
An introduction to Datalog
A rule-based data query language that thinks differently

{kind=link}
Modern IT systems manage an increasing amount of data, sometimes bound by sophisticated models, that require specific representations of the same information in order to perform translation between various software layers
As consequence, software developers have to provide descriptions in data and constraints/relations of these systems, this is what we call data-models
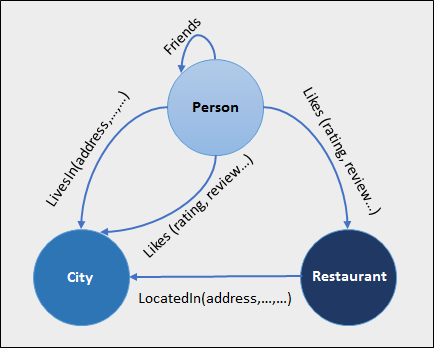
Not all the data-models are the same, one criteria we can use to differentiate them is the kind of relationships between the objects
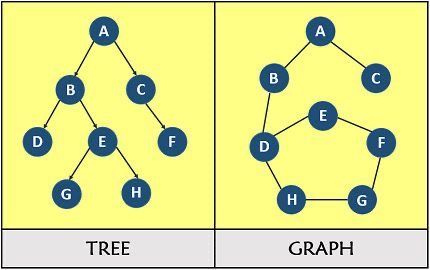
- Models with one-to-many relationship ( aka "tree-like" )
- Models with many-to-many relationship ( aka "graph-like" )
The one-to-many relationship can be modelled using a tree structure which can be easily represented using the JSON data language
On the other hand, representing many-to-many relationships leads to design decisions in how to represent the data : in other words, a conditional expression of some edges and vertices.
Thus, the technical choices made on the data modelling aspect of software design will affect the system behaviour, its overall performances, as well as the efficiency of the tools that support it.
We have different needs to view the same data, with relationships expressed in different ways
Therefore, it becomes essential to leverage methods to provide different views of the same data model depending on the need, whether for visualisations at the presentation layer or for specific business processes use-cases.
Additionally, it is often required to express these views in the declarative form of a Data Query Language (DQL) in order to make it user-friendly and later adaptable (as opposed to hard-coded functions).
This is where the datalog programming language comes into play.
About Datalog
Datalog is a declarative query language, derived from Prolog.
Its logic is based on first order logic and more specifically logical clauses expressed as Horn clauses.
Its origins date back to the beginning of logic programming, and is often being used to describe systems, or to build domain models.
It can be used in many different ways, including to:
- query data from one system to another
- model data in terms of relations between entities
- create new data models with minimal code
Moreover, Datalog can be written in Extensible Data Notation (edn) which is a data format that can be used in programming languages such as Clojure.
Take a look at XTDB or datascript if you want to get more details about implementations based on edn format
Datalog can be used to query data stored in a relational structure, or other types of data sources, for example, graphs, XML files, text files, or in-memory data-structures.
Furthermore, it is used as a primary query language by the database datomic.
How does it work ?
A datalog program consists of a list of facts and rules, using the two following elements of syntax
- Predicate patterns :
[(predicate identifier)] - Data patterns :
[<entity> <attribute> <value>]
When used as a query language, a datalog program may be seen as
- A set of variables
- A set of rules ( rules can be recursive )
- A set of assertions combining those rules
We will be using here a specific datalog implementation called datascript, which is based on Clojure and edn format, and provides the following opportunities:
- Facts and rules use a native Clojure data format
- Queries can be built programmatically
- Parser does not require any specific API
- Queries can be inspected as native data structures
A basic query statement would be declared this way
[:find <entity>
:where
[<entity> <attribute> <value>]]The :find statement will retrieve all the entity that satisfy the data pattern defined in the :where clauses
A concrete example, looking for a "Person" entity having an attribute "first-name" with value "John"
[:find ?person
:where
[?person :first-name John]]Note here the value of the :where clause pattern is expressed as a static constraint.
However values can be bound to a symbolic variable that can be used as entity identifiers in order to specify the value returned by the query
[:find ?name
:where
[?person :first-name ?name]
[?person :lives-in Paris]]The symbolic variables can also be used to join different entities together
[:find ?name
:where
[?person :first-name ?name]
[?person :lives-in ?city]
[?city :located-in France]]The ?city variable binds the "Person" entity to "City" using the "lives-in" attribute
Note the joining logic could also be expressed as a separate rule, then used in a query
[(lives-in-country ?person ?country)
[?person :lives-in ?city]
[?city :located-in ?country]][:find ?name
:where
[?person :first-name ?name]
(lives-in-country ?person France)]Note that rules may contain any predicate based on native functions of the implementation language
[(lives-in-country-whitelisted ?person ?country)
[?person :lives-in ?city]
[?city :located-in ?country]
[(contains? #{"Paris","Lyon"} ?city)]]This opens up a wide range of opportunities for pattern matching.
Advanced Example
Let's take a more advanced example to demonstrate the use of datalog as a query language.
Consider the below data-model, having a recursive relationship "parentOf" between the objects of the "Person" entity
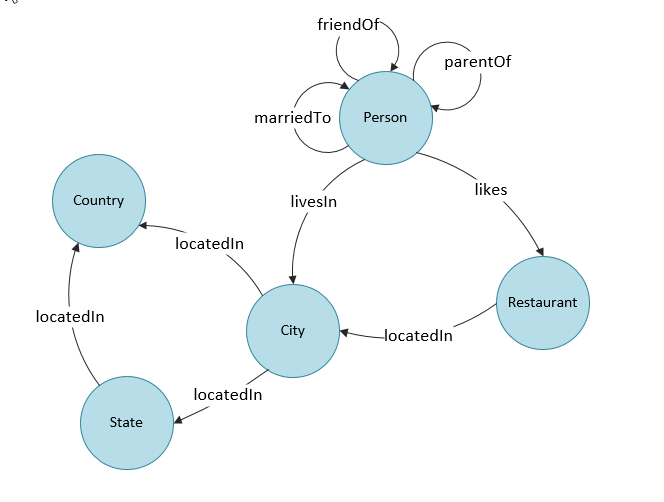
Here is the way one would describe the "Person" entity in a relational SQL database:
create table person (
first_name text,
last_name text
);The same entity could be described in datalog using edn format:
[(person ?person)
[?person :person/first-name ?f]
[?person :person/last-name ?l]
[(string? ?f)]
[(string? ?l)]]Let's now focus on the parentOf relationship between objects of the "Person" entity.
The query to get the first-level parents of a Person in SQL is as follows:
select from person p1
inner join person p2 (p1.parentOf = p2.id)
where person.id = person_id;Note the logic that resolves the links between objects is nested in the query.
See below the very same query using a datalog program
[:find [?p1 ?p2]
:where
[?p1 :person/id ?person]
(parent-of ?person ?p2)]
;; rule definition
[(parent-of ?person ?parent)
[?p1 :person/id ?person]
[?parent :parentOf ?p1]]Here the parent-of relation is expressed as a datalog rule, that is used in the querying code block [:find :where]. This syntax brings separation of concern between modelling and query code
The concept of rule definition can event be taken a step further by resolving multiple levels of the "parent-of" relation.
[:find [?person ?great-grand-parent]
:where
(genealogy ?person ?parent)
(genealogy ?parent ?grand-parent)
(genealogy ?grand-parent ?great-grand-parent)]
;; rule definition
[(genealogy ?person ?ancestor)
(parent-of ?person ?ancestor)]
[(genealogy ?person ?ancestor)
(parent-of ?person ?ancestor-1)
(genealogy ?ancestor-1 ?ancestor)]Here the "genealogy" rule combined with "parent-of" rule brings a fully recursive method, that is used here to get second ranks ancestors "great-grand-parents"
Designing the same recursive request in SQL using recursive Common Table Expressions would be way more complex, difficult to read, and so hard to maintain.
At last, see below an example of a query with multiple joins over several entities.
[:find [?person]
:where
[?person :person/likes ?restaurant]
[?restaurant :restaurant/type "pizzeria"]
[?person :person/lives-in ?city]
[?city :city/country ?country]
[?country :country/code "FR"]]Notice how it is easy to get all the people that live in France and like Pizzas!
A good alternative to SQL ?
Obviously the default data language nowadays seems to be SQL, although it has many elements derived from Datalog.
However, Datalog has two main advantages over SQL ; it has cleaner and simpler semantics, which facilitates program understanding and maintenance, as well as communication within the organisation.
Datalog requires a different way of thinking, but it is a very powerful approach. Rules can be combined and reused in various queries, and it handles complex data structures much better.
In particular, for recursive queries or fixed-depth graph exploration, where datalog is much simpler than SQL, although the recursive Common Table Expressions have been recently optimised in modern database engines to cater for real-life scenarii.
What about NoSQL ?
It should be remembered that SQL is not a "go-to" solution for data querying in every situation. There are a variety of different query languages and frameworks that are tailored to particular data types, making them superior options for querying specific data structures.
For example to query graph data, the database default languages generally are de-facto the best options to consider, we can mention:
Datalog is not intended to replace these database specific languages, and will rather find its value in providing graph querying capabilities on relational databases having semi-structured fields of json or xml type.
Past and Present Limitations
We saw the datalog approach is powerful, and can handle complex data with minimal code.
That is said, there have been some historical limitations, and current restrictions, that might prevent people from including it to a technical stack.
- Compatibility : even if datalog is quite old, not all programming languages provide support for this technology, even if some are currently working on it
- Performances : datalog has not became mainstream because of recurrent performance issues, however almost all of them that have been solved in modern database engines
- Competencies : although datalog is easy to learn, not many people have even heard about it, logic programming does not carry so much hype nowadays

Where to use It ?
Datalog is a fantastic option when dealing with semi-structured data, where different representations of the same data are needed based on the business context.
Moreover, it works incredibly well within a data-centric approach based on the Clojure toolset, composed of language and libraries, a well as the EDN format to represent data structures. See my previous article Bringing Clojure Programming to Enterprise for reference.
In a future post, I will discuss a specific implementation of datalog to address issues with data translation between business domains, inside the scope of a manufacturing referential system.
I hope these few words have piqued your interest in this amazing language.
Happy data querying ! ❤️
Further readings
- First order logic (FOL ) and logic programming
- Designing Data-Intensive Applications
Links
- Datascript : https://github.com/tonsky/datascript
- Datalog : https://en.wikipedia.org/wiki/Datalog
- XTDB : https://docs.xtdb.com/language-reference/datalog-queries/
- Clojure-Datalog Databases : https://clojurelog.github.io/
- Learn datalog : http://www.learndatalogtoday.org/
- Logic programming: https://en.wikipedia.org/wiki/Logic_programming