
Ensuring data consistency in a micro-service application

{kind=link}

A few years ago, we had to rewrite an old mainframe application, used by a few thousand people. The application was known (or believed) to be fast, reliable and almost bug free. To maintain the level of service we chose a micro service architecture for the new solution, which means that we had to split the functionalities of the application into different parts, or services, that collaborate. But it came with some unexpected challenges. One of them is the difficulty of ensuring data consistency.
The problem
In a monolith application things are simple. If you care about data consistency, then you just use ACID transactions. This ensures that the transaction is:
- Atomic: it is entirely done or not at all, never partially
- Consistent: the database goes from one valid state to another
- Isolated: there is no interference between transactions
- Durable: all committed data is permanent
In a micro-service application transactions exist but they are limited to the boundaries of each service. Which means that at least atomicity, consistency and isolation are lost.
Let’s take an unrelated example. Imagine you want to implement a shopping application. You might have a payment micro service and an inventory one. When someone buys something, you want to reliably register the payment and their order. You do not want to remove the item from the inventory if the payment is not registered and you do not want to register the payment if the item is not available anymore. Basically, you want ACID properties for the whole process. So, you need a way to synchronize the two micro services. (Yes, you might agree to relax the conditions, and send a cancelation to your customer, but for the sake of example this is not possible here).
One solution is a two-phase commit, which works by starting two transactions in each service, one transaction nested in the other, commit the inside one and wait for the completion of the other service to commit the top-level transaction. It is reliable but heavy, and one of our objectives was to have good response times. Another way is to accept to temporally have dirty data , that is inconsistent, and ensure eventual consistency, i.e. correct them at some point.
Our problem was also a bit simpler, as we had an asymmetric relationship between our services. We have two services, let’s call them A and B, when we want to create an object in the application, we query B that queries A. This ensures that the part of the object that is in A is always there if the part is also present in B (since B creates the data only if it received a valid response from A), however A is never sure that B has done its work correctly and might have a partial object with some kind of dangling reference to B.
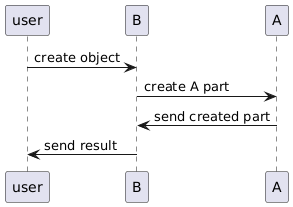
The solution
The solution we chose is to “repair” asynchronously the data. This is acceptable because we are sure valid data have been processed correctly, we only have to deal with partial data.
When A creates an object, it marks it dirty (that is just a flag in the database, it does not have any consequence for the application, it is possible to query dirty data). When B has finished its work it sends another message to A to inform it that the object is correct, and A removes the dirty flag.
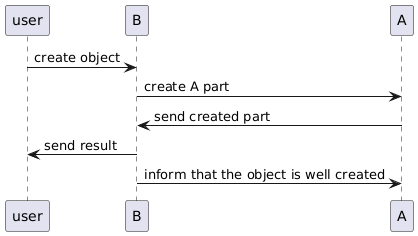
Now this process can fail at multiple points. The first one is that B never receives the answer of A. The object will therefore not be created correctly and stays dirty. The acknowledgment of B can also never be received by A, despite the object being correctly created, and therefore the object also stays dirty. The failures before data creation in A are handled by a simple failure of the whole process, as no data is ever created.
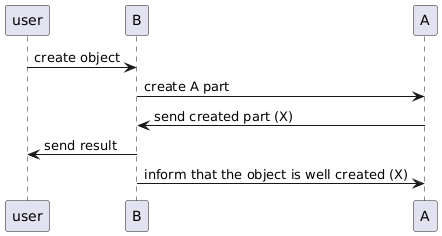
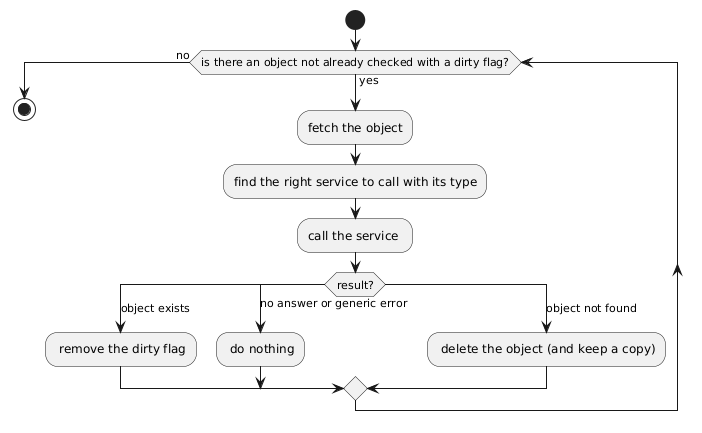
The second step of the algorithm is to deal with dirty objects. Each hour a scheduled process in A scans the dirty objects and calls B to check if the object exists. At this point there are a few possibilities:
- The object does exist in B, then A removes the dirty flag on the object
- B does not answer, or send an (http) error (500 for instance), we cannot conclude whether the object is correct or not, A does nothing and goes to the next dirty object
- B does not know the object, then the object is really dirty, A deletes it (and for traceability reason keeps a copy in a dedicated table)
Eventually all the dirty objects are deleted, and all the correct ones lose their dirty flag. The weakness of this algorithm is that we never know when it will happen (in the best case it is a matter of one hour), because of potential errors in the scheduled process (second case).
This process can be repeated on multiple steps, if necessary, for instance with a three-step chain, in that case B will need to flag the objects and have the same process.
To make things more flexible and evolutive the link to B is not known in the code of A, instead a configuration table informs A where to check depending on the type of the object. Each object has a “type” field, and for each type there is an entry in the configuration table that gives the path to “get” the object.
This process can be prevented if the data is not shared between micro services, which is the best design, but it is not always possible. This also means that the choice of a micro service architecture has important consequences that must be considered, this architecture is more complex by nature, and it is important to weigh the advantages and the drawbacks.
Preventing concurrent editing
Another issue, that could also arise in a monolith, is concurrent editing, when two users open the same object. Of course, the application is capable of saving the data of both the users, but the result is unpredictable from the point of view of the users, and it could lead to some kind of data loss. If two users edit the same fields for instance, one of the editing will be erased, and we cannot predict which one. The problem is also linked to the fact that the user has a temporary view of the object in its web browser and does not see the modifications of the others.
To prevent this, we added an edit version on the objects. Each time an object is modified this version is increased. To be able to edit the object, the last known edit version must be sent with the modification, if there is a difference between that version and the one in the database, it means that the object has been modified between the last read and the modification. The editing is thus rejected, and the user is invited to reload the data. This is called optimistic concurrency control.
For this to work, the checking and potential increase of the edit version must be atomic, therefore it must be done in one service, in a serializable ACID transaction.
If the edit version is shared between multiple endpoints or services, it requires the queries to be done sequentially which is less performant, a solution is to have different edit versions for each part of the object or each service, it must be adapted to the use case.
Possible improvement
The scheduled process can be entirely deleted if we have a reliable way to send the acknowledgment of creation from B to A. Fortunately for that purpose we can use Kafka. The algorithm would be modified: B would send a message in a Kafka topic to inform A that the object is well created instead of calling A. instead of having a scheduled process, A would simply listen to the topic and remove the dirty flag once it receives a message. All the error would be taken care of: if A is not available the messages are stored in Kafka, and A can consume them later, and the messages cannot be lost. This is still eventual consistency as we cannot predict when the message from B will be read, but we are sure it will. This would also reduce the coupling between the micro services.