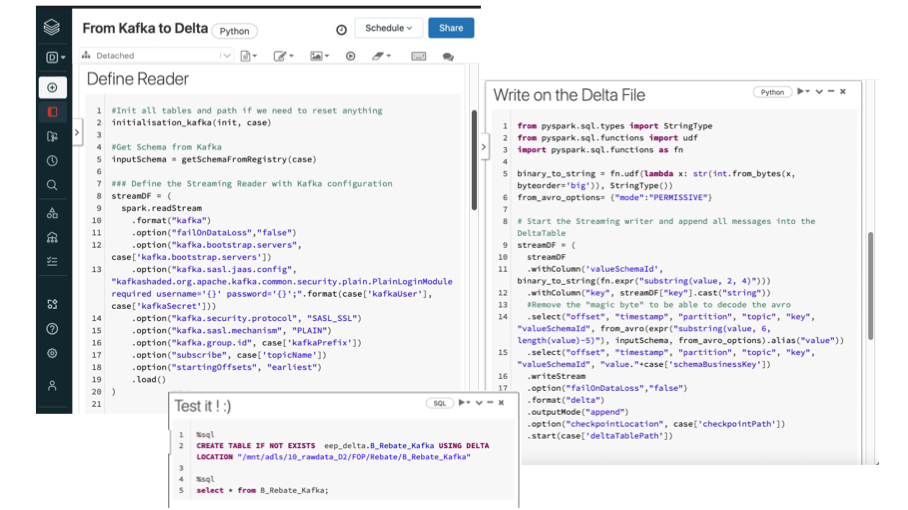
We did it through generic integration pattern to provide ‘Event integration to Datalake’ service in our data platform and started on some MDM systems and ERP.
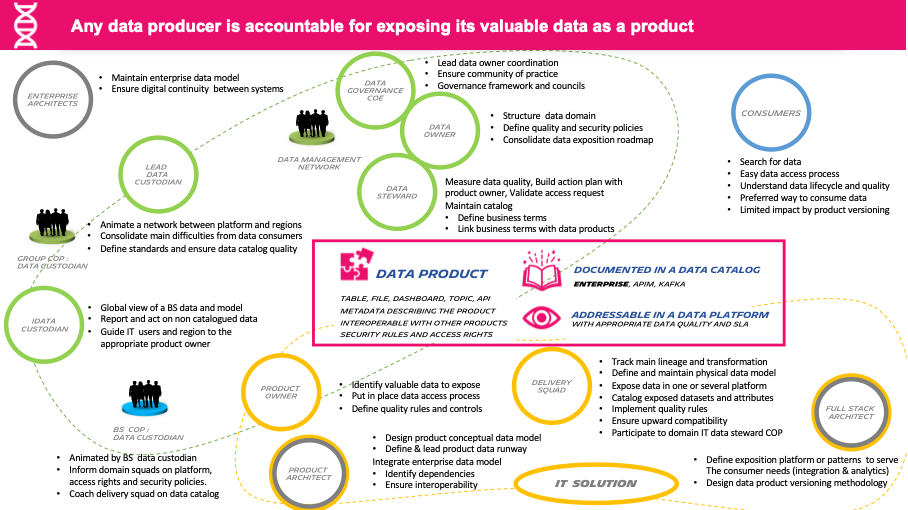
We ultimately create this synthesis slide to remind who are the different persona working on a data product and what are their main missions.
And it works:
At Michelin, we experimented one big success using this approach to help the different zones create their own BI with a limited effort. Central teams were building tools focused on standardization. Local teams were not using these tools at the expected level due to lack of local data and transverse vision between processe
New solutions were created all over the world to allow a transverse access to their data and to consider their local business models. The side effect was that they did not have the same figures, in particular for the KPI.
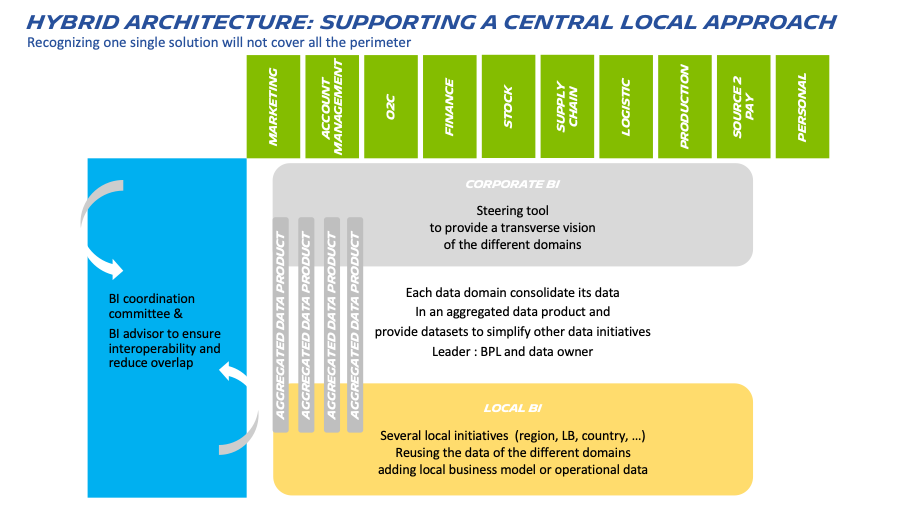
Instead of fighting against the local team, we decided to promote the access to the data that were consolidated in central and acknowledge that some of their needs will not be covered by a central team (or only in a 10-year roadmap). After 2 years of this central-local approach, 60% of the data used in the local solution comes from central products and the interaction between the different teams helps us better understand how the business takes place locally. But all this reuse has to be made possible by an appropriate common framework.
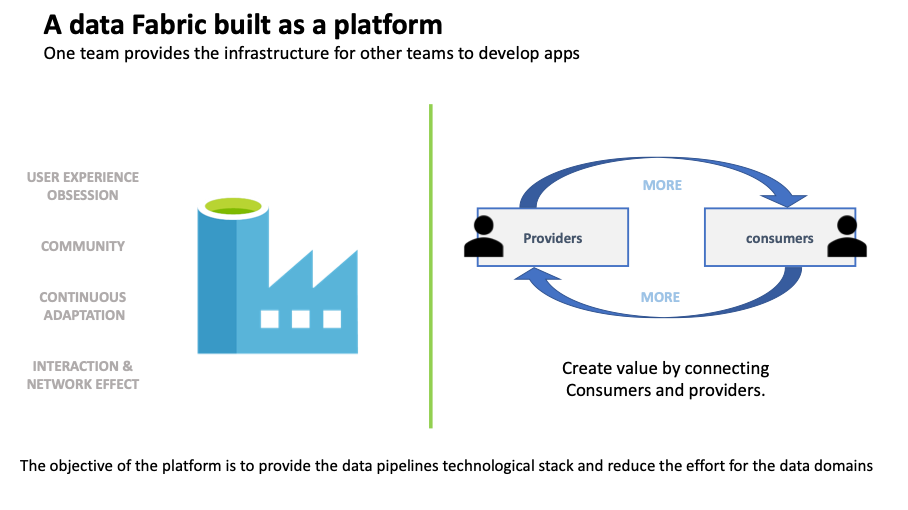
4 – Data platform, the masterpiece of the data mesh.
If you ever wish to build a platform, do not start with technology. It is first to understand that the platform team will only be in charge to offer capabilities to the feature teams. The use case will be delivered by other teams (we call them feature teams in opposition to the platform team) as much as possible in a you build it you run it approach (the feature teams organize the run of their features).
The platform is here to accelerate new product creation:
- Infrastructure or Services are provisioned quickly in a secure framework
- Support is given to feature teams through a platform portal, social communities, coaching or training kits
- Developer experience is improved by addressing needs that can be standardized as a new service of the platform.
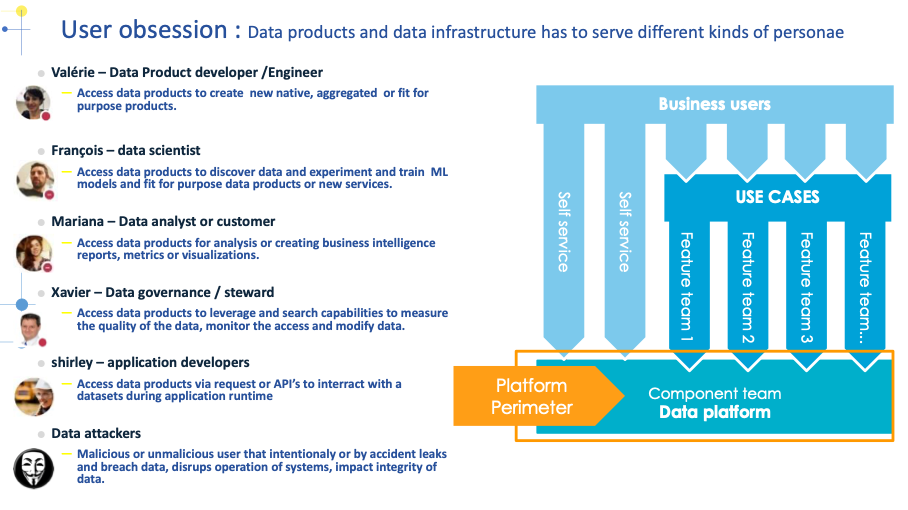
To better understand which feature the platform will have to provide, user obsession and continuous adaptation based on their feedback is needed. We have identified the following persona that we need to serve, attackers being perhaps the one we need to serve the best for our secrets data.
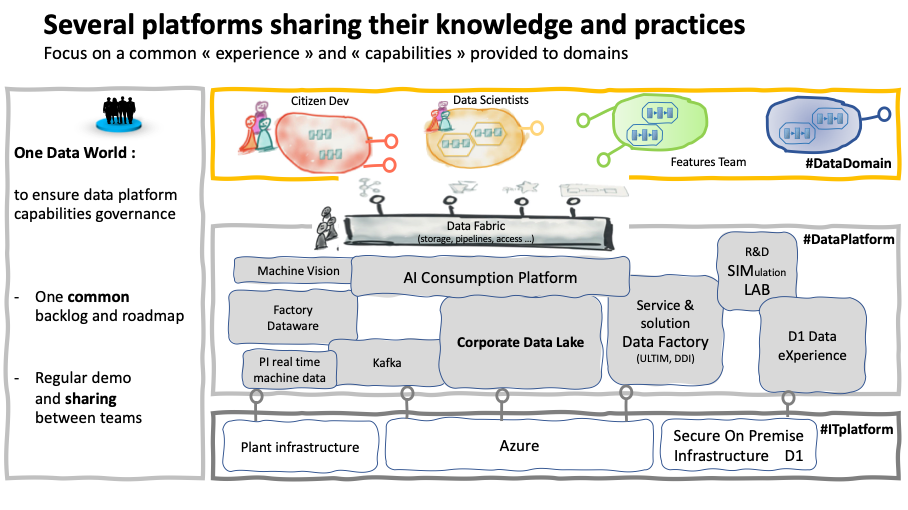
At Michelin we have several platforms to cover different specificities of our business. I can easily imagine smallest companies have fewer than us, but it’s already a challenge to embrace the variety of tools our offer requires. The Corporate data lake is our main platform on the cloud and covers most of the use cases, but we also need to have separate offers for trade secrets, for events or in the plants … To avoid reinventing the wheel in these different teams we have setup a platform governance called One Data World. The main goal of this governance is to ensure sharing between the different teams and to rationalize only when it’s obvious that the teams will collaborate. We currently try to add federation technologies to avoid systematic data replication.
Data mesh scope is broader than what we thought and blur the frontiers between transactional & analytical word.
We need to continue to connect analytical plane and transactional plane some teams being able or willing to address both words. We expect to have more application developers embracing the data world and creating not only source data products. We also need our data engineers and scientists to improve their development approach but perhaps it’s time for our software teams to also provide platforms to develop new applications easily.
Connecting the dots of the data mesh: continuation
Michelin creates insights from multiple sources inside and outside our organization: we need to simplify enrichment and sharing between the different producers and consumers, and we are convinced that the data mesh is the best approach even if there is still a long journey ahead.
Organization slide of our CEO Florent Menegaux.
By decoupling the domains, organizing the governance, and providing capabilities through a platform that wasn’t present in our previous centralized framework we believe we have not done yet another data mesh washing but embraced its intrinsic concept.