
How Michelin Innovates Through Its Computing Power

{kind=link}

Co-authors : André Devillars, Vivien Clauzon & Pierre Borel
History of Scientific Computing at Michelin
Michelin's history has been based on innovation since its creation in 1889: the use of rubber on carriage wheels, the detachable tire, the radial tire, the low rolling resistance tire, and by extension, high-tech composite materials: belts, seals, conveyor belts, track systems, etc.
A tire is a complex assembly of about 200 components (natural and synthetic rubber, textile and metal cables, chemical agents) organized in layers. The nature, size, and positioning of these layers in relation to each other, combined with the final tread pattern of the tire, ensure the functional characteristics of the tire: comfort, noise, endurance, road holding, grip, rolling resistance.

The challenge for tire manufacturers is to simultaneously master the improvement of one or more of these functional characteristics while minimizing the impacts on others and maintaining control over this performance compromise. This constant search for compromise requires a very fine understanding of the physico-chemical structure of the material and the mechanical interactions of the different components with each other and with the ground.
To meet this challenge, engineers must first thoroughly analyze the behavior of materials under various conditions. Physical tests, although essential, have significant limitations: they are costly, time-consuming, and only allow the exploration of a limited number of configurations. This is why the virtual approach becomes complementary.
Predicting tire behavior requires the ability to mathematically represent complex phenomena: non-linear deformations, interactions with different types of surfaces, and behavior in extreme conditions. The equations governing these phenomena are often impossible to solve analytically. Moreover, the simultaneous optimization of multiple interdependent parameters requires rapidly exploring a vast space of potential solutions, which would be unachievable through experimentation alone.
It is in this context that modeling and high-performance computing (HPC) become strategic tools. They allow the visualization of phenomena invisible to the naked eye, virtual testing of thousands of configurations, and significant acceleration of innovation cycles while reducing development costs.
This is why, to stay at the forefront of innovation, we have been using our own high-performance computing infrastructure for over 35 years and developing our own calculation codes, which we continue to evolve on our various generations of computing infrastructure.
Given the privacy concerns, all our high-performance computing has historically been done on our own data centers, located at our main research centers (France, USA, Japan), operated by Michelin personnel, and with specific security measures.

Inflections, drivers
At company level, we are facing an increasingly demanding environment, whether in terms of customer demands, the economic context, or the regulatory framework. This results in an increased need to accelerate the market launch of a greater number of products following new innovative manufacturing processes that are more environmentally friendly (bio-based or recycled materials) while ensuring compliance with an ever-increasing number of quality criteria.
This acceleration is not sustainable without a new phase of digital transformation from the design of our products to their manufacturing with a direct impact on the volume and complexity of the calculations we will have to support on our data centres:
- Establishing digital continuity between the different applications of research and industry to accelerate data flows and processing.
- Industrialisation of digital twins and virtualisation of test stages.
- AI-assisted design of our products.
- Seasonality of calculation campaigns, deadline constraints.
How we respond
We have built an HPC strategy that allows us to accommodate the strong increase in the number of calculations, the unit complexity of each of these calculations, the emergence of strong seasonality, while also ensuring the strict need for sovereignty over a large part of these operations.
- Consolidate our on premise capacity for stable workloads
- Offload peaks and GPU intensive workloads to sovereign clouds
- Reengineer the calculation chain : more autonomy, better agility
Seasonality is the situation where we see a temporary but strong increase of the number of calculation requests due to a single use case. If it occurs from time to time, it is acceptable, but with more and more asynchronous occurences of similar use cases, it will start to impact strongly the operations of your entire HPC farm. You can of course add more capacity, but capacity is costly and you do not want to use it only during peaks. At Michelin, we decided to better identify our seasonality patterns and build an offload strategy .
Here is a common seasonality requirements we increasingly encounter :
Finite Element Analysis (FEA) provides highly accurate simulations but is often slow and computationally expensive. By generating a high-fidelity dataset through FEA and training an AI model on it, we can create a system that delivers near-instant results with similar accuracy. This approach enables engineers and researchers to make rapid, data-driven decisions without the need for time-consuming simulations. But to build these trained models, you need a large number of computations and because you need to retrain the models on a regular basis, you end-up generating a seasonality pattern.
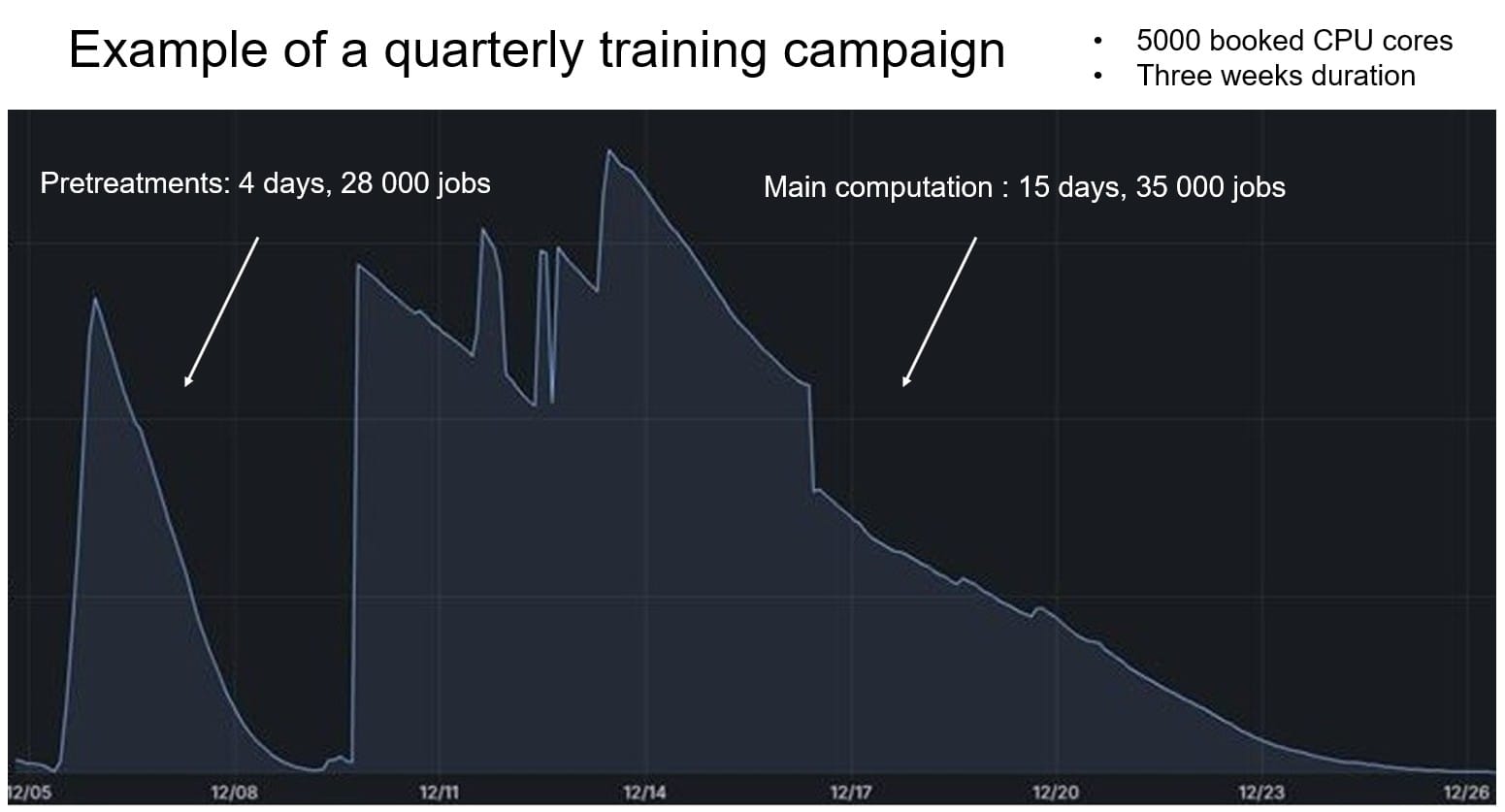
Initially, we agreed that we could no longer limit ourselves to our own computing capacities: we have the people and the skills to manage our current HPC data centres over the long term; however, beyond a certain scale, the needs in surface area, electrical power, and cooling system go beyond our business strategy. This finding has been further reinforced since the rise of GPU computing, as managing all the constraints of more than a few dozen cards becomes difficult in day-to-day operations.
We have therefore initiated the reflection on external capacities usage, sovereign in terms of intellectual property. Given the company's history, always very concerned with the protection of its secrets, this proposal raised a deep questioning and required validation at the highest level of the company and within operational teams.
The proposed strategy has been eventualy accepted by Michelin's management and the first external computing capacities are in place, based on French private and state actors. It allows us to offload seasonality requests or use large GPU capacities for our numerical simulations
In parallel, we have launched four initiatives:
- Acceleration of investments to double and saturate our own computing center, keeping it up to date with state-of-the-art CPU architecture and new nodes.
- Sizing and deployment of GPU capacity to anticipate the arrival of generative AI (LLM and RAG) on this sovereign perimeter.
- Optimisation of our solver and our calculation chain to increase productivity.
- Transformation of our calculation chain to make it agnostic of the necessary computing resources and give us all the flexibility we need, to, on demand, calculate on our own means or send all or part of the calculation to a sovereign and externalised HPC cloud.
And what's next?
For the future, we are developing our HPC thinking along three main axes:
Increase our innovation power while reducing time-to-market cycles
While the current inflections are based on known research and industrialization elements, the next inflection will also be based on topics currently under analysis, for which we will seek to go even further to continually improve the overall performance compromise. This will naturally make individual calculations more complex and thus more resource intensive.
To this unit complexity will also be added the volume of calculations and the strong seasonality of demand linked to the increasing use of AI learning techniques and generative AI needed to reduce our design cycles. Finally, this increase in complexity will also spread to the entire digital continuity of our product design chain.
It is not easy to define the extent of the impact this inflection will have on our algorithms and HPC infrastructures by 2030, but it is certain that the impact will be significant, requiring us to use even more GPU calculations and rely mainly on resources external to the company.
Anticipating the arrival of Quantum Computing
Quantum Computing carries a very significant potential in computing power, even though its implementation remains hypothetical within five years. The complexity of some of our simulation needs already leads us to have calculation times of several weeks, and the trend is towards ever-increasing complexity in the coming years.
It is therefore likely that within ten to fifteen years, the duration of some calculations may severely hinder our innovation process. Either the calculation will simply be infeasible with CPU/GPU technology, assisted or not by artificial intelligence, or it will be too long and incompatible with the needs for accelerating the time-to-market of our products.
Will Quantum Computing be a response to this potential slowdown in our ability to innovate?
We believe so, and that is why, given the breakthrough that Quantum Computing represents for our teams, we have launched a cultural initiative two years ago: in 2023 and 2024, we participated in conferences, training sessions, consulted the ecosystem, and selected our first research avenues. In 2025, we are launching the first experiments by collaborating with the academic world (internships and theses) and French startups (collaboration on disruptive business topics).
Managing uses, their financial value, and their value for the planet
Just as today, in a physical world, we offer finite means of experimentation, prototyping, and testing to our product designers, we will transpose these means into the digital world; however, there is no reason why the transition to digital should be done while losing sight of the profitability of the resources made available or the fact that these HPC, AI, and future Quantum infrastructures have financial and environmental impacts that must be evaluated in light of the gains they will enable.
Simply put, we need to use the algorithmic advances that data science and AI allow us to simulate only the interesting operating points and thus ensure that computing resources are used wisely.
Conclusion
In summary, we are continuing a period of strong growth in our use of intensive computing on current technologies: CPU/GPU, emerging: AI/ML/Gen AI, hypothetical: QPU.
The time has come to scale up these computing resources, enabling our users to fully leverage them autonomously in the design of our products.
It is also the time to ask ourselves questions about the environmental and financial impact of intensive computing, the potential rebound effects, and consequently deploy new tools and methods that will allow us to demonstrate the value that intensive computing continues to bring to innovation within the company.