
Kafka connectors migration feat. Kestra
.jpg)

As described in our previous articles, we are leveraging Kafka widely at Michelin. Each factory in the group hosts its own Kafka cluster, representing 60+ clusters, to be able to work in complete autonomy. Another cluster, a Confluent Cloud cluster, serves the central needs. When topics need to be replicated to the central cluster, application teams use Kafka connectors, deployed on a single Kafka connect cluster in K8S, managed by our platform team for manufacturing.
A single connect cluster ? Not anymore
With the growing usage of Kafka connectors, we decided to refine the connect cluster management and split this cluster into 3 connect clusters, 1 by geograpical zone (Europe, Americas and Asia). It would improve the connectors rebalancing during operations on the cluster, but also the synchronisation mechanism with our referential ns4kafka. Combined with some recommandations, like using a connector for multiple topics rather than a single connector by topic, we wanted to setup a durable situation, even with the growing need on local to central topic replication.
As a platform team, we wanted to minimise the impacts on the application teams regarding the connectors migration to perform. It means, do not ask them to migrate connectors by themselves, ensure a smooth migration without re-replicating messages, but still let them validate the migration or be able to rollback.
Stop and recreate the connector, that's all !
Well not really. People sometimes think that a connector acts as a classic consumer for topic replication. A consumer has a consumer group to know where (which offset) to resume the consumption after restart. That's not how connectors works.
Because of the diversity of sources, Kafka connect, in its framework, stores the source connector offsets in a topic. The naming is customisable with the offset.topic.storage configuration key. Then, each connector (JDBC, MirrorMaker, MQ, etc.) define which information it needs to save to resume its state.
For instance, a JDBCSourceConnector, using the incremental mode, needs a column in the source table to track the modification date and query only the delta records since this time. Therefore, the message contains in the value timestamps.
- Message key:
["my_jdbc_source_connector",{"protocol":"1","table":"my_source_table"}] - Message value:
{ "timestamp_nanos": 378000000, "timestamp": 123456789 }
A MirrorSourceConnector follows the same principle and saves the source topic offset.
- Message key:
["my_mirror_source_connector",{"cluster":"replica_source","partition":0,"topic":"my_source_topic"}] - Message value:
{ "offset": 404552 }
Based on this behaviour, we know that the migration must keep these messages in the new cluster offset.topic.storage topic. Thanks to KIP-875, the connect cluster REST API provides new endpoints to retrieve and update the offsets for a connector.

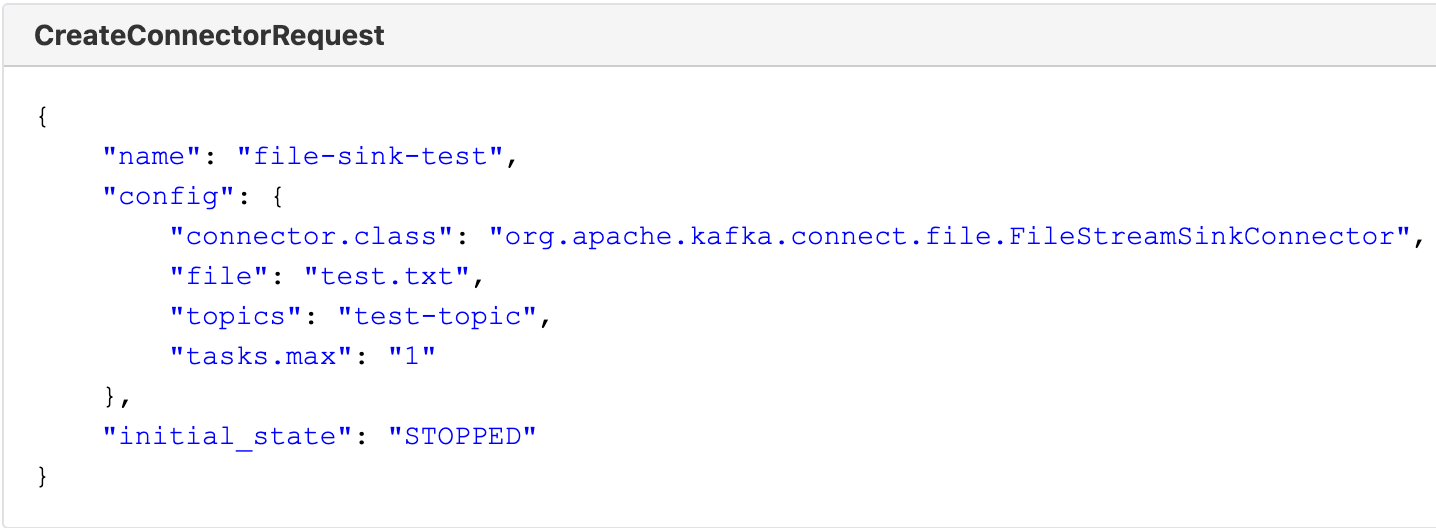
KIP-980 provides also a way to create a connector in a STOPPED state, using the initial_state field, allowing us to update the offsets before starting it.
The migration workflow is becoming clear, isn'it ? Stopping the connector, retrieving the offset, the configuration, recreating the connector in stopped state, altering the offset and finally starting the connector.
There is still a little question to answer. How often are the offsets committed in the offset.topic.storage topic ? For each message (MirrorSourceConnector), record (JDBCSourceConnector) ? No. At regular intervals ? Yes. Offsets are flushed regularly, every minute, if you keep the default value for offset.flush.interval.ms. It means that we will need to wait a bit after stopping the connector to be sure we get the real offsets.
It is time to build this workflow. REST API calls, some JSON transformations, some parallelism to migrate several connectors at the same time, sub-flows to split the migration and the notification parts. This is basically what we want to achieve. This is where Kestra comes into play.
Supersonic workflows creation with Kestra
3 hours. This is what it took to build a first testable version of the workflow. From deploying a Kestra instance to migrating a first test connector, starting from scratch.
Kestra is a "Workflow Automation Platform. Orchestrate & Schedule code in any language, run anywhere, 600+ plugins. Alternative to Airflow, n8n, Rundeck, VMware vRA, Zapier ..."
Kestra offers several deployment architectures: standalone instance with JDBC backend, all the components (webserver, executor, scheduler, worker, etc.) deployed independently with a JDBC backend and even a Kafka and ElasticSearch based deployment to ensure high throughput. I opted for the simple one, a standalone instance with a PostgreSQL database, thanks to the Helm chart provided by the Kestra team.
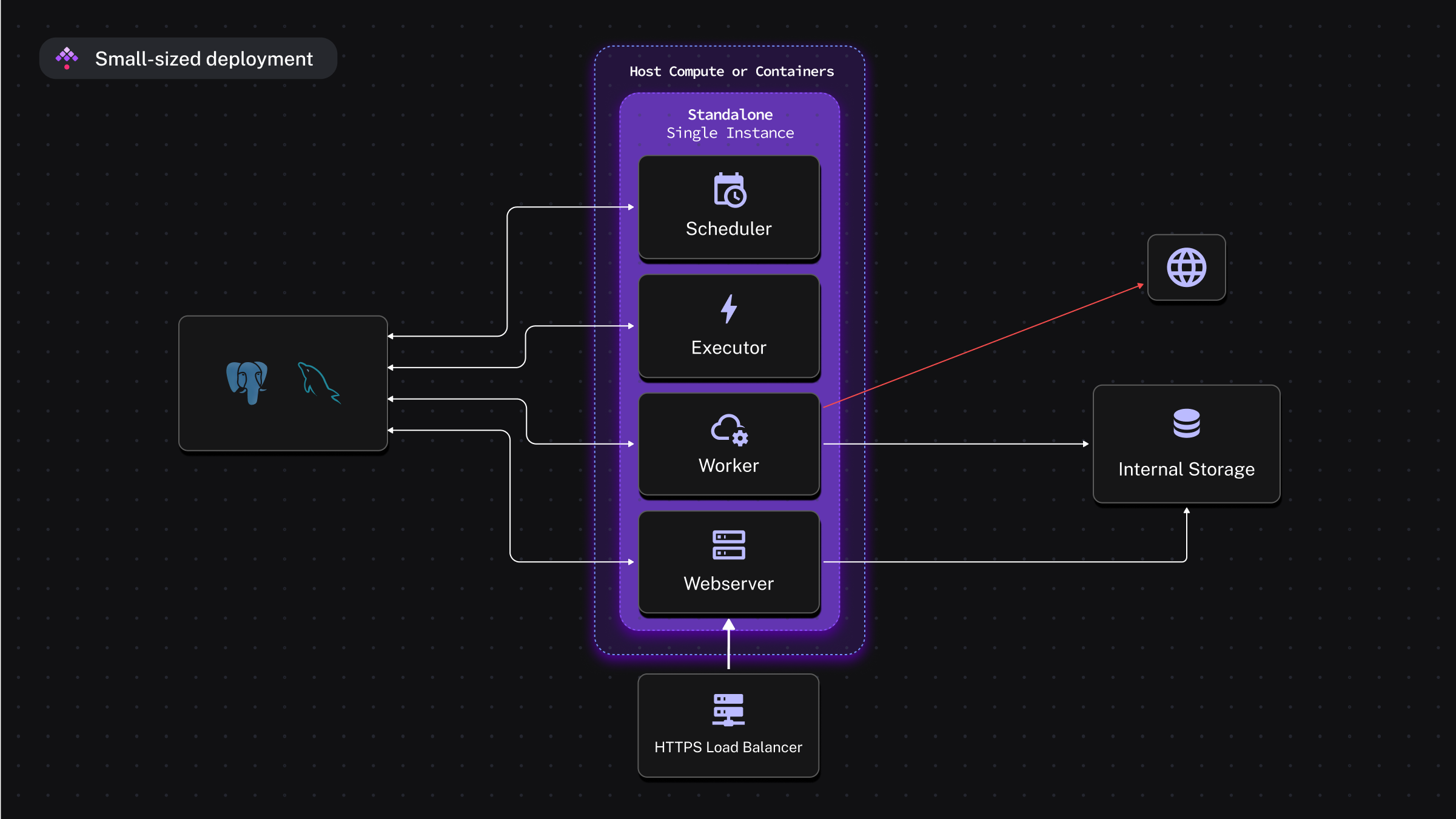
Kestra main concepts are the following:
- Flows: there are defined in YAML. No need to master Python so it is within everybody's reach.
- Plugins: groups of tasks or triggers that you can extend by developing your own plugins. 600+ plugins are available (dbt, Azure, Git, databases, etc.)
- Triggers: automate the execution of a flow. It can be a schedule trigger, manual trigger, webhook trigger, etc.
- Tasks: the core of the flow. The business-logic of the flow is defined with tasks.
- Inputs: the flow parameters. It's a list of key-value pairs, defined by an id, a type (STRING, ARRAY, etc.), a default value...
- Outputs: the tasks result that you can pass to downstream tasks.
- Pebble Templating Engine: the engine used to dynamically render inputs, outputs or variables.
{{ inputs.my_flow_first_input }}allows you to get the my_flow_first_input value in your tasks. - Scripts: you can still run tasks written in Python, R, Node.js, or other scripting languages in a dedicated scripts tasks.
The feature that I loved the most is the powerful editor that shows in a side panel the live documentation of the task you are pointing out. You don't need to jump between Kestra and the online documentation to write your task. The documentation is well written, with a lot of examples. The autocompletion works perfectly too.
Let us have a look to a part of the migration flow in Kestra:
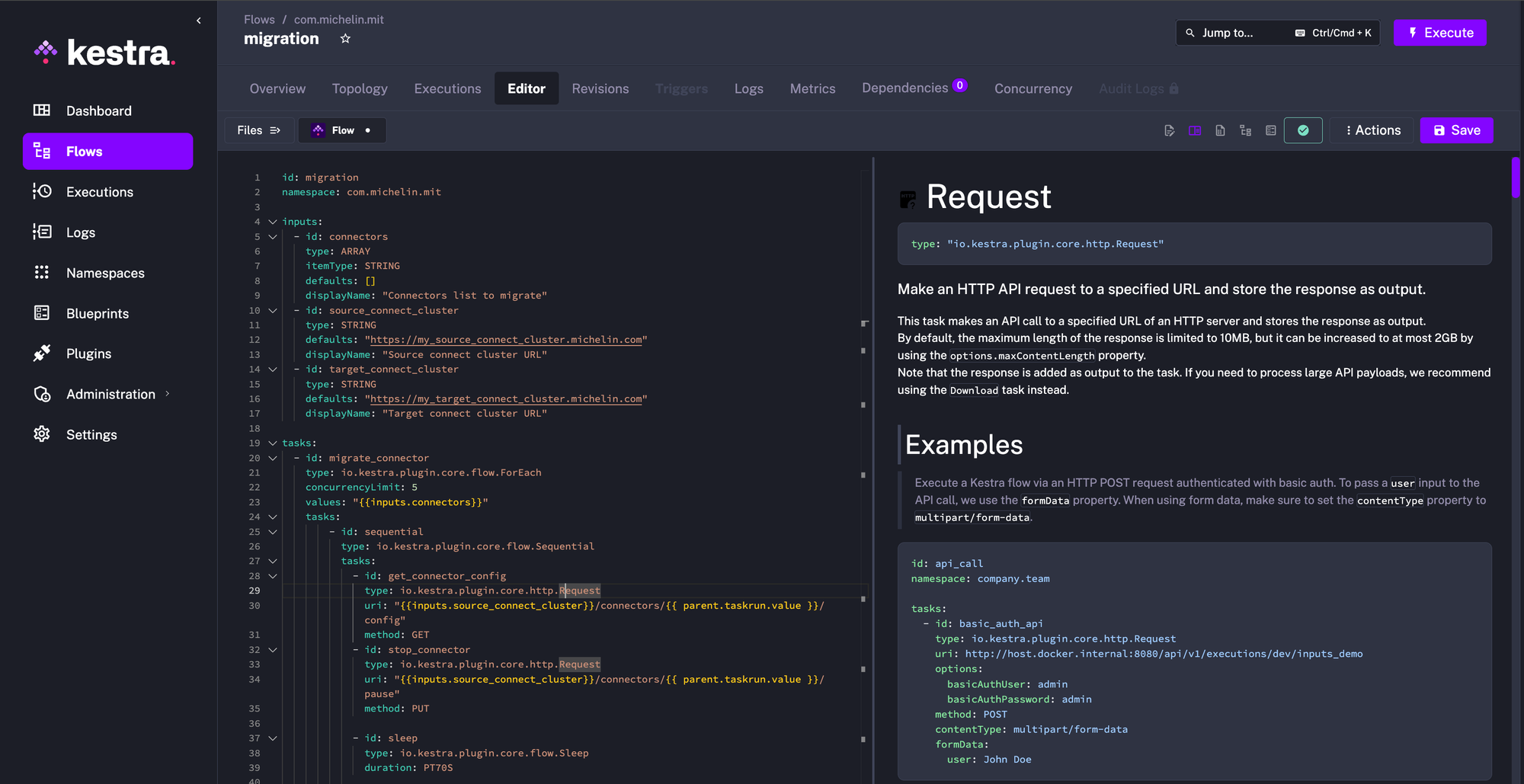
I start by defining the flow input. We need a list of connectors to migrate, a source and a target cluster.
Then we can start writing the flow. The first task is a simple for each loop over all the input connectors. I just added a little bit of parallelism using the concurrencyLimit property. Let's take another example, the Request task. At line 28, this task simply gets the connector config by dynamically building the URL from the input of the current loop item. The response is available later using {{ outputs.get_connector_config }}
If you remember, we need to recreate the connector with the right configuration and, in a stopped state. The next picture shows the expected body of the connector creation request (the initial_state is not present in the example).

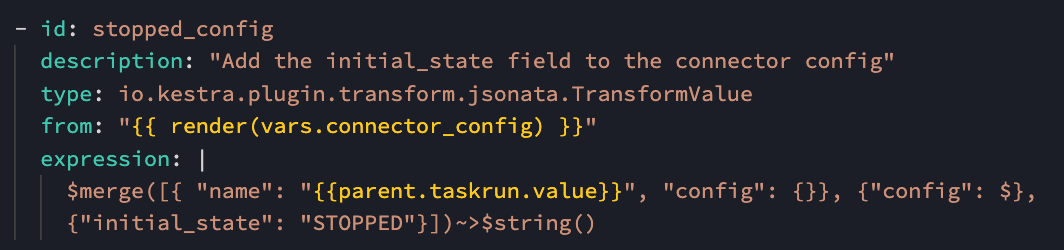
Here is the corresponding task that build the JSON object using JSONata (JSON query and transformation language).
The input of the task is given by the from field. In this example, I use a variable to get the connector config, to ease and reuse dynamic variables.
The expression that build the JSON object, with a merge between:
- The connector name:
taskrun.valueallows to get the current loop input value, prefixed here byparentbecause there is an extra Sequential task between the loop and the TransformValue task) - The actual connector configuration (
$) - The
{ "initial_state": "STOPPED" }that we need to add
The other steps are defined similarly. A series of REST API calls, some transformation, a call to another flow that manages the notification.
When the flow is ready, it is time to run it. In this case, the trigger is manual so we just need to fill a form with the input parameters. Then, Kestra offers several tabs to monitor the execution like:
- An Overview tab displaying the general information like the inputs, the execution time and result, a way to restart it, etc.
- A Gantt view showing a timeline and the execution time of each tasks

- An Outputs tab to debug each tasks outputs. This one is really useful to identify, debug and solve issues.
- ...
I don't want to go too deep into explaining Kestra features. The documentation does it better. I just wanted to show that it allowed me to build a simple workflow answering this migration need, quickly, with the information that I needed to monitor and debug it.
Let us take a step back
This connectors migration was a good opportunity to go deeper into Kafka connect, the connectors way of working and to give a try to Kestra.
Did it answer the original need ? Yes. Everything was there in the connect clusters API since Kafka 3.7.0 and in Kestra to build the migration workflow very quickly. End users were only involved for final checks after notifying them, doing some cleaning to remove the old connectors and finally updating their deployment project to target the new cluster.
Is it easy to start working with Kestra ? Definitely. YAML-defined flows, the available plugins and the documentation make it straightforward.
Do I recommend Kestra ? Yes but. You don't need to develop your workflow using a programming language (like Python for Airflow). This a game-changer that makes Kestra more accessible. But it is flexible enough to run any code. The plugins catalog is huge and you have all you need to monitor the Kestra platform with your observability platform like Grafana, your flow executions via the API, etc.
In large organisations, I think you will quickly be limited with the open-source version. High availability, authentication (only basic auth in the open-source version), RBAC, multi-tenancy, Kafka backend for intensive usage are part of the enterprise version.
After working quite a lot with low / no-code tools, I can say that I was quite sceptical with this kind of tool. Kestra sits at the right place, making the experience for a developer like me enjoyable. In French we say "Il n'y a que les imbéciles qui ne changent pas d'avis" (Only fools never change their minds). I can say that I'm starting to change mine !