
Kafka Consumption, Made Simple and Safe
Consuming Kafka events to feed an external system is one of the most common integration patterns. At Michelin, many applications use it daily. Making it reliable in production is harder than it looks. Let's walk you through the solutions we explored, and the one we built: Kafka Retryable Consumer.

{kind=link}

The Pattern: Kafka to External System
At Michelin, many applications follow a straightforward architecture: consume events from Kafka topics, transform or enrich data, and persist it into a database, forward it to an API, or push it to any third-party system.
Sounds simple, right? But real-life usage quickly reveals a different story... What happens when:
- the database is temporarily unavailable?
- an API is too slow to respond?
- a message fails to be processed?
These are not edge cases, they are everyday occurrences in production. And the way your consumer handles them determines whether you lose data or not.
Solution 1: Kafka Sink Connectors, The First Choice
When you need to move data from Kafka to an external system, Kafka Connect should always be your first consideration. Sink Connectors are purpose-built for this exact use case:
- Zero code: only pure configuration
- Built-in fault tolerance: offset management, retries, and dead letter queues handled by the framework
- Battle-tested: connectors exist for most databases (JDBC, Elasticsearch, MongoDB…)
- Scalable: distributed mode handles parallelism natively
For straightforward scenarios, like "topic to table", Kafka Connect is hard to beat.
When Connectors Fall Short
However, at Michelin, we often need more than a simple data pipe. Our use cases frequently require:
- Data enrichment: joining Kafka events with data from another source before persisting
- Business logic: conditional routing, field computation, validation rules
- Complex transformations: restructuring payloads, aggregating multiple events, calling external services.
Kafka Connect's Single Message Transforms (SMTs), can handle simple transformations (renaming fields, filtering, etc.), but they quickly hit their limits when more complexe business logic is involved. When your "consumer" is really a small application with intelligence in it, a Sink Connector becomes the wrong abstraction. You need code.
Solution 2: Spring Kafka, Powerful but Demanding
The natural next step for Java developers is Spring Kafka. And for good reason: it integrates seamlessly with Spring Boot, offers a rich annotation-based programming model, and provides all the tools you need for production-grade consumption.
Spring Kafka supports sophisticated error handling, retry policies, dead letter topics, and fine-grained offset control. It is a mature, powerful framework.
The Challenge in Practice
The difficulty is not that Spring Kafka can't do the job (it absolutely can). The challenge is that it requires deliberate, expert-level configuration to do it safely.
Out of the box, Spring Kafka's defaults are quite permissive:
- Messages are auto-acknowledged
- No retry policy is enforced
- Error handling is minimal
This design makes sense for getting started quickly, but in production, you need to explicitly configure acknowledgment modes, error handlers with proper backoff strategies, dead letter recoverers, and poll/session timeouts. All of this is well documented; but it demands a solid understanding of Kafka internals.
Across a large organization with many teams (some of which are not Kafka specialists) we observed a recurring pattern: teams would use the defaults, things would work in dev, and issues would surface only in production under load or failure conditions. We also have a few projects that need lightweight, framework-agnostic solutions using plain Java, where pulling in Spring Boot would be overkill.
Introducing Kafka Retryable Consumer Library
To bridge the gap between "too simple" (connectors) and "too much expertise required" (Spring Kafka configured properly), we built Kafka Retryable Consumer: a lightweight, framework-agnostic library that makes Kafka consumption safe by design.
The core idea: provide a ready-to-use consumer that handles retries, offset management, and error routing; while keeping the developer experience minimal.
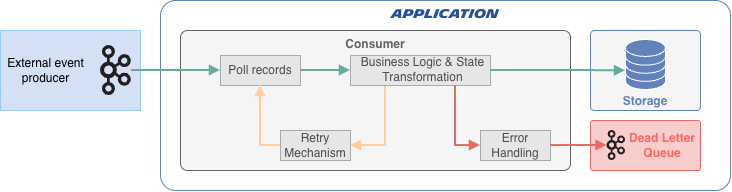
Key features
- Built-in retry mechanism: Automatically retries failing messages with configurable strategies.
- Dead Letter Queue (DLQ) support: Non-recoverable messages are safely redirected for later analysis.
- Safe offset management: Messages are only acknowledged when successfully processed.
- Explicit error strategy: No unsafe defaults; the developer must define how failures are handled.
- Fine grained error management: Exception handling simplified thanks to configuration of retryable/not-retryable lists.
- Framework-agnostic design Works with plain Java as well as Spring-based applications, ensuring consistency across all types of projects.
What It Looks Like ?
A consumer implementation requires just a few lines, after adding the dependency to your maven:
<dependency>
<groupId>com.michelin.kafka</groupId>
<artifactId>retryable-consumer-core</artifactId>
<version>${retryable-consumer-core.version}</version>
</dependency> Maven dependency
try (RetryableConsumer<String, String> consumer = new RetryableConsumer<>(
config,
record -> {
// Your business logic here
processRecord(record);
})) {
consumer.listen(Collections.singletonList("my-topic"));
}Example of consumer code using Kafka Retryable Consumer Library
👉 That’s it. No manual retry loops. No offset management. No complex error handling logic.
All the Kafka-specific complexity is handled internally, allowing developers to focus only on what matters: the business logic.
But unlike many other implementations, the library requires an explicit configuration of error handling and retry strategies. There is no unsafe default behavior: developers are guided to define how the system should react to failures through configuration:
kafka:
retryable:
consumer:
topics: TOPIC_TO_CONSUME
retry: # Retry configuration
max: 10 # Maximum number of retry. 0 means infinite retry.
dead-letter:
producer:
topic: DL_TOPIC
A typical Kafka Retryable Consumer configuration
This forces developers to answer a critical question from the start:
What should happen when something goes wrong?
No error is silently ignored. Retry behavior is explicit. Failing messages are always traceable via the DLQ.
When to Use What?
- For topic consumption to external system with none or simple transformations : Kafka Sink Connector
- For topic to external system with business logic: Kafka Retryable Consumer
- For topic-to-topic with business logic: Kafka Streams (with Kstreamplify)
When the processing stays within Kafka (topic-to-topic), Kafka Streams is the right tool; it supports joins, aggregations, windowing, and stateful processing natively, all without leaving the Kafka ecosystem. At Michelin, we use Kstreamplify to simplify Kafka Streams development.
But as soon as you need to push results to an external system (database, API, service…), Kafka Streams is not recommended; and that's where Kafka Retryable Consumer comes in.
At Michelin, we settled on three paths: Kafka Connectors for straightforward data pipes, Kafka Streams for complex topic-to-topic processing, and Kafka Retryable Consumer when business logic meets external systems. This gives us production-grade safety across the board, without requiring deep Kafka expertise from every team.
Conclusion
Consuming Kafka events and forwarding them to an external system sounds trivial, until you face transient failures, poison pills, and silent data loss in production.
Kafka Sink Connectors should be your first choice for simple pipelines. And when you need business logic with safety guarantees, Kafka Retryable Consumer is there to handle the complexity for you.
Open source & contributions
Kafka Retryable Consumer library is available as an open source project on GitHub:
The project is actively evolving and open to contributions. Whether you want to report issues, suggest improvements, or contribute code, feel free to get involved.
Contributions, feedbacks, and real-world use cases are always welcome!
This library is part of a broader effort at Michelin to simplify Kafka usage and promote best practices. You may also want to look at KStreamplify: https://github.com/michelin/kstreamplify.