
Data in motion, myth or reality

{kind=link}

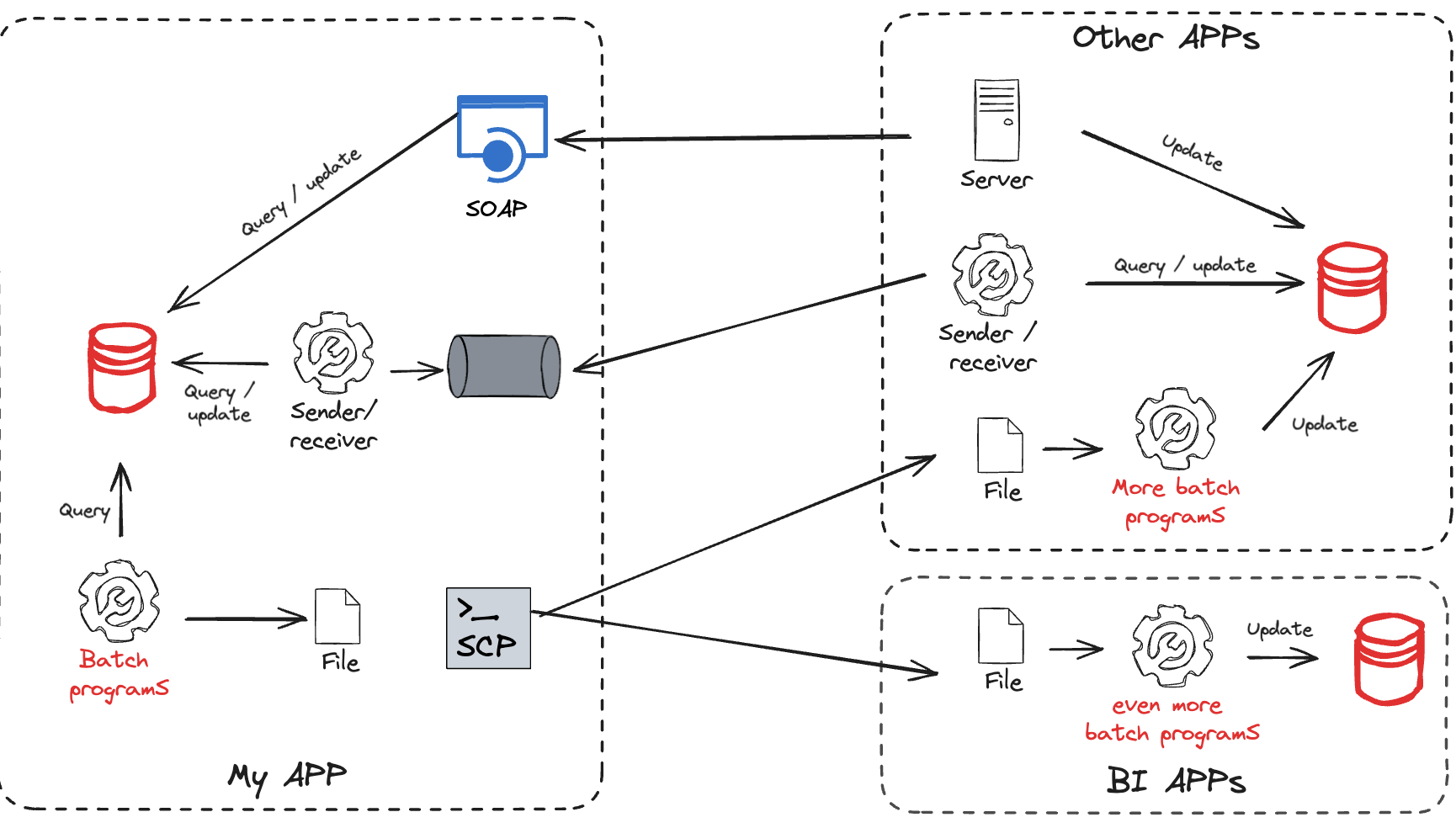
When I started to work in IT a couple decades ago, the center of the universe for a software engineer was databases, mostly relational ones. We were relying heavily on their transactional capabilities to ensure data consistency. Integrating an app with the rest of the world was quite a challenge. Batch programs were creating files which were then transferred using managed file transfer solutions; That was the norm. Message queuing & APIs were around but not that much popular. To recap: Databases were the center of our world and we were relying on huge batch plans to transfer data. The analytical/BI world was already asking for a lot of data requiring more batch plans to feed... their databases designed using the 3rd normal form of course. The fundamental assumption here was that data was passive and you had to query the database. So really, data was not that much in motion. At best, we were spending a ton of time to export and import it from one database to another.
The world is asynchronous
If we consider that asynchrony is the basis of the real word as stated by Werner Woegel in his AWS re:Invent 2022 keynote, adopting an event-driven approach to design your Information System makes sense. It has numerous advantages, the first being decoupling your systems. Decoupling systems is critical today as it's a way to have your Information System more agile and faster to react to the unexpected.
If you organize your Information System around asynchronous events then it completely changes the game. Events are designed to be communicated externally and meaningful. First, an event is not passive, it happens and others react to it. The second advantage is that once an event is published, it can be consumed by anyone. That's where and when the decoupling happens as you don't even have to know or care about who is using the event, you're completely decoupled from its usage.
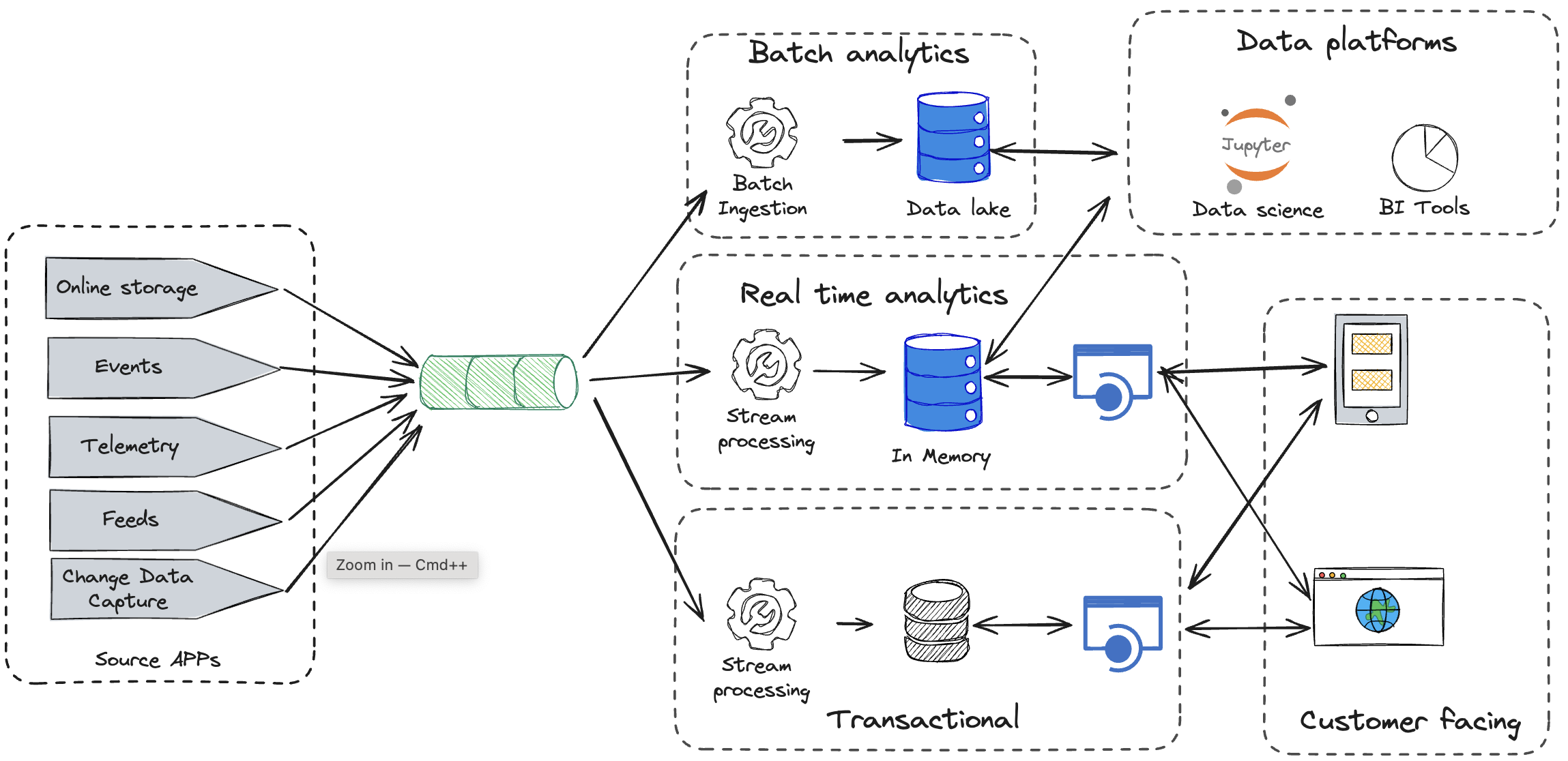
When you look at today's digital champions, they all organized their Information System around events. The below schema is an overly simplified view of the Uber architecture. It shows that an event driven system is very versatile. If you publish your data as events, they can be consumed by another transactional app, a batch analytical system or a real-time analytics one. It does not really matter and that is the point actually.
Technology-wise, Apache Kafka quickly took the de-facto position on the market to support this event driven transformation. It is versatile, reliable, scalable and fast. The beauty of Kafka compared to traditional message queuing middleware was that once the data are in topics they can be consumed by many and stay in there for quite a long time.
From database-centric to data in motion
When you look at Apache Kafka, it's just a pipe through which messages are flowing. Yes, it's efficient, resilient, scalable... but the value lies somewhere else. On top of Kafka, a new generation of data processing frameworks called stream processing emerged. They were designed with a completely new paradigm: Data is flowing so why don't we process it as it flows and put back the result in topics so it can be processed again or offload somewhere.
Stream processing systems are often dataflow systems. Dataflow programs are structured as flows of data between a Directed Acyclic Graph (DAG) of operators. Each of these operators applies a transformation to a stream of data records, which are composed of:
- Content: A (generally) flat data structure of arbitrary data which the program processes.
- Key: A form of identifier (think userID/itemID/userRegion) assigning the record to a logical “group”. Used for routing and aggregating.
- Timestamp: The timestamp at which the record either entered the system, is being processed or was created.
Structuring programs this way allows for easier scaling through the use of both data parallelism and pipeline parallelism.
These dataflow programs are defined using either imperative (Flink’s DataStream or Kafka Streams) or declarative (SQL) APIs. Let's consider the simple example of a streaming word-count shown below.
// pseudo-code for defining a Flink Dataflow program using the Streaming (DataStream) API
// example is WordCount with initial filtering.
env.source(new MySource(...))
.filter(x => x.last == ".") // filter out only well-punctuated sentences
.flatMap(new MyTokenizer()) // split sentences into tokens
.keyBy(0) // group records by token (words)
.sum(1) // reduce using the second property of the record (count)
.sink(new MySink(...))
When submitted, this code is translated into a high-level plan called a logical dataflow, which contains the DAG of operators. The logical dataflow generated from the example code is shown below.

Your data processing logic is expressed with simple instructions like merging, filtering, aggregating, etc. You can combine events from two streams with joins, lookup data on one stream to enrich the other etc. If you embrace this approach, a good portion of your data logic is continuously running to process your streams of data in real time.
Streaming in your architecture
The below schema illustrates the architecture you could possibly implement with this approach. It's again overly simplified.
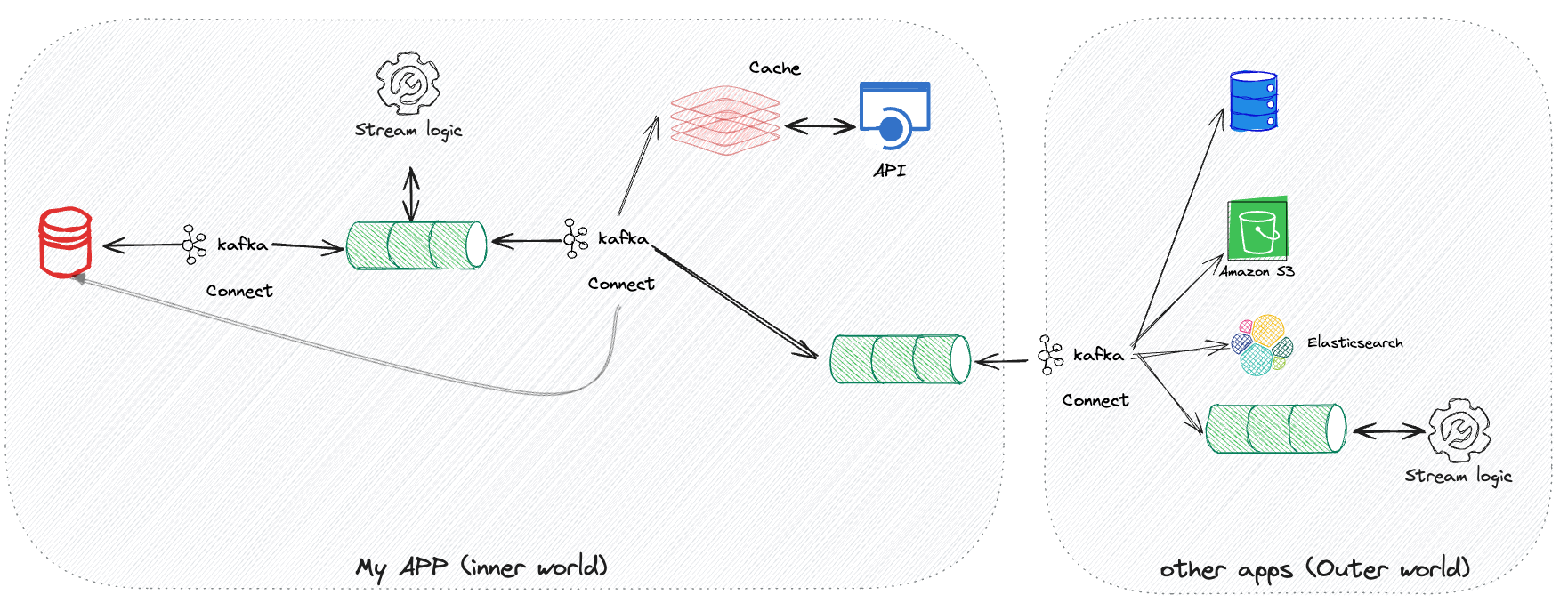
You can use stream processing within your app to implement any business logic that can be described using operators in an asynchronous way. These streams will consume internal topics and produce records in other internal topics. It is considered the inner world. It's private and not intended to be shared. Ultimately, you can leverage stream processing to expose some of this data to the outer world. Kafka connect is depicted here but it's not a mandatory piece of technology. It's convenient to offload the content of topics with the same characteristics than Kafka: Resilient, distributed, scalable, etc. With such a tool you can load a cache DB on which your synchronous API is plugged or to another topic. Then it's up to the outer world to consume these two APIs (synchronous & asynchronous) and they can do it in many different ways: load these data into a database, an S3 bucket (or equivalent), other topics, etc. It's not your problem anymore, you've done your job.
Reality check: It's not that simple
The world I just described is appealing but as usual it does not prevent teams to think and decide to leverage this approach or not. Exposing your services and data through events in Kafka topics is good but it does not work in all cases. Sometimes creating a synchronous API or simply using a storage capability may be simple enough. You need to consider the complexity of asynchrony and streaming to make sure it is worth.
There is also a technical challenge: can you easily put your data in motion through events in topics. Some systems are not able to produce events easily. A commercial package badly designed or an old application difficult to maintain will fall into this category. Technologies like Change Data Capture could be leveraged to overcome these difficulties. It's not a silver bullet either and must be used with cautious. It may be the subject of a future post.
The Empire Strikes Back
We started this post by describing how painful it was to move data between applications. Hopefully, we showed how Event Driven Architecture using Kafka can help to overcome these issues by freeing the data and making them available. In the world I described above, data are flowing in topics and ultimately make it to data warehouses, data lakes, lake houses ... to be processed with heavy batch processing if needed or visualized. When I say "ultimately" it's because these data systems are not the nervous system of a digital business. We could have thought we were in a good shape. Unfortunately, the Analytical World Strikes Back.
Everyone knows the famous memo written by Jeff Bezos in 2002.
1- All teams will henceforth expose their data and functionality through service interfaces.
At Amazon, it means: as a software engineer, you need to think on both the services you can expose and the data you can make available to the world. While the service part is clearly a foundational step for the Service Oriented Architecture move at Amazon, we will not focus too much on this part in this post. We will concentrate on the data part as it's mostly there that we are facing some issues. I have read the memo many times and I could not find a limitation on the API technology to be used. Bezos advocates for a freedom of choice when it comes to technologies.
4. It doesn’t matter what technology they use. HTTP, Corba, Pubsub, custom protocols — doesn’t matter.
Teams are empowered to not only choose the services and data they want to expose, but how they would expose them. All forms of APIs could be envisioned: REST, async, a bucket in S3, etc. I know some teams are even providing an SDK to access their internal database for others to connect easily. It is not ideal but, in some cases, it's the only way and it's still an abstraction. Over time, several generations of frameworks were created at Amazon to standardize a bit how teams were creating these APIs. Multiple languages are possible in these frameworks as the only thing that matters is using a universal way to expose the APIs. Surprisingly (or not), this move was critical to make Amazon able to grow and scale with autonomous and decoupled teams.
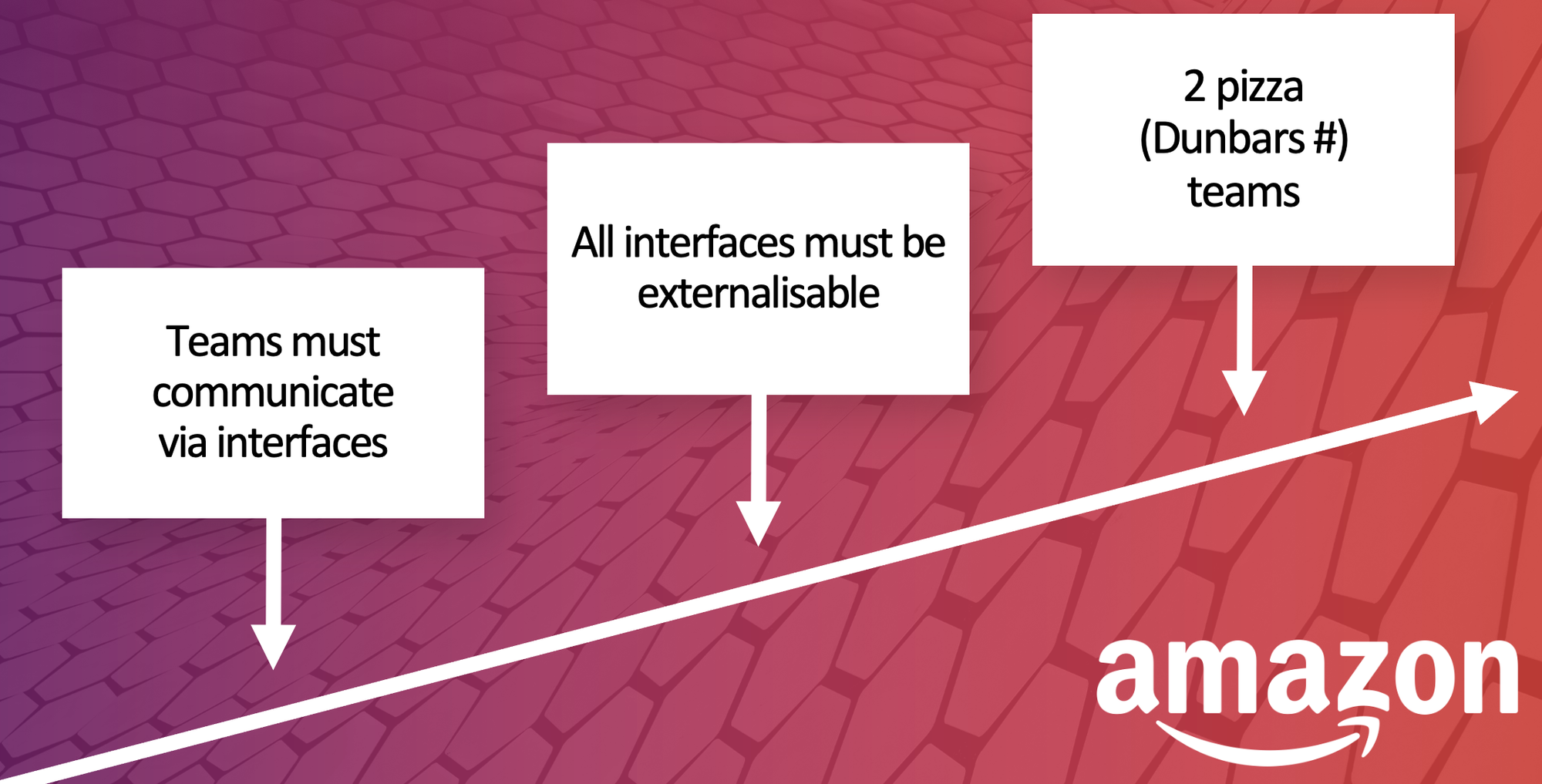
Bezos' original intention was to increase autonomy for teams by exposing data & services to whoever would need them. It was purposeful and systematic but empowering the teams on their choices. Expose what you think is valuable, stick to some core principles but you decide on the implementation. For some reasons, this approach was understood differently by many companies and recomposed in something like this:
Everyone needs to expose all of its data, period.
This "interpretation" is mostly coming from the BI and now AI worlds who spend their time asking for data to play with. When you say something like this to your teams, you are basically sending the message "expose all your data, whether they are relevant or not, just in case someone can discover something you haven't thought about and whatever the form including your very own internal format". First we should not do this and apply the frugality principle: Don't build something you don't know anyone needs. Exposing your data so someone may use it later on is not a need, it's wishful thinking at best. Then exposing your internal data structure is usually a bad idea because it was never designed for that purpose. You're introducing a coupling with external systems on your core internal data model. It's the exact opposite Bezos was aiming with his memo. It could be acceptable if the source team decides it on a specific scope to answer a specific need. Not in general for potential needs that will never materialize.
Beyond this compelling need to expose data at all cost, we're facing a second problem. Technology wise something happened that created a barrier between the transactional and analytical worlds. Databricks introduced the Lakehouse pattern that is somewhat a pale copy of the data in motion world but centered on a file storage and for that matter using Delta lake storage format (created and pushed by Databricks).
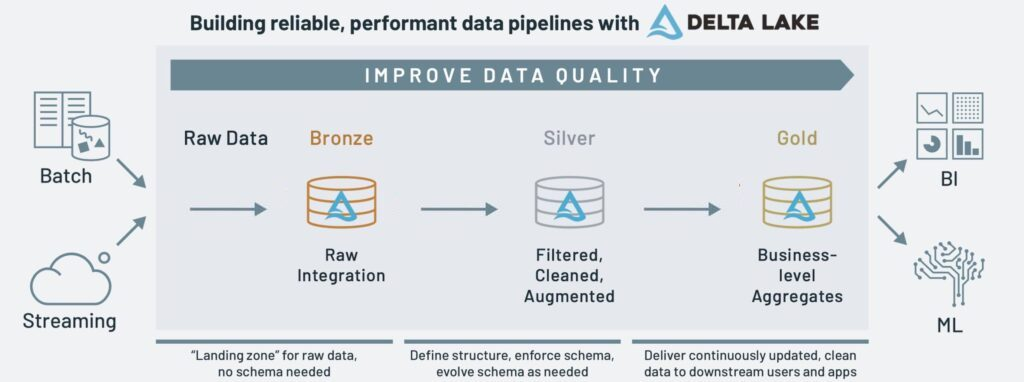
In this world, the data is moved from one storage to another with simili stream processing technologies. The barycenter of that world is the lakehouse and not the event engine anymore. It creates a bunch of problems we could have avoided:
- Once data is stored in a lake house, it becomes very difficult to consume it back. Lake house editors are doing this on purpose: It's in their own interest to keep the data locked in the lake house thus they did not make it easy.
- "Analytical" stream processing technologies mostly come from the micro batching world. They were not designed as real streams solutions like Apache Flink or Kafka Streams. They are inferior in many areas: latency, checkpoint and fault tolerance, performance and data shuffle.
- These different "stream processing" frameworks introduce an unnecessary technical diversity. It can be explained by the fact data engineers mostly masters Python and most of the real stream processing solutions were not available (even recently) in Python. It has a direct consequence: a team will have to master two different streaming frameworks and it's not easy.
- As analytical stream processing frameworks were mostly designed using a batch mindset, this will be a real blocker to move to real time analytics .
Where are we heading at Michelin
Kafka is already very popular and used in all domains of our different businesses: supply chain, logistics, order to cash, manufacturing, R&D, CRM, Services and solutions, Experiences ... We have Kafka clusters in the cloud (managed services) and on premise in our R&D facilities as well as in our plants. We don't deal with enormous volumes but still our clusters account for 3 Tb and process 100 millions messages a day over 5000 topics.
Stream processing is getting traction even if it's not as fast as Kafka mainly because it's difficult. I strongly recommend this article that explains how we design our stream topologies. It's the result of couple of years of wisdom, tears and sweat.
We do have different objectives for the years to come:
- Keep transforming our Information System into a reactive one where teams are more & more decoupled thanks to this Event Driven approach. We've seen the first results of our EDA move so will amplify it. That is why, we've just appointed a new Distinguished Engineer to be faster.
- Michelin wants to become a data driven company and it's essential. But becoming data driven is one thing, massively creating coupling because of it is another one. We need to bring rationality in how we expose data: understand why you're exposing what and be less diverse on the how.
- We need to reunite the transactional and analytical worlds because if we don't do it, all the decoupling we're introducing with an Event Driven approach will be annihilated. Cherry on the cake, if we want to go for real time analytics, we won't do it with such gap between the two.
So stay tuned!