
Integrating multiple HPC schedulers with a web platform

{kind=link}

Providing High Performance Computing as a service
R&D and simulation
Michelin’s HPC (High Performance Computing) clusters run thousands of computations each day.
Hundreds of people, whose job is not related to IT, have to familiarize themselves with command line syntaxes and scripting, in order to use these clusters that have become necessary to their daily work. These are mechanical engineers and tire designers that use simulation to estimate the performances of the tire lines of tomorrow.
In 2014 we started a project aiming at facilitating access to our simulation tools and its supporting infrastructure. We developed a platform that allows our users to make use of advanced and complex simulation patterns without having to learn the IT nitty-gritty.
One of the challenges that came with this project was the integration of the HPC schedulers with our solution. This is what we will be discussing here.
Our goal was to provide access to the computing power of Michelin through an abstraction layer, that we will call the scheduling middleware:
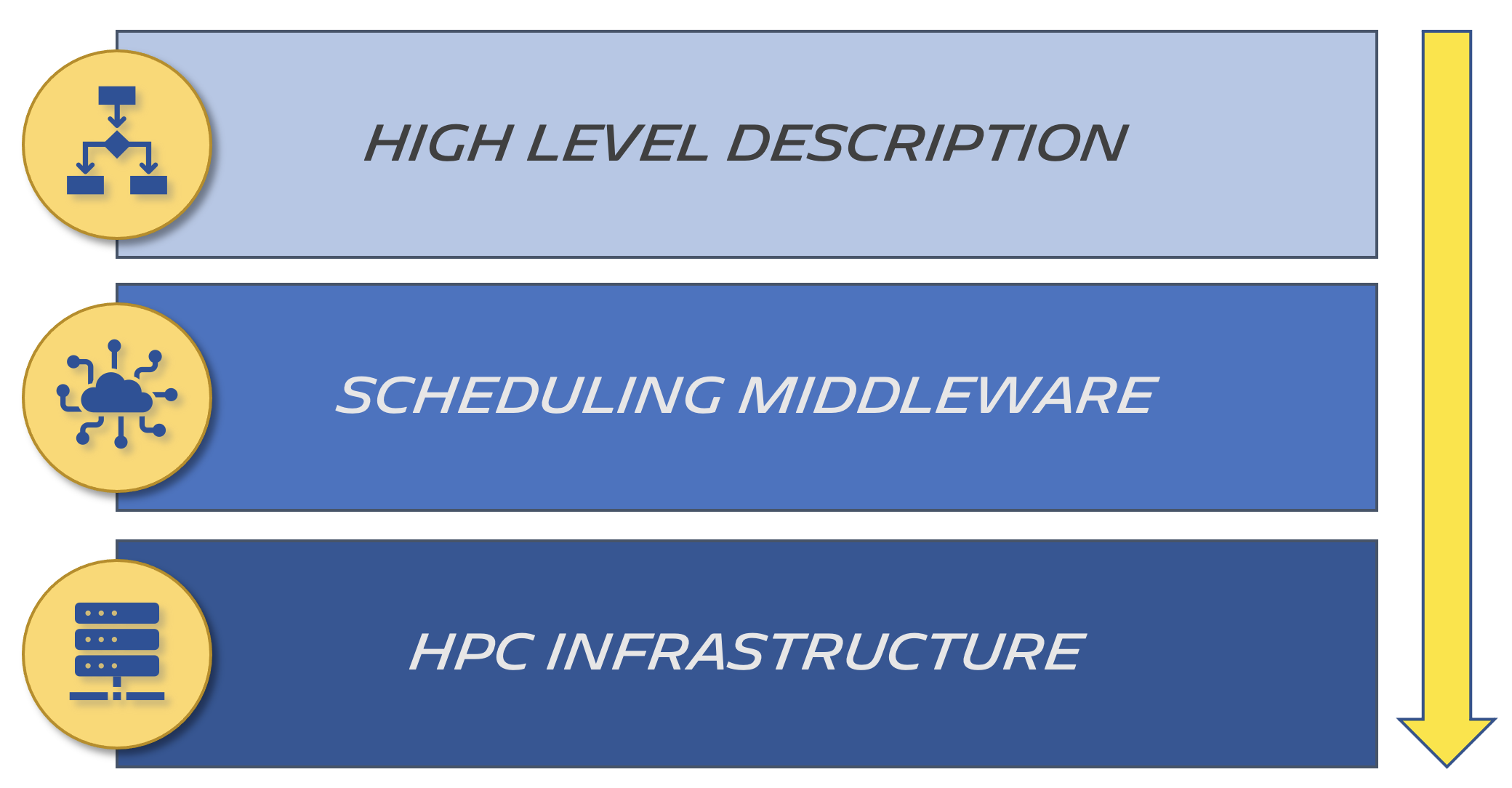
The HPC infrastructure is split between two job schedulers:
- IBM's LSF (Load Sharing Facility)
- Oracle's SGE (Sun Grid Engine)
A job scheduler has control over a pool of machines, and distributes tasks (the jobs) on machines that are free. When no slots are available, it queues the jobs and can handle prioritisation based on parameters like the number of jobs submitted by the user over a certain period of time (favouring people who request jobs once in a while over power-users that launch hundreds of them at a time).
Scheduling 101
A simulation can be seen as a chain of steps. Each step executes commands in a specific order.

Each element of this chain has certain requirements in terms of:
- Memory usage
- Computing power
- Data it needs to access

This means that running the entire chain on one single machine would be inefficient. It would need to be scaled to accommodate the most RAM-hungry or CPU-intensive element. This would be wasteful when running elements that cannot make use of these resources. In the meantime, you would also need to have that single machine access every piece of data required for the whole chain. This can prevent you from making sound decisions on how to store this data, as well as leading to security issues.
Another added benefit of having a problem made up of small pieces with specific requirements rather than big ones, is that you can get closer and closer to 100% resource usage on your cluster (basically the holy grail of cluster management):
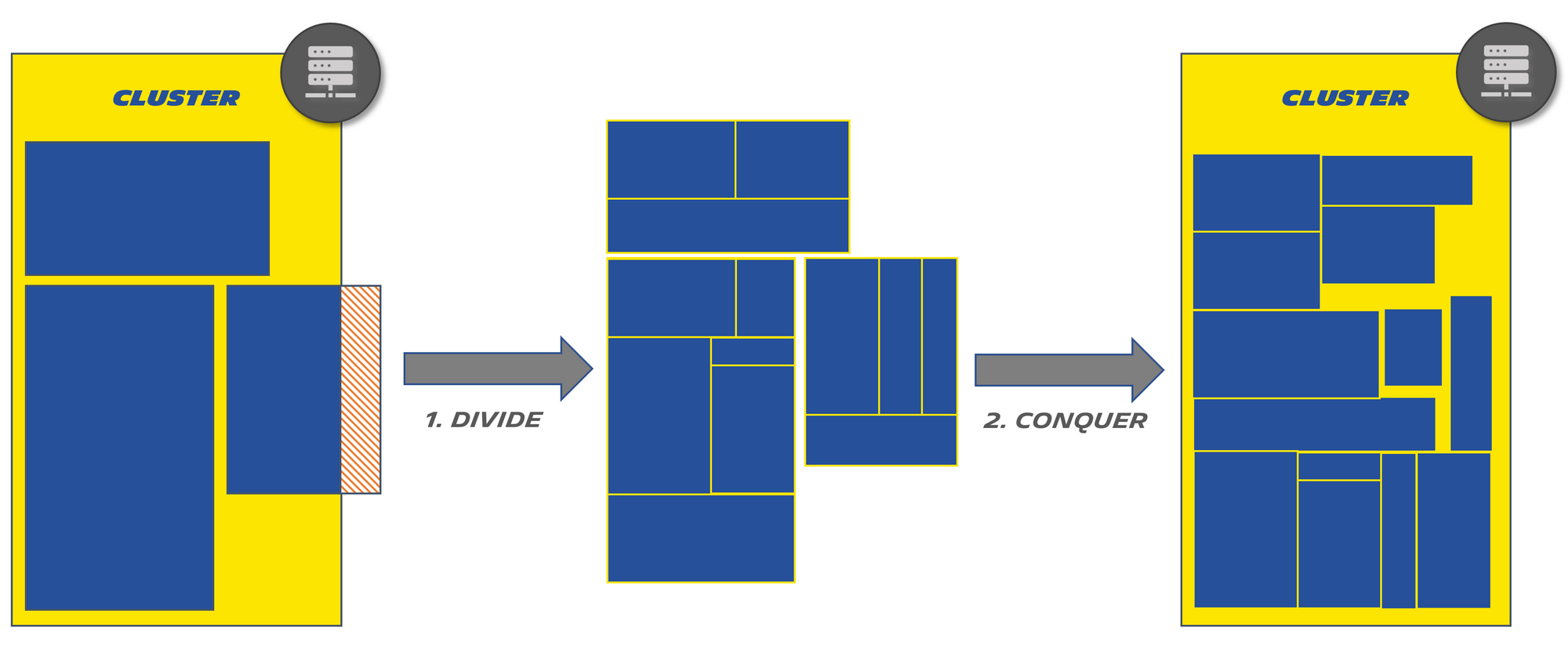
High level description
The framework we developed to write simulations provides a high-level description of a step complexity. It combines a targeted scheduler (LSF or SGE) with a problem size (e.g small, medium or large).
Each scheduler has queues defined by the sysadmin (we will use 1H, 1D and 1W on each of them for our example).
The two parameters are translated by our scheduling middleware to target the appropriate cluster queue (each queue has time limits and differs in allocated resources):
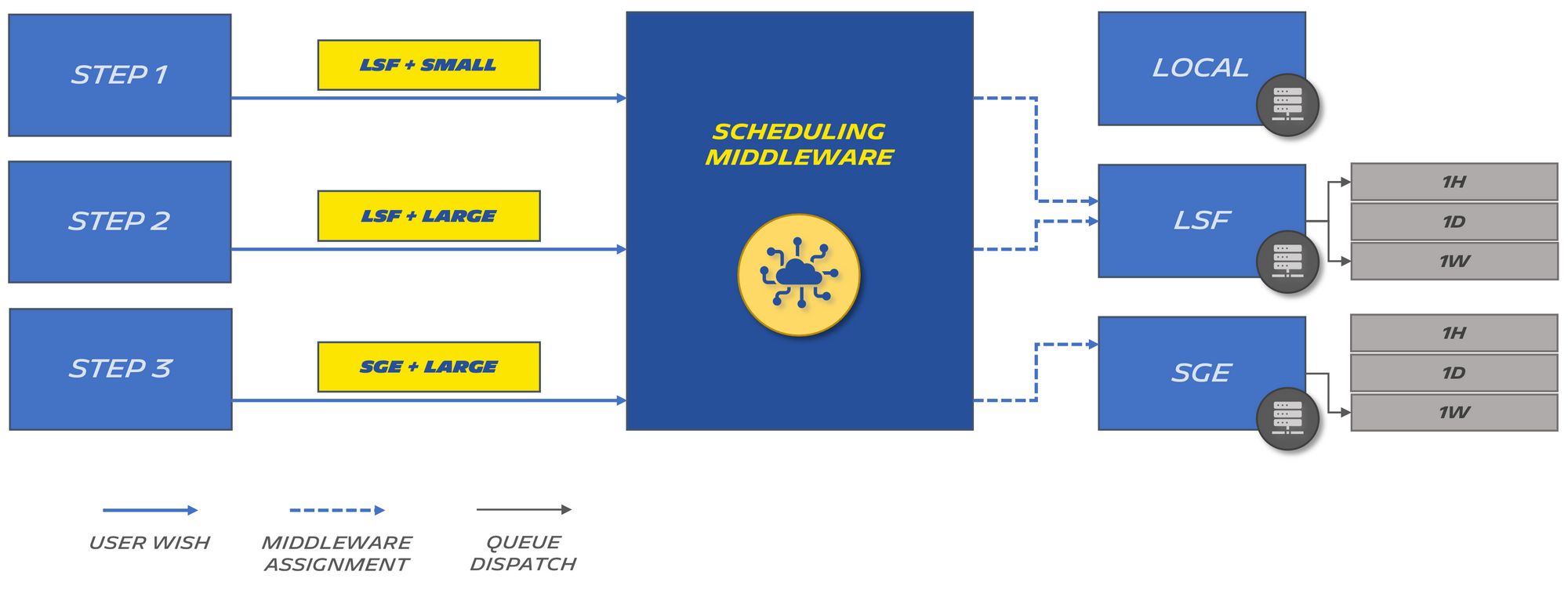
The standard configuration we use to manage this looks something like this:
[ExecTarget]
Lsf = Lsf
Sge = Sge
Local = Local
[Lsf]
small = 1H
medium = 1D
large = 1W
[Sge]
small = 1H
medium = 1D
large = 1W
On the left side of the equals sign, we always have the wish of the user. On the right side, we have what we actually want to translate their wish into.
By making an 1-line change, we can reroute any job initially intended to run on LSF to SGE (or the local machine for example for small computations):
[ExecTarget]
-Lsf = Lsf
+Lsf = Sge
Sge = Sge
Local = Local
This allows us to adapt when there is a failure or scheduled downtime on one of the systems:
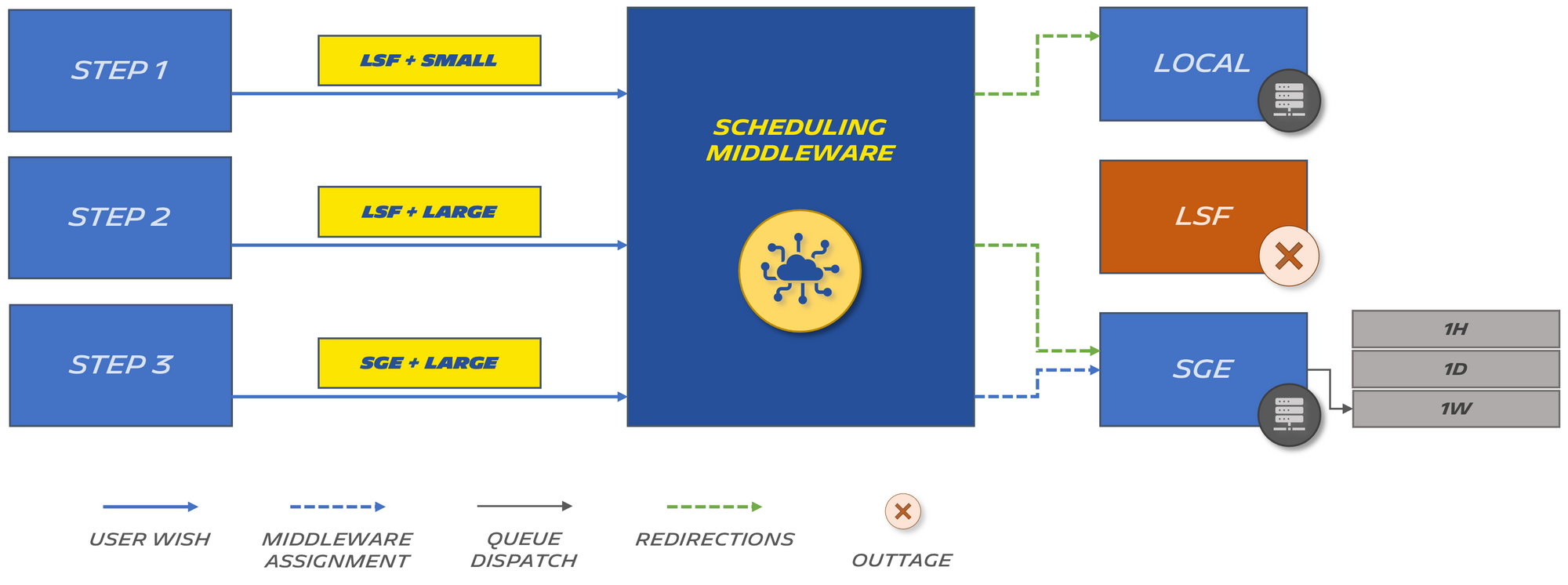
Note that this rerouting happens when an administrator has manually made the changes in the configuration file.
Wait ... Over-engineering much?
So at this point, some of you might be thinking that what we call "a chain" of steps is simply a re-implementation, on a smaller scale, of a job scheduler. Why not just use one, taking advantage of their capability of declaring dependencies between jobs?
Well, we have been working with the following assumptions, that are all being used today:
- we should be able to run everything cut-off from our mainframe (with no job scheduler), which means running on the local machine while still parallelising when possible
- we should be able to easily switch between multiple job scheduling solutions, as federating the two existing ones into a single solution has been a long-standing goal of ours
- obviously we need to therefore be able to easily add support for new job schedulers
Furthermore historically each scheduler has been setup with specificities in terms of time limits, computational power and memory allocation. Also other tools are relying on these existing solutions. It did not make sense for us to carry this big of a change, or to cut ourselves off of half the mainframe.
Low level translation
With the simulation correctly described as steps, with requirements and dependencies, we can transform this into an execution graph. This phase is performed by an intermediate layer:
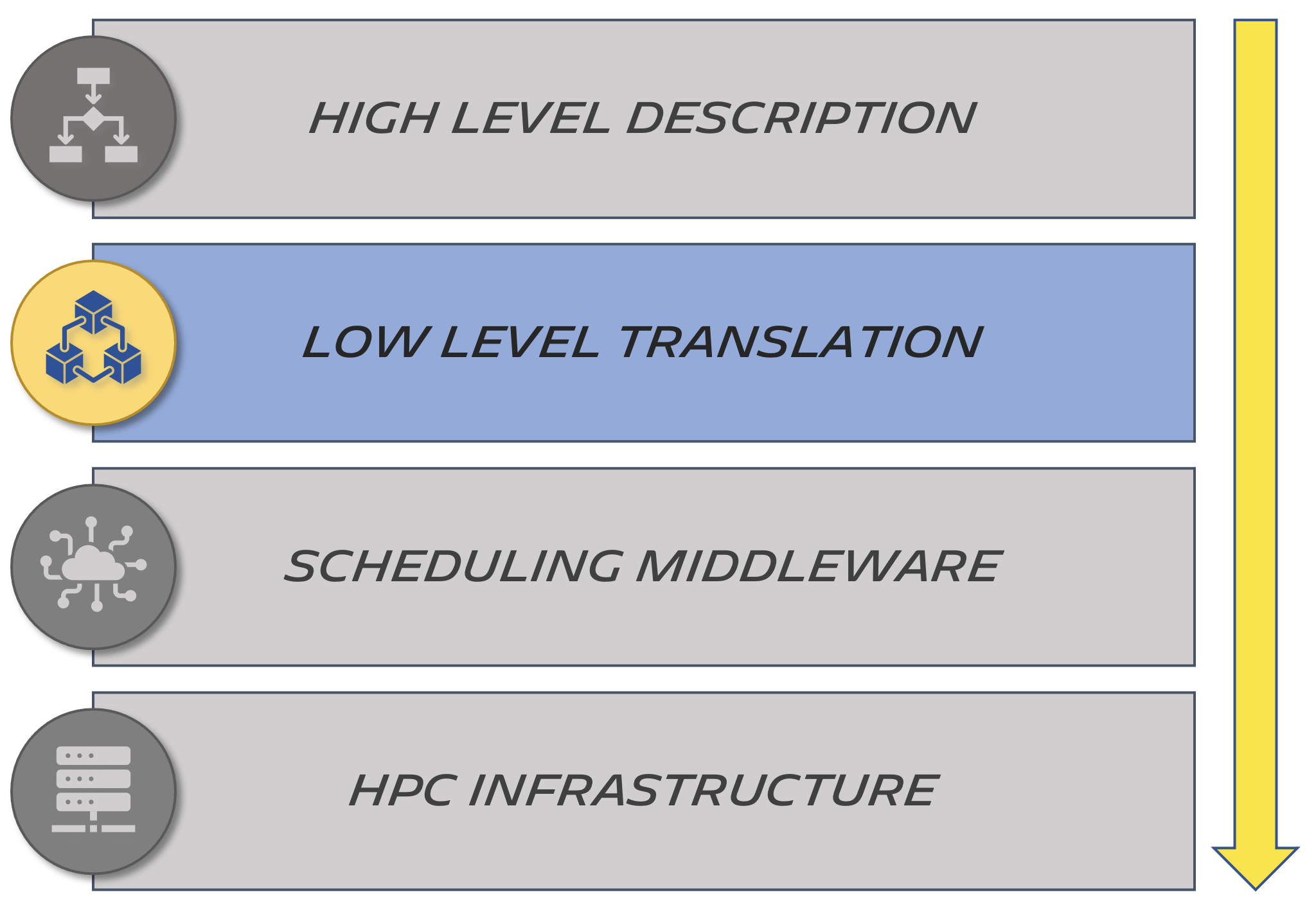
This layer transforms the previously defined simulation into a directed multigraph.
At this level, we abandon all business notions and we only talk in terms of nodes and edges. networkx is our friend from this point on. We are also still entirely agnostic of any underlying job scheduling solution. The specificity will only come into action at the very last time during runtime.
What we often observe during this phase is that the dependencies generated in the graph representation does not necessarily match the user expectations. This is usually due to their habits of doing tasks in a certain order:
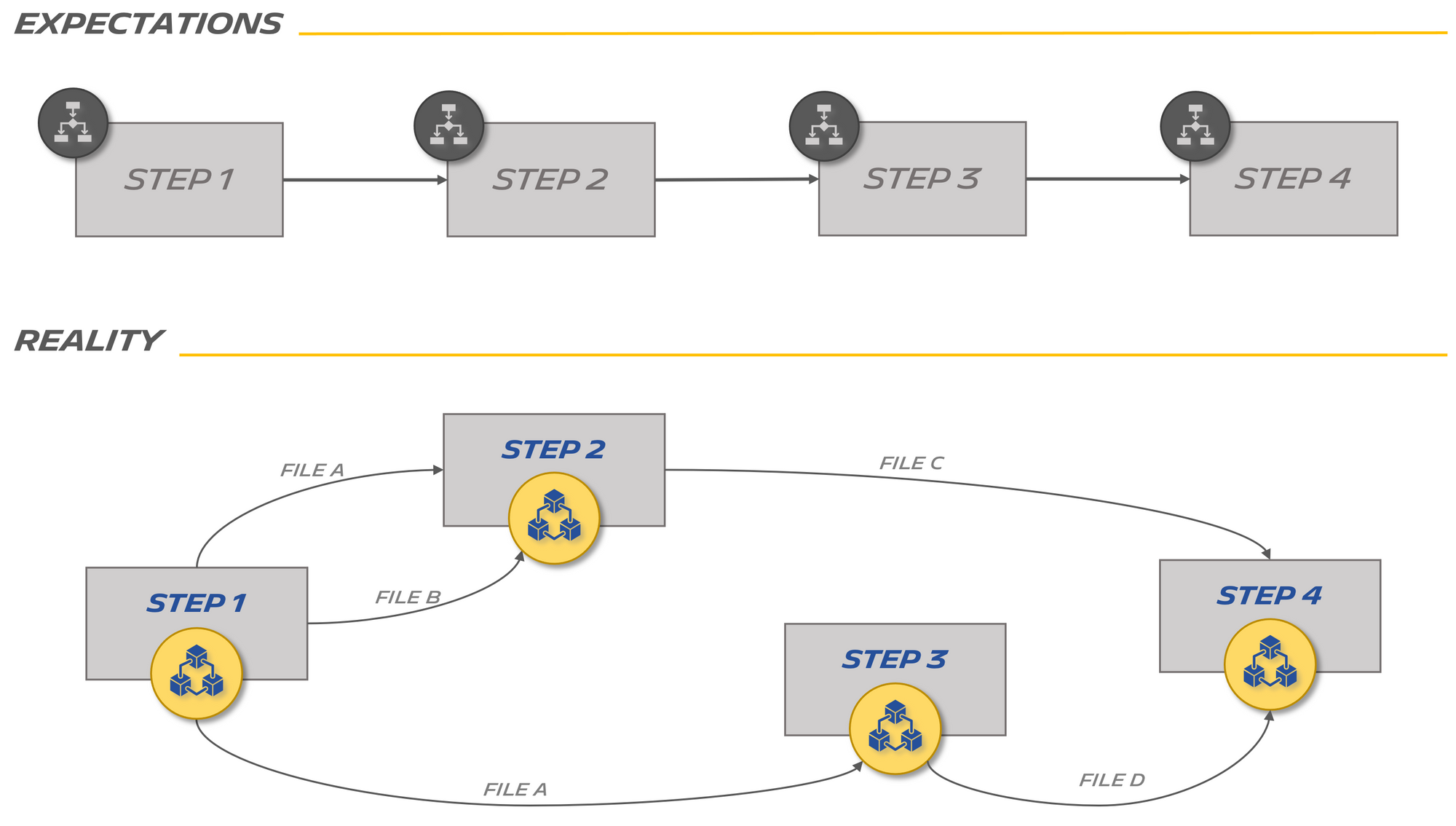
On the implementation side, the middleware has a set of specialised classes that take care of interfacing with each cluster:
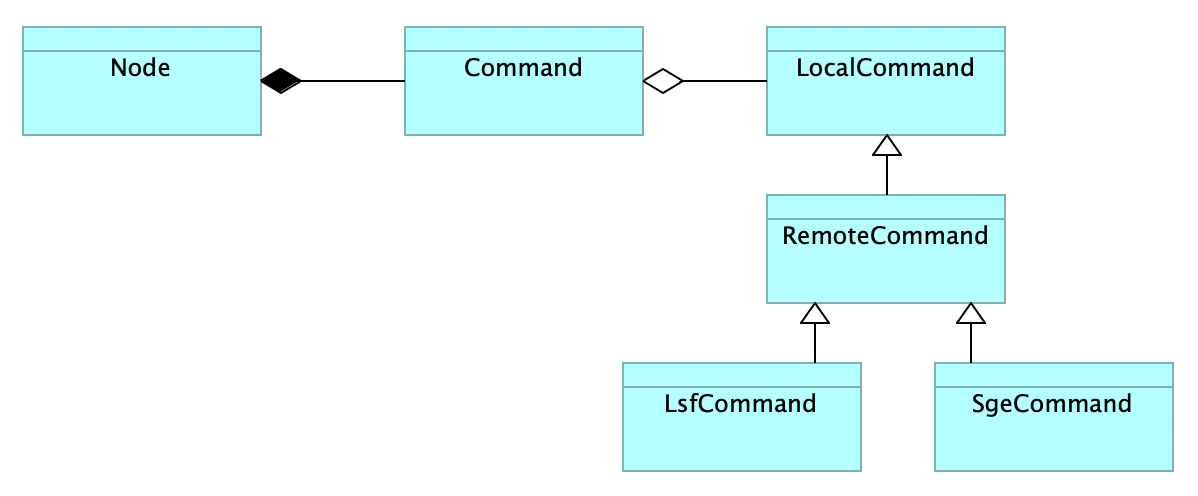
Here a Node instance is a step from our execution graph.
This specialisation level interacts directly with the system binaries. For example the stop() function of the LsfCommand looks something like this:
import subprocess as sp
def stop(node):
# 1. Get the job id (from node.id and some awk magic)
bjobs = sp.Popen(
f'bjobs -J "ues_{node.id}_*" | awk -F" " \'/^[0-9]/{{print $1; exit; }}\'',
stdout=sp.PIPE,
stderr=sp.PIPE,
shell=True
)
job_id, cmd_err = bjobs.communicate()
try:
# 2. Try killing it
job_id = int(job_id)
bkill = sp.Popen(
f'bkill {job_id}',
stdout=sp.PIPE,
stderr=sp.PIPE,
shell=True
)
kill_result, kill_err = bkill.communicate()
except ValueError as ve:
# 3. Assume something will fail despite your best efforts
...
except Exception as e:
# 3 bis. One way or another
...
To get a better understanding of how this works, let's look at the output of the bjobs command on the mainframe (with some redacted information):
~ > bjobs -u all -w | grep ues
192002 user RUN large balancer runner ues_c057a23ae86e30caf2cfa8276940453a_... Sep 13 16:51
192029 user RUN large balancer runner ues_b26397c5d2c0bb7f2279db90813b278b_... Sep 13 17:02
192032 user RUN large balancer runner ues_a9b156e91964b4175e906cafdf9da7e9_... Sep 13 17:03
191939 user RUN large balancer runner ues_c8d0a07445b463ddf0afb8cfdd4b7008_... Sep 13 16:21
191857 user RUN medium balancer runner ues_8966fecf63b86e0dc24f5ab7a41c1598_... Sep 13 15:11
191882 user RUN medium balancer runner ues_bdddc9109b84a08140e1ae34d1208a2c_... Sep 13 15:46
192030 user RUN medium balancer runner ues_23c68c7264c0c32143048acc31210537_... Sep 13 17:02
192031 user RUN medium balancer runner ues_96dc3fce62703579f5cc28301efd8ad3_... Sep 13 17:03
191564 user RUN xlarge balancer runner ues_431895a35906b1f65d4229b3bf80f8fd_... Sep 13 12:23
191593 user RUN xlarge balancer runner ues_f06d91a4e79a37f4451f9513aacc8121_... Sep 13 12:57
...
~ >
You can spot the "ues_{node.id}_*" pattern used to capture the first column, which is the job id that we will then use to call bkill.
Taking a 5-year step back from the solution
Some figures
It has been five years since this solution first hit production in 2016. Today it handles around 10’000 simulations each month. Our lowest point is around August, due to French summer vacations, and even then we barely go below 8'000, since the solution is running world-wide.
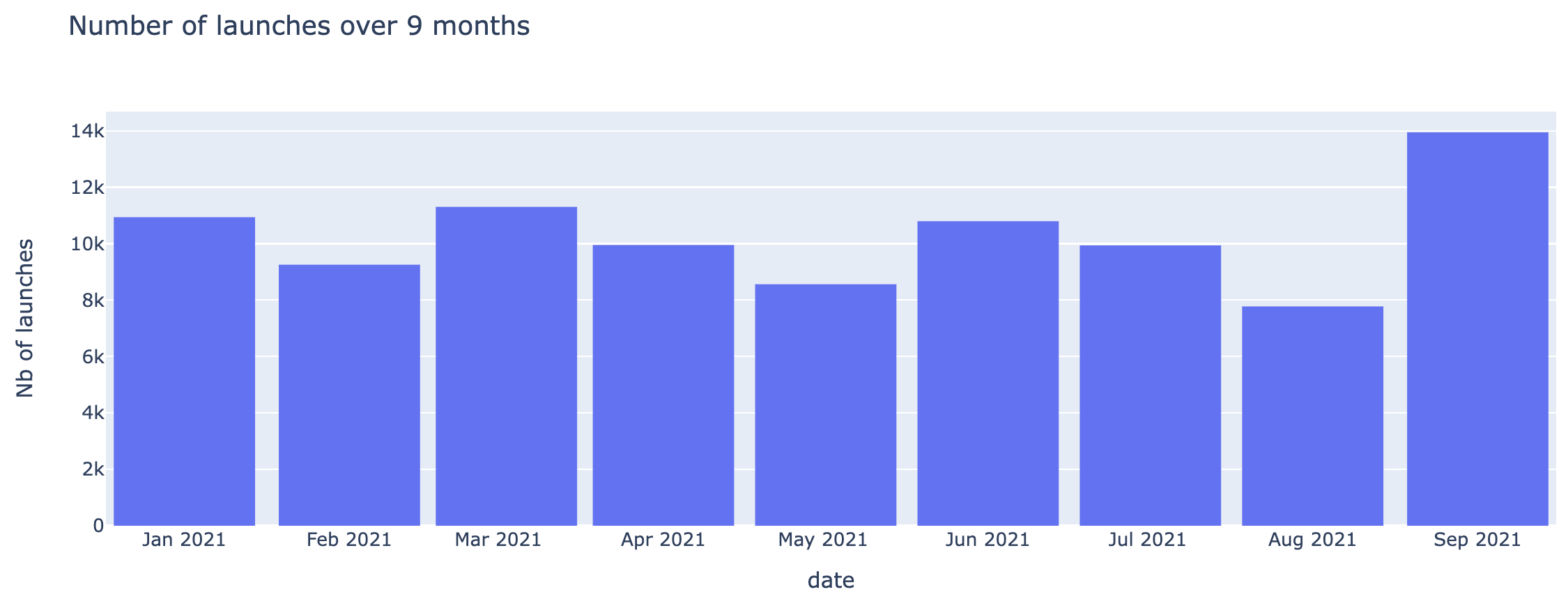
Another takeaway is that with the natural turnover of people, as well as younger generations being introduced to the tool, our adoption rate has increased greatly in the last couple of years.
Flexibility of the solution
The time has come to introduce SLURM into the mix (alongside LSF and SGE at first). Slurm Workload Manager is a free and open-source job scheduler that has been getting popular and with some pretty well-known actors in the HPC field as contributors.
The work of adding this new solution is extremely minimal.
First adding a 50-line or so class:
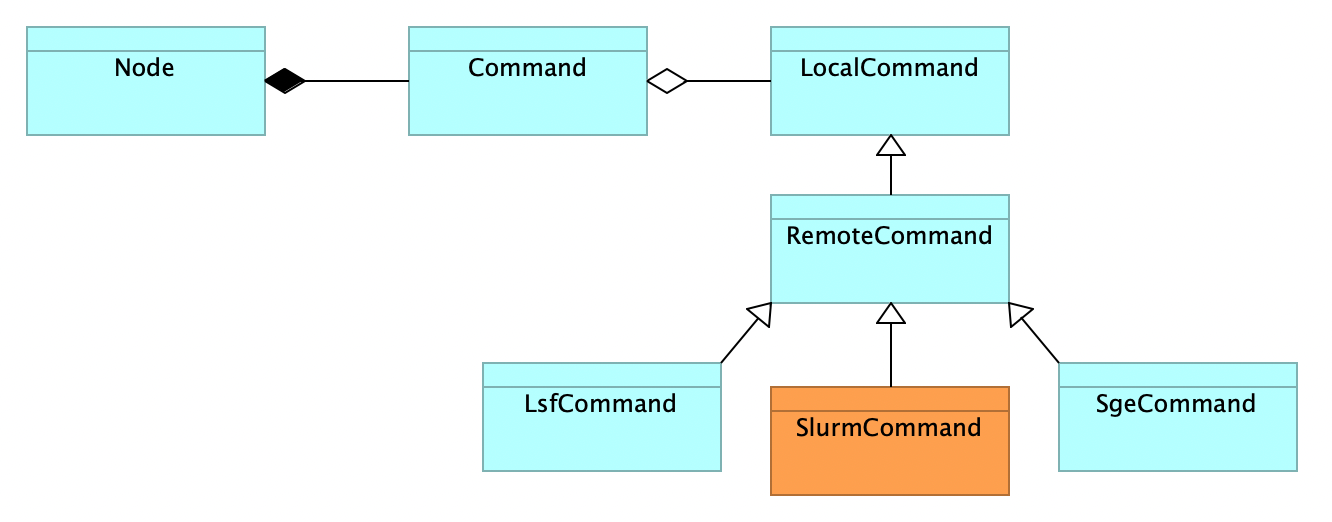
Re-implementing the basic interface required:
- execute()
- stop()
- that's it!
Then adding an 8-line entry into the scheduling middleware configuration file:
[ExecTarget]
Lsf = Lsf
Sge = Sge
Slurm = Slurm
Local = Local
[Lsf]
...
[Sge]
...
[Slurm]
xsmall = ...
small = ...
medium = ...
large = ...
xlarge = ...
xxlarge = ...
We can handle a gentle decommissioning of the other solutions when the time comes by using the same trick as earlier:
[ExecTarget]
-Lsf = Lsf
+Lsf = Slurm
-Sge = Sge
+Sge = Slurm
Slurm = Slurm
Local = Local
Note that this requires no change of code at all and allows an immediate rollback if we spot any problem.
Maintenance
Our low-level and high-level layers are very low maintenance. 3'500 or so lines of python code each.
It has taken 5 years before we reached limitations for which we need to schedule time to improve the solution. Of course there is more code that sits on top of that (a web application and business logic), that may be the topic of another article.
Taking this to the clouds 🚀
This middleware is essentially an interface between a high level description of a workflow and a bunch of computation capabilities. At this point (and as we've shown with SLURM), it does not take much to incorporate new solutions.
The next step will be to plug this to cloud providers in order to be able to deal with extra loads. The architecture of the solution will ensure that we are not strongly linked to any provider, giving us choice.
Although changes to the configuration file used to reroute jobs are entirely manual today, having code able to determine when to reroute to a cloud will prove necessary going forward. This could be the opportunity to add a bit more logic, like accounting in order to make sure the big users are the ones receiving the bill.