
Kubernetes Vanilla @ Michelin - Why? How?

{kind=link}

This article will retrace Michelin journey around containers and container-orchestration (Kubernetes) systems over the last 3 years. We believe that this feedback is interesting because we made strong choices from both a technical and an operational point of views.
First things first, why have Michelin invested efforts on such technologies? It may seem obvious but I think that this point is really important: I've seen so many cases where Kubernetes was overkill in comparisons to application requirements where efforts to use properly this kind of platforms did not justify the gains.
So, our journey started with a brand-new application with ambitious features but also strong requirements as it was involved in one of the core business processes of the company. To be honest, at that time we were not having the technical stacks in place to face the challenges and we thought that it was the right time to have a deeper look at THE buzzword: Kubernetes.
Why?
We quickly decided not to choose a Kubernetes distribution provided by a vendor but to invest on our own containers platform built on top of "Kubernetes vanilla" and here is a synthesis of the main drivers that led to this decision.
Market
Back in 2018, when we decided to have a look at the different alternatives, we quickly reached the conclusion that the market was still moving a lot (and the story showed acquisitions such as Pivotal, Rancher Labs, Docker or Red Hat) so we were a little bit afraid to bet on the wrong horse.
Expertise
To be honest, the market volatility was one aspect but not the only one. While we were sure that Kubernetes would play an important role in the future, we were also convinced that it was important to build an internal expertise around it in the company. What could be better than building our own platform to build this expertise?
Operations
Building a production-grade cluster (we'll come back on this later) is a good start but definitely not enough to manage a cluster's lifecycle. We need then to regularly upgrade clusters to the latest Kubernetes version, including all its underlying components, and all the additional components deployed on top of it. These day-2 operations are now mostly covered by editors but, once again, back in 2018, it was not so true and it meant to really understand the way all these components work together.
We also faced an uncertainty in the way a Kubernetes cluster behave in production regarding incidents and we wanted to operate it with internal teams to better understand its behavior in real life situations.
Integration in the existing ecosystem
Over the last years, Michelin has made strong investments invested a lot in 3rd party solutions for many domains like repositories managers, CI/CD tools or monitoring and logging. We wanted to benefit from our investments even with a brand-new Kubernetes solution instead of completely reinventing new workflows and impacting UX for teams.
Team organization
The Containers Platform team is currently a team of 7 people that are responsible of various activities around containers and orchestration topics
- Technological watch, studies, design of new features
- Automation of Day-1 activities (building clusters, deploying features, ...)
- Automation of Day-2 clusters (managing clusters and addons lifecycles)
- Support to development team
Day-1 activities
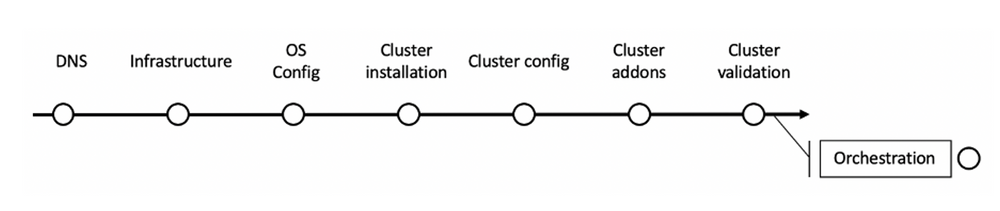
When talking about day-1 activities, we do the initial installation and setup process of a new cluster to make it completely operational in our context. It can be split into 7 different technical steps:
- DNS definition and configuration
- Infrastructure construction (network, storage, compute)
- OS configuration
- Cluster installation
- Cluster configuration
- Cluster addons
- Cluster validation
It is also important to get a glue between these 7 steps to get a complete automation of the Day 1 activities that we call the “orchestration” and that is basically all our CI/CD pipelines to ensure operations and actions consistency.
Day-2 activities
Day 2 activities are clearly the biggest part of the job of the CaaS (Container as a service) platform as it consists in maintaining a fleet of clusters in optimal operational and security conditions following all recommendations around our evergreen strategy.
It implies the following list:
- cluster components upgrade operations (OS, etcd, kubernetes, addons, ...)
- cluster components patching (etcd, api-server, controller-managers, ...)
- cluster scale out (adding new nodes)
- OS patching
- new projects onboarding / existing projects update
- cluster validation
- cluster security assessment
The cluster upgrade activities are a little bit complex because they do not mean upgrading the cluster only but also several transversal activities:
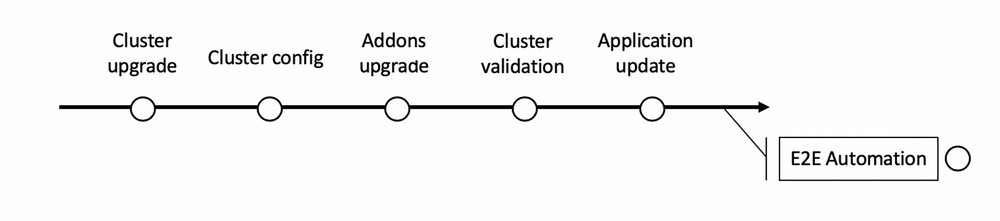
As shown on the diagram above, once the cluster is upgraded, we also need to upgrade components running on top of the cluster (as the monitoring stack, the authentication layer, the policy enforcement solution, the service mesh, …) and we also need to make sure that the applications are compliant with the new version of Kubernetes and when it is not the case, to inform the delivery teams about the breaking changes they need to address.
Support to developers
As a product team, we spend time on designing, building, deploying and maintaining Kubernetes clusters in several locations with different providers but to deliver a real value to the company, we also spend a lot of time to promote Kubernetes and containers usage accross our internal organization. This promotion can take different forms
- Documentation (Howtos, FAQ, presentation, trainings, …)
- Meeting with developers on specific topics
- Application support on demand
Figures
Our team is currently taking care of an heterogeneous Kubernetes ecosystem that is illustrated with the figures below
- 9 clusters (currently on Kubernetes 1.19.x)
- in 5 different locations
- and two different hosting types (Microsoft Azure and VMWare vSphere)
- 45 applications
- for a total of about 2000+ pods
Clusters
Our clusters sizes vary depending on their location and on applications needs but the smallest ones are composed of only 3 nodes and the biggest are made of 30 nodes.
They are not that big yet but it already represents a couple of hundreds of vCPUs for something around 3TB of RAM.
Applications
As all this technical stack was quite new, we decided, in a first step, not to widely open the platform to anyone but to target specific applications that were just starting so that we can make sure to get all the benefits of such platform by coupling Kubernetes capabilities to Cloud native applicative patterns (microservices architecture, stateless components to get multiple instance capabilities, ...).
Fault tolerance
After several months of production workloads running on our Kubernetes platform, what can we say about the promises of such platform regarding application resiliency, self-healing capabilities and finally the global system stability?
It is true, we faced several incident over the last months like node crashed or containers engine freezes but it did not have impact on the application layers. The major outage we had to face was the lost of one the availability zones in our Azure region (which was representing a third of our cluster compute capability) but, from an application perspective and as soon as applications embraced the right design patterns, everything went well and Kubernetes just did it job to reschedule everything on the healthy part of our clusters. Even if we knew that this was the expected behavior, it was quite impressive to see that it just happened and it went well for applications.
Up-to-date systems
We follow the Kubernetes releases and we migrate all our Kubernetes clusters and their underlying components every 3-4 months.
Technical overview
What does production-grade means?
Our goal was to deliver a production-grade Kubernetes platform. I already mentioned this "production-grade" before so let's clarify what it means for us.
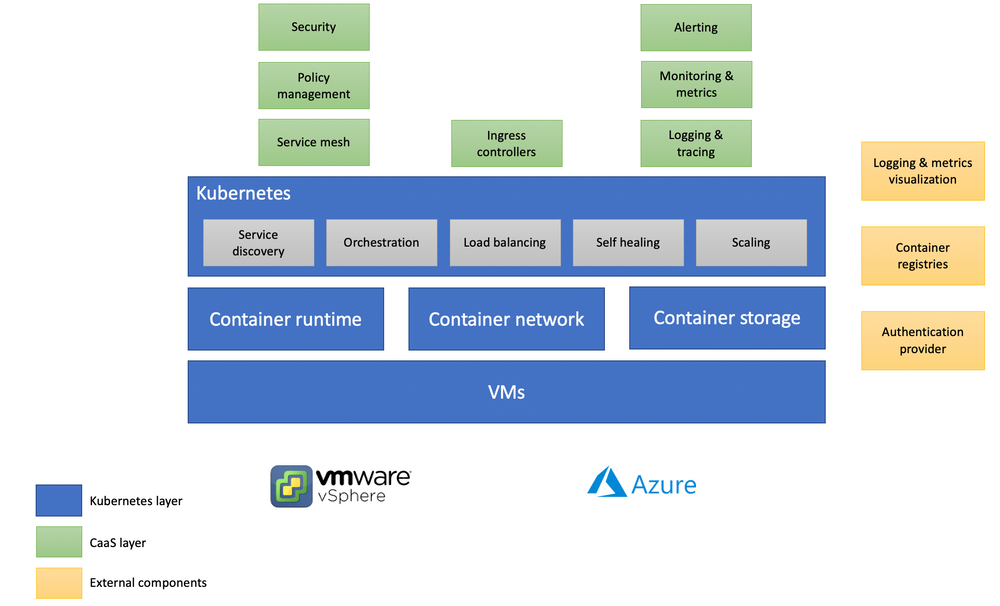
Kubernetes is highly flexible and configurable. It means that when deciding to install a Kubernetes cluster, you'll also have to make decisions with regards to
- OS (RHEL, CentOS, coreOS, …)
- Container Runtime (Docker, CRI-O, containerd)
- Networking model (canal, flannel, calico, …)
Once everything is clearly defined, you then install a cluster that is able to perform basic container orchestration operations. To reach the production grade, the following additionnal components must also be installed:
- Authentication with an OIDC provider
- Monitoring and logging solutions
- Security enforcement
- Policies management
- ...
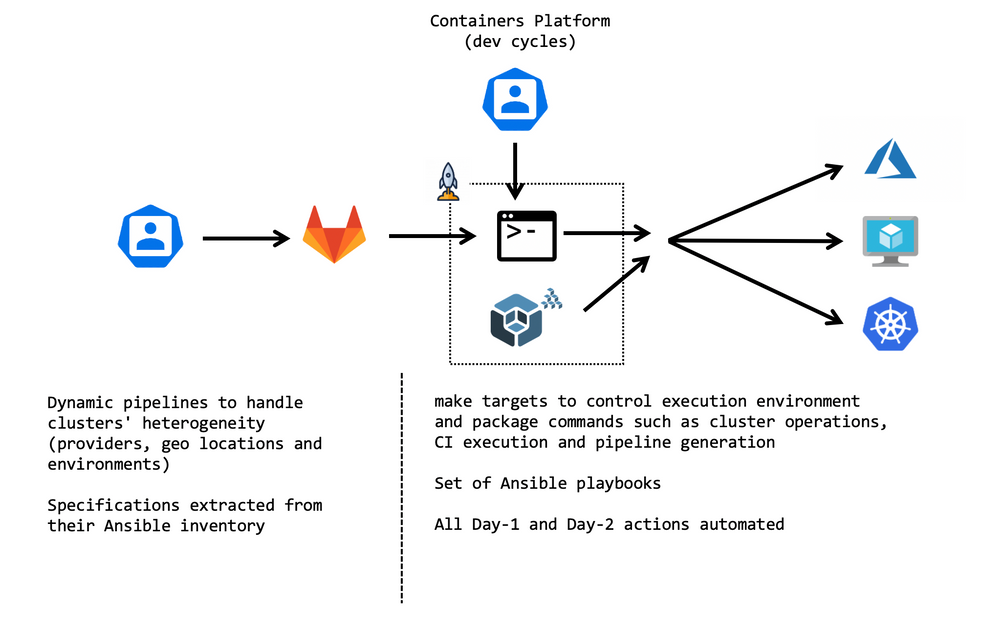
The following schema shows the different elements involved in our containers platform and illustrates what is explained above
How to build all these elements?
When designing our platforms, we had to keep in mind that we needed to be able to
- build (day-1) clusters
- maintain (day-2) multiple clusters and all their additional components
Kubespray
Obviously, we had to automate all these steps whenever it makes sense. So, we used an opensource installer as a base for all this named Kubespray (https://kubespray.io/#/).
Kubespray is a Kubernetes installer
- That can be used in any Infra targets (Azure, Aws, GCP, vSphere, Baremetal)
- Compatible with major OS distributions (RedHat, CentoS, UBUNTU, …)
- Highly composable (multiple network plugins, tons of options)
- Based on ansible (which was a good catch for us as we already had previous experiences and felt confident in it)
To illustrate this flexibility, we use the exact same codebase to create
- our clusters on Azure that deals with Azure native components like Azure Load Balancer
- on-premises clusters on vSphere, with HA-proxy load balancers and different architecture constraints
What we basically do with Kubepray is to regularly get the upstream updates and enrich its roles with internal ones in charge of installing and configuring different addons (authentication, logging, metrics, security, …)
Apollo

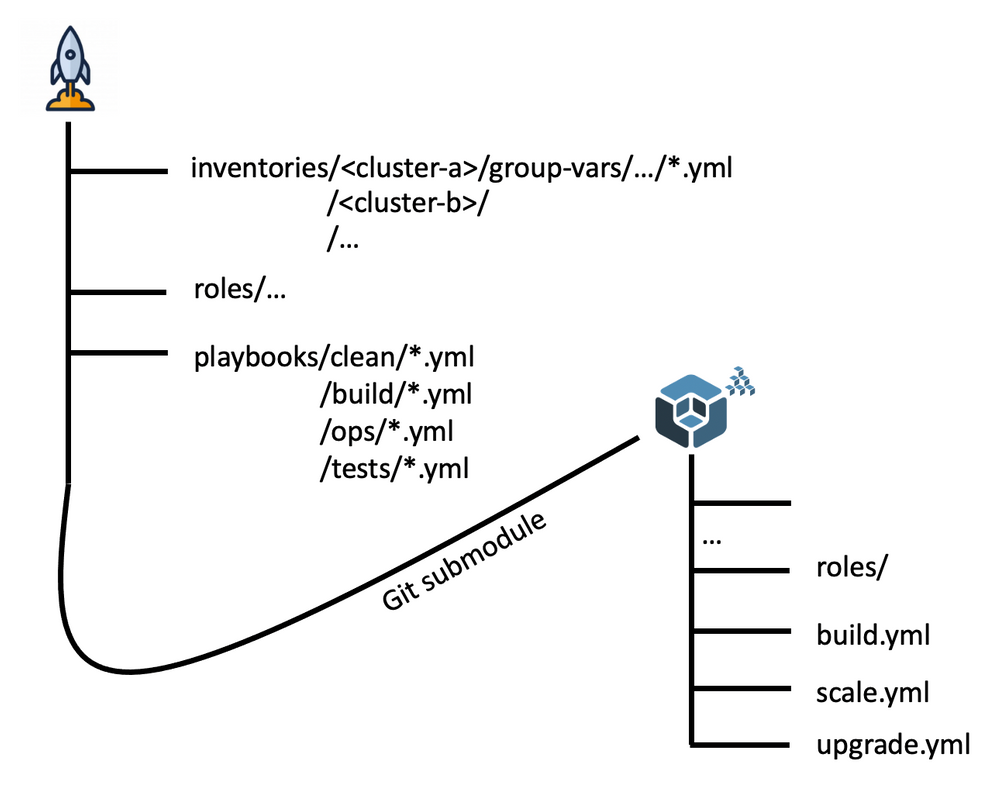
Atop of Kubespray, we created another project called apollo. This project aims at managing all the day-1 and day-2 operations (relying on Kubespray for some operations):
Apollo contains
- an inventory of all our clusters and their associated configuration.
- A playbook for each of the operation listed below
- Cleaning a cluster
- Building a new cluster
- Testing a cluster (all added feature, security compliances, …)
- Creating namespaces (and all associated resources such as network policies, quotas, rolebindings, …)
- Upgrading & scaling clusters
- Various administrative actions that we discovered by maintaining these clusters for 3 years in production :)
- Cleaning a cluster
- Makefiles with many make targets that we will describe in the next section
- A CLI module (a python module to be exact)
Here is the overview of the git repositories structure of the Ansible part of Apollo
Make
Each cluster operation consists in a subset of Ansible tasks to run against a cluster. All those Ansible tasks are located in a set of playbooks and their underlying roles coming from Kubespray and Apollo itself. One can select a subset of tasks by specifying one or more Ansible tags on the command line to give more flexibility across operations. Here is an example used to deploy or upgrade ingress controllers in a given cluster
ansible-playbook -i inventories/$(CLUSTER) kubespray/cluster.yml -b --tags=ingress-controllerOur day-2 ops are a combination of playbook(s) (often, one playbook call for one operation but some scenarios involve multiple ones) and tags to be played across one or multiple clusters. To improve readability and avoid inconsistency between our CI and our developement lifecyles (or adhoc actions that can also occur from time to time), all our day-2 ops are packaged as make targets so that the developer or the CI go through the same entry point to trigger an action. It eases the development of day-2 operations and its testing against our lab clusters. Morevover, it minimizes the risks of integration of those operations into our CI pipelines. Here are the different targets made available
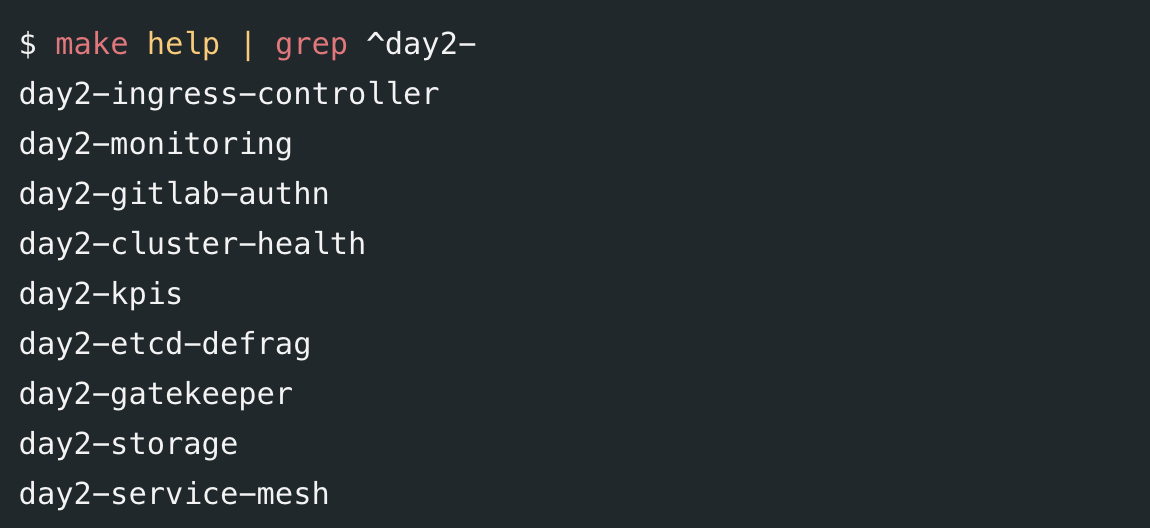
so the previous call is wrapped and can then be called as
make day2-ingress-controllers CLUSTER=cluster-aStraightforward, isn't it?
Gitlab CI
We rely on Gitlab CI for almost all operations we perform by leveraging all our playbooks and inventories through dashboards to clearly target an operation on a specific cluster or on a set of clusters.
To make all these dashboards available we are able to generate them on the fly through Dynamic child pipelines. It basically provides a way to dynamically generate the YAML file used for the child pipelines instead of relying on a static files. By this way, we always get up-to-date dashboards with appropriate actions available on bunch of targets without having to maintain a complexity on the Gitlab CI templates files each time we have to introduce new kind of operations.
To illustrate this behavior, the following screenshot shows how, for a given lab cluster, we can access a set of ad-hoc operations
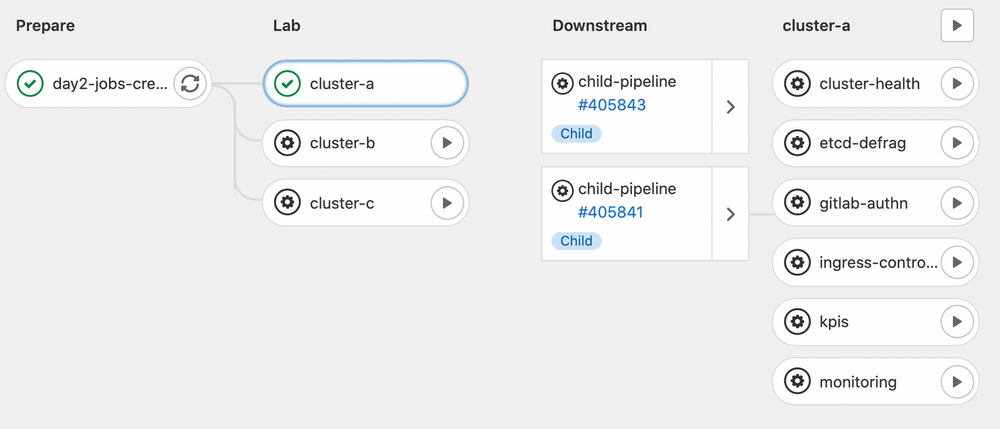
Global picture
Here is finally the global picture that illustrate the sections above
Conclusion
During this 3 years journey, we learnt so many things and especially that the vanilla model definitely helped us to build a real expertise around Kubernetes. We succeded in deploying dozens of applications in production-grade, always up-do-date and resilient Kubernetes clusters.
Based on these first successful experiences, new initiatives are starting:
- Applications replatforming towards containers
- IT Manufacturing modernization
These new initiatives are important drivers that will make us build and run clusters at scale. We hope that vendor solutions on Kubernetes are becoming mature enough and will improve our ability to manage efficiently and consistently day-1 and day-2 activities on a large number of clusters and applications so we could reconsider our positions this year on the future of our containers orchestration platform within Michelin.
The good thing is that we are confident to discuss and challenges those vendors based on our real life expertise around all the containers landscape.
Acknowledgments
I would like to warmly thank Mathieu Mallet and Mickaël Di-Monte for their careful proofreadings.