
Anti-Corruption Layer : Transforming Legacy Applications into Modern Cloud Native Applications
.jpg)

As part of my team's modernization we decided to review all aspects of our application to make our features and processes streamlined which included the data and the data schemas. We knew we had some outdated schemas that needed to be reorganized. We also decided not to migrate over all the existing data as some of it may not be necessary for our modern application. As part of this process, we decided to use an ACL.
What is an ACL?
It is not an Access Control List. An Anti-Corruption Layer (ACL) is a set of patterns placed between the domain model and other bounded contexts or third party dependencies. The intent of this layer is to prevent the intrusion of foreign concepts and models into the domain model. This ACL layer is typically made up of several well-known design patterns such as Facade, Adapter and Translator. The patterns are used to map between foreign domain models and APIs to types and interfaces that are part of the domain model.
Facade
A facade is a simple interface to a complex system. The facade owns retrieving the legacy data in the legacy data's format. A facade isolates the complex code from other subsystems.
- A facade can be accessed through raw SQL, API calls, etc.
- A facade should only own 1 connection, so having multiple facades should be expected when data comes from multiple sources
- The data is expected to be turned into software data at this point
- XML -> Java data object
- A facade may cut own unneeded data from reaching deeper into the ACL
- A facade may not necessarily implement all services that are available.
Without using an ACL facade, modifying existing integrations or services becomes complex. The services are tightly coupled and modernizing the application becomes difficult.
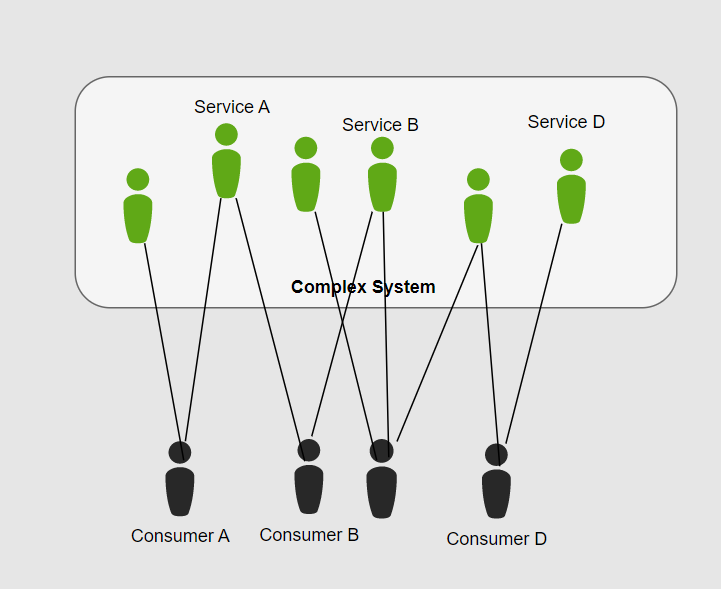
Implementing a facade in the ACL loosely couples existing systems together which reduces the complexity of modernizing the existing legacy systems.
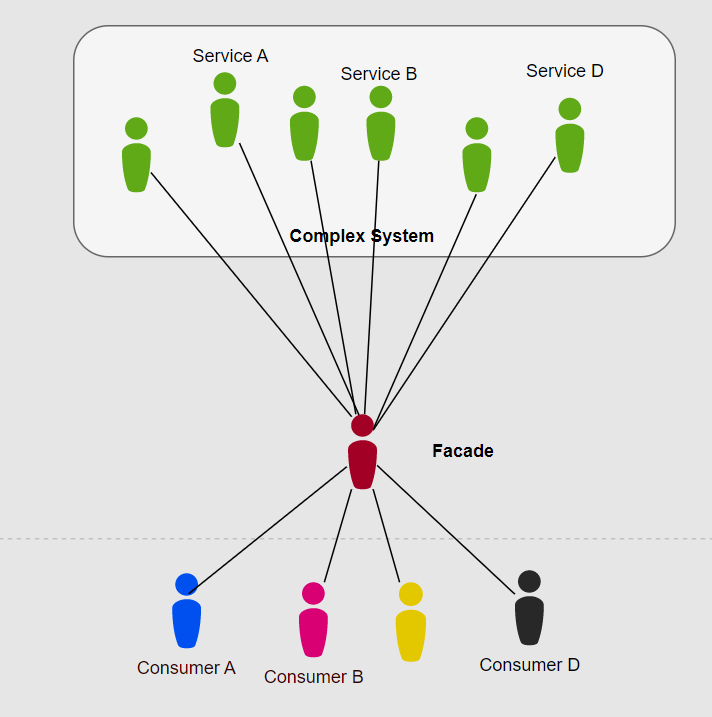
Read this article which better explains a facade.
Adapter
An adapter is the communication between two disparate systems which provides an interface that could be made useful. The adapter owns the process of taking the data in the legacy format and getting to a resulting new data format which could mean calling a translator if the data structures are different. If the data structures are the same or similar a translator might not be necessary.
- In a two way ACL, it might also own the process of returning to the original format or be separated into two paths
- Each new data type should only have 1 adapter since it functions mostly as an orchestrator, multiple orchestrators increases complexity with low value add.
- The adapter process can vary in complexity from simple 1:1 mapping with a new object() to requiring calculations; the more complex the process, the greater the need for a separate translator.

Read this article on adapters for further explanation.
Translator
The translators owns the complexity of the data transformation. A translator contains the rules and logic to convert the data formats and structures between systems. The simplest version of a translator is an object constructor that accepts the previous object as the input. A complex translator may need deep domain knowledge from the legacy system in order to compute a field.
- The new system wants MPH(Miles Per Hour) or KPH (Kilometers Per Hour) but the legacy system only has distance and time.
A translator will also be responsible for changing the depth data appears, as it is the piece that will know where the data is in the legacy model and where it belongs in the new model.
- Mapping is one technology used here, and some libraries exist for "Automapping" between two formats
- some of these are also reversible, depending on the types of data and if calculations are involved
Use Cases
Here are some example use cases for using an ACL for an application. The advantage of implementing an ACL between multiple systems eliminates the need to customize the legacy application, the third party systems or SaaS solutions.
- Legacy application is unable to be modified however the data that resides on the legacy needs to be migrated to the modernized application
- Sending data from third party systems to a legacy application. Most applications have integrations from third party systems. You can use an ACL instead of flat file integrations.
- Two systems that have different schemas that share data. For example invoices from one system that is integrated into a Point Of Sale (POS) application
- Migrating data from old legacy to a modernized application
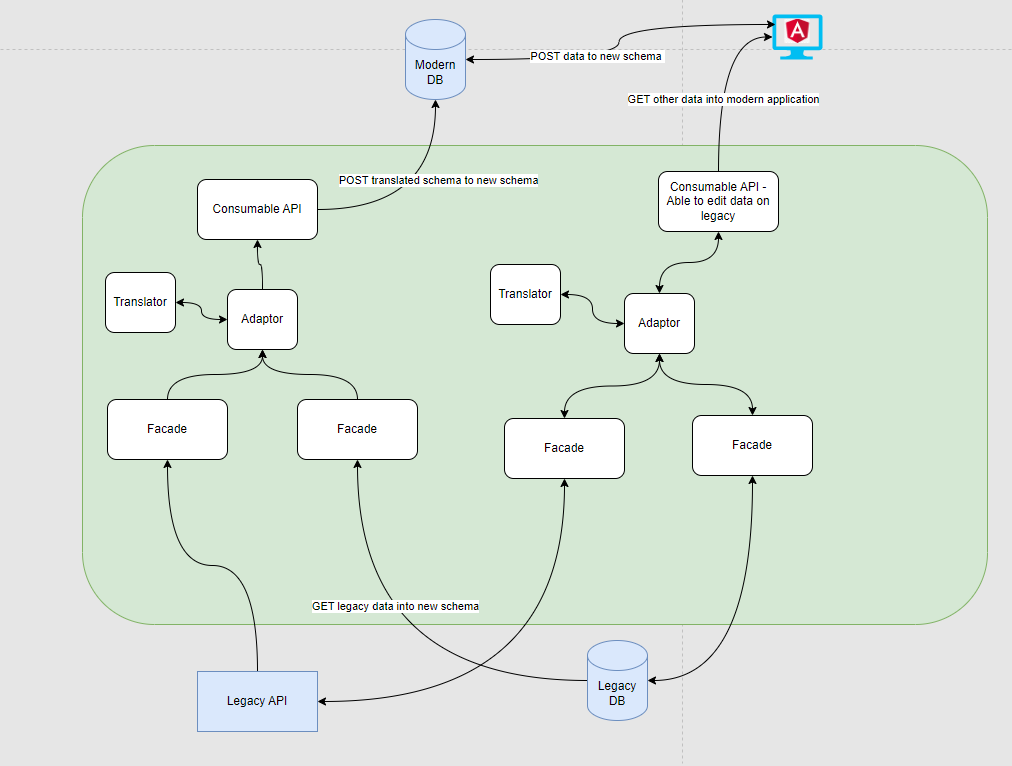
In the image above, the outlined green box is an example of one ACL application that has the three patterns of a facade, adaptor and translator that can pull data from multiple sources.
Considerations
- The ACL should not be long lived wherever possible. In our use case, we needed to modernize the data structures so we wanted to remove the legacy database as soon as possible. However there could be use cases to keep an ACL if you are receiving legacy data from other systems. There is a tendency for the engineers or the business to not prioritize removing the ACL after it is in place and it works well. You must weigh the benefits versus the risks of keeping an ACL.
- Keep complex business code out of the ACL.
- Keep the ACL as simple as possible to translate existing data into the receiving data schema.
- There is an operational overhead on utilizing an ACL. Implement monitoring and alerting tools where possible.
- An ACL can become a single point of failure if all of your legacy data flows through the ACL.
- It is not recommended to use one ACL to migrate over all of your data. For example, our team will be using a new ACL for migrating transactional data versus including it in the existing ACL. This allows us to keep each ACL as simple as possible. Consider eliminating the existing ACL before you start migrating additional data to your new modern application to reduce complexity.
- There could be an increase in latency for utilizing an ACL.
- It is costly to build and maintain an ACL for the life of the application. The business must weigh the advantages and disadvantages of building an ACL.
Our Approach
Our existing legacy application has a relational database plus we had many flags and fields that were not being utilized. We decided to use an ACL to migrate over existing data without any extra fields that are currently unnecessary. Our existing schema currently has nine associated tables joined by foreign keys.
Our modern application will be deployed to Kubernetes and utilizing a JSONB column to store the majority of these nine records into one record in PostgreSQL database. This should allow us to access the data with one query versus the nine joined tables in our legacy database.
In Kubernetes, we will be able to utilize the scaling features to scale our application vertically or horizontally when needed as well as have more robust monitoring tools such as Grafana and Splunk. In our context, we are using Grafana for monitoring metrics such as performance of the application whereas we use Splunk for logging and some alerting functionality.
Example Adapter Code

Example Translator Code
This snippet shows us taking the output from the legacy application and building one line of data for our modern application
Modernized schema
Our modernized schema is one table with a large majority of the data in the JSONB field.

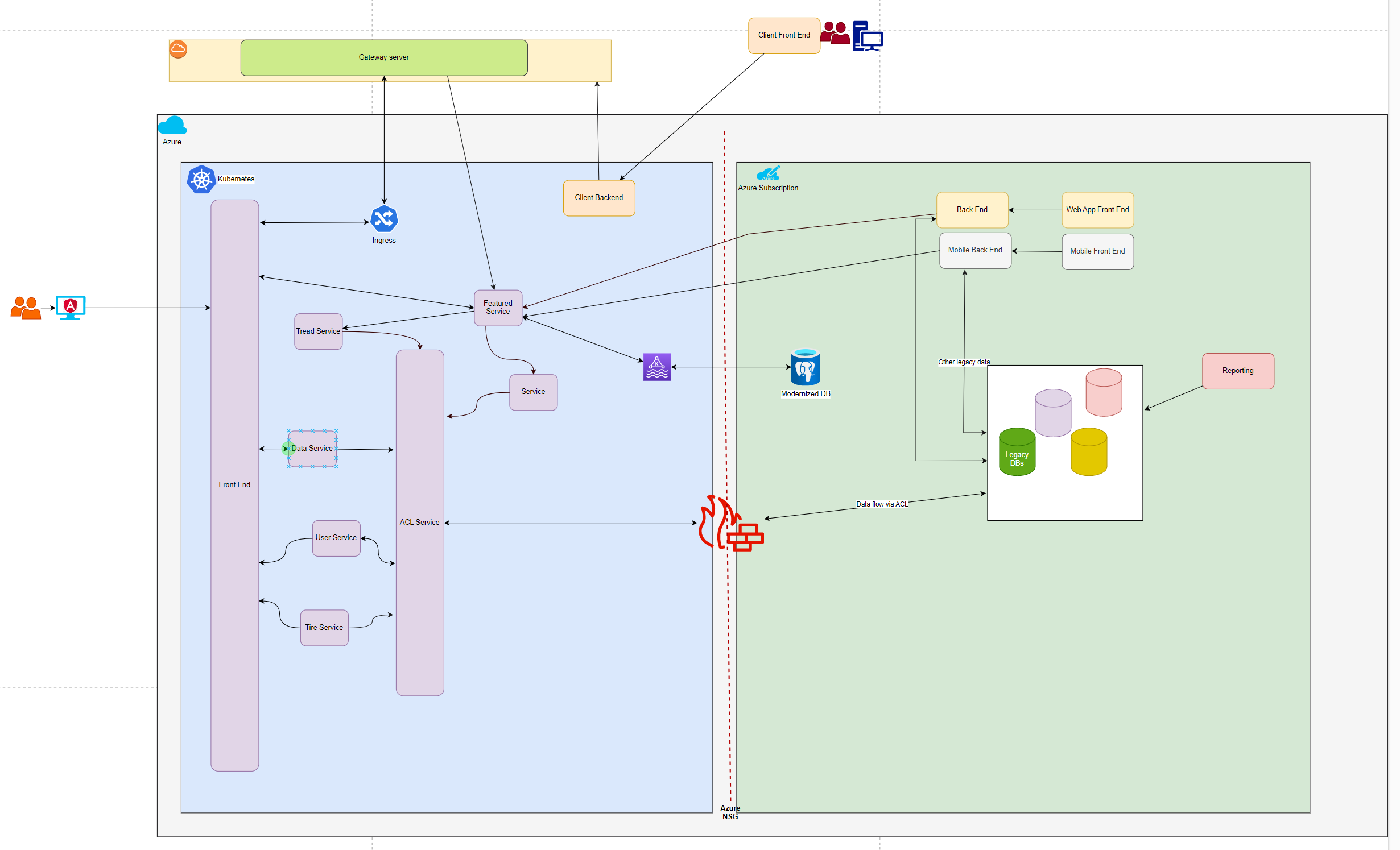
Architecture
Here is an example of our modernized architecture. Since we are using the Strangler Fig Pattern to migrate features over one at a time rather than using the traditional Agile Waterfall method, we are able to provide modern features to our customer sooner without affecting the legacy application.
The Strangler Pattern allows us to migrate over incremental functionality into a new modern platform which allows our team to get faster feedback from the user community. We are releasing the new functionality one small slice at a time instead of a big bang migration.
Lessons Learned
In our approach to use the Strangler Fig Pattern to migrate over features to our new microservices oriented application, we used an ACL for this Cam Service feature so that the user can view the data and edit the data on the existing legacy database in the new modernized front end.
Our plan was to migrate from the ACL pattern to microservices while we were working on the create Cam functionality which allows users to create new data via the modernized application. The ACL pattern would allow users to update existing data in the legacy database while keeping a new copy in the modern data schema. Once we migrated over all the data to the new schema, we could turn off the ACL. Sounds simple, right? Not exactly...
Most of the code that was written to pull data into the ACL included other static data tables such as tires makes, series and sizes including the existing Cam Product data that we were migrating to the new Cam Service feature. The ACL has rather complex code to merge the nine tables of data into the one record. The decision to put this complex code into the ACL versus a separate microservice could prove to be detrimental to our modern application and our timelines when we remove the ACL. We must carefully remove all the complex code from the ACL to a new microservice without affecting our customers. As of today, we still have the ACL in place but expect to remove it in the coming months.
Another lesson learned was about deciding when to own the data structures in the new schema. This was a rather complex decision.
- Do we experiment and see if we need to own the data when editing?
- Or when creating new data?
- Maybe we keep the ACL and migrate over data as it is edited or created?
- Or have a big bang migration to the new schema?
We decided to experiment and attempt to own the data at creation of new records. This decision has increased the time for our modernized application to own the data. Our ACL is now much more complex than the original solution. The time to remove this complexity will increase our timelines and ability to migrate over all the existing data to the new format. This was our first experience with an ACL and we learned that owning the data sooner might be a better decision to reduce complexity in our migration plans. In the coming few months, we will find out if owning the data at read or editing is truly a better decision.
We are continually working toward completing our feature. I'm sure we will continue to learn more about implementing an ACL as we continue to strangle the existing features into our new modern application.
Below is a list of further reading about an ACL that I referenced in the explanation in my article.
References for Further Reading




 Ahmed Shirin
Ahmed Shirin
