
Rebuilding for Growth: A Microservices Architecture Evolution

{kind=link}
I previously talked about a mainframe application that we rewrote as a microservice based application. This project was a success and led to a lot of confidence from the users. So, naturally, we started to add more and more functionalities to it, not always related to the product initial goal. So much so that someone suggested that it was becoming a “black hole”. As we were not seeing any ending to that growth, we knew we had to modify the architecture before suffering from a growth crisis.
Initial architecture
The initial architecture had a central micro-service that contained the header of all the main objects of the application and oversaw the lifecycle of them. It was also a sort of translation layer that can transform an UUID into an object id card, with in particular its type. This information is crucial to know where the rest of the data for this object is located. This service usually provides links to the right service, for more information. All the micro-services were hosted in a single Kubernetes namespace, a single PostgreSQL database server with a database per service and an ElasticSearch cluster were used.
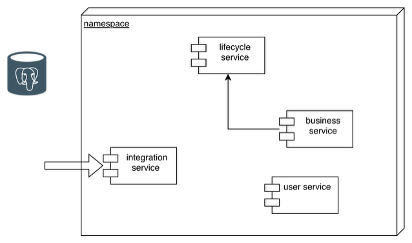
The new architecture
The idea was to partition the system between sub-applications and to regroup the common services in a platform that can be used by each application of the ecosystem. Each new application would be a coherent domain (as defined in domain driven design) and each microservice is a subdomain. The platform contains the user rights management service and most of the interfaces to systems outside the ecosystem. After the partition, each application is isolated in its own Kubernetes namespace and has its own database. To preserve the way the initial application worked we had to deploy an instance of the life cycle management service in each namespace, to handle the objects of the application.
But this led to an issue: if an application needs an object from another one of the ecosystem it has no way to translate its UUID into interesting information, since the central service is not central anymore and has only the objects of its (sub)application. So, we need to have a way to be able to cross boundaries. Different options have been proposed, including:
- Make all instances of the life cycle service (from each namespace) communicate, when necessary, through an event bus (like a Kafka topic) or through API. A service would broadcast its query and the service that knows the object would answer, if no one knows the service can deduce that the object does not exist
- Create a “cold” lifecycle instance in the platform which would know all the objects of the ecosystem: when a service needs an object it does not know it can defer to it. The cold instance could not be used to create, update or delete data, only to read it.
The second idea was chosen, particularly because some objects coming from outside also required the lifecycle management (even in this case it is just cold data).
To find an object (by its UUID) the process for a micro-service (or a front end) is then to call its designated lifecycle service, which if it can’t find the object in local will call the platform lifecycle service. That way the complexity is hidden for most microservices.
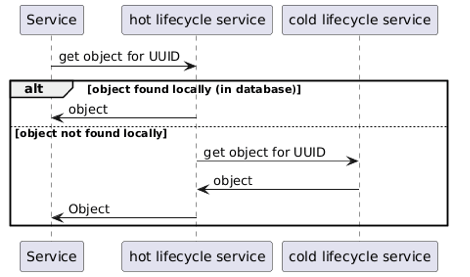
But this leads to another challenge: we need to synchronize the data, in real time, between each “hot” lifecycle service instance and the one in the platform.
Synchronizing data
The database we use is a PostgreSQL database. There are multiple options to synchronize the data:
- We could create a custom process, as we know exactly the objects we want to synchronize: each hot instance could write in a Kafka topic each time there is a creation, update or deletion, the cold service could then read the data in the topic and update its database. This solution requires a lot of custom code and tests.
- We could use a tool dedicated to change data capture, like Debezium.
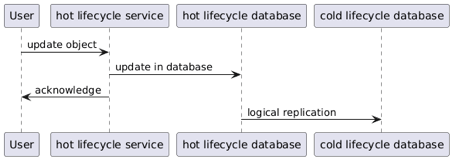
- We could use PostgreSQL own logical replication system to synchronize the two tables we need.
The third option was chosen for its simplicity. It requires no custom code in the “hot” instances, it is easy to implement and requires no new components contrarily to Debezium (no service to deploy, no topic…). In the cold service we created a schema for each replicated application, and a view to search in all of them, that way the synchronization is imperceptible for the service. One of the weaknesses of the PostgreSQL replication is that it fails if the schema evolves in the source and not the target. In our case this is not an important problem as the two considered tables are very stable (because they are at the core of the whole ecosystem since the beginning), nevertheless each update of the schema in the hot instances must be replicated in the cold one.
Regarding the elasticSearch cluster, in the new architecture we decided to keep a single cluster for all the applications. Indeed, some indices are shared between domains, and it is also sometime wanted to search through multiple indices, so a single cluster was a logical choice.
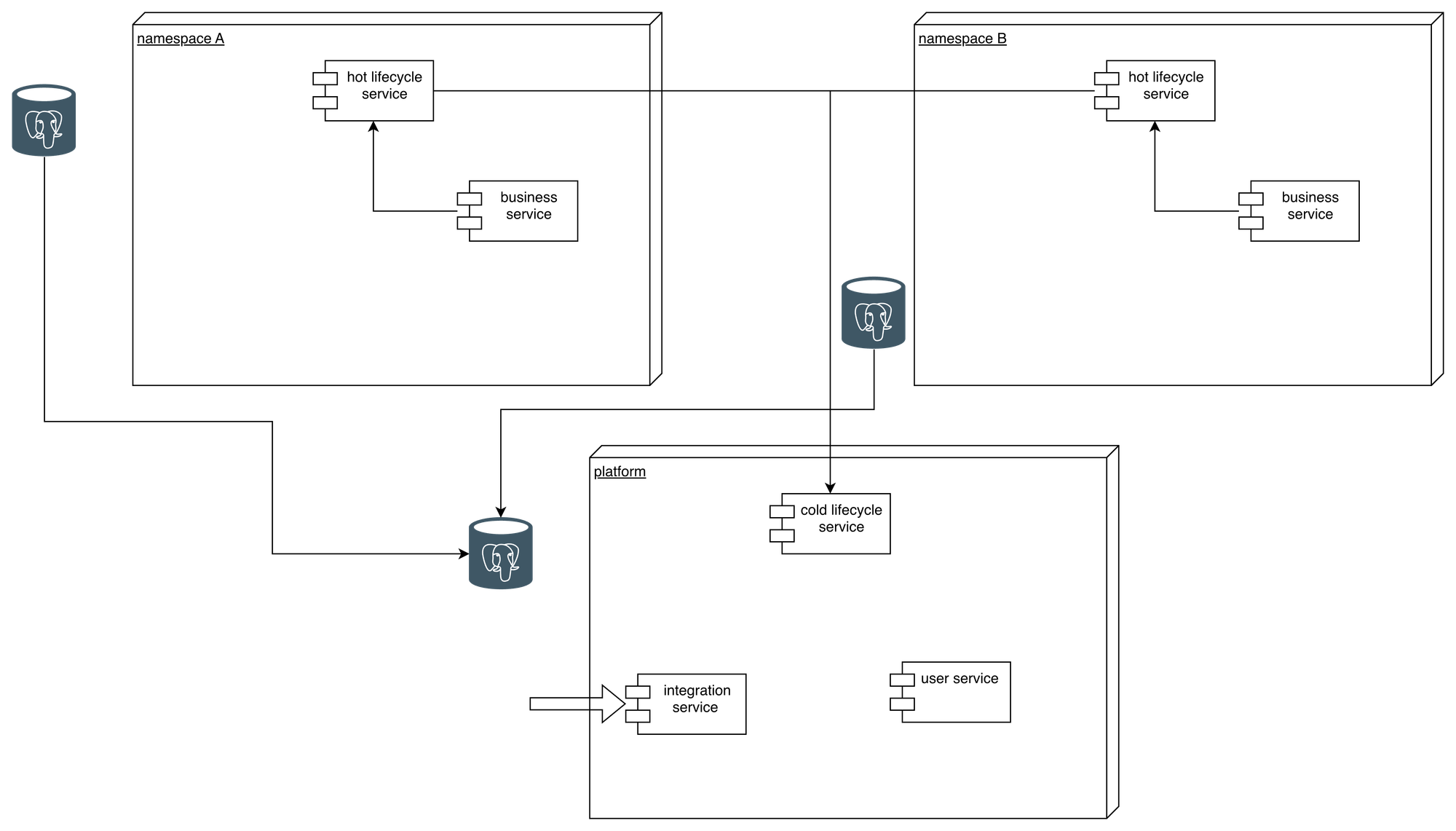
Current state
The solution has been partially implemented: the platform, the synchronization, the different namespaces have been created. But only the new domains have been put in new namespaces. The ones that were added to the original one before the new architecture have not been moved in their own namespace, because it is not a priority and seen as a purely technical task without any value for the end user.
The benefits
This architecture helps to solve some issue the original application had:
- The lifecycle service, as it is central, sees a lot of traffic, adding more domains meant more microservices, and so more calls to it, that means adding more replica to handle the load. If a service makes a lot of calls it could potentially crash, or at least have a significant performance impact on, the lifecycle service, this would lead to issues on the whole application (this happened and was also one of the reason of the new architecture, and it is one of the main argument regarding the value to move existing domains) . With the segregation in namespaces, an application can only overload its own lifecycle service, this prevents wider impacts.
- It reduces coupling between the domains, even if it does not prevent them
- It allows to organize the team in subteams focused on their own application (it is in essence team topologies): the initial team has been split in two teams, one dealing with the original application, one dedicated to the new domains
- It still allows to reuse code and components already written, helping the team velocity. All the common components are shared making it very fast to bootstrap a new application in the ecosystem. Another solution could have been a complete split (without a platform), this would not have this advantage.
- This allows to deploy independently each application, but there is a strong dependency on the platform. In particular, if a new application is created (with a new hot lifecycle service), a new schema must be added in the cold lifecycle database to allow the replication, and the view aggregating all the schemas must be updated.
Risks
Some issues could arise if there were a desynchronization between the hot and cold databases. For instance, an object could keep its old status in the cold service, leading to issues on rights that are evaluated on the status. This would be limited, as the services that manage the object always relies on their own hot lifecycle service. But this could create problems in some corner case scenarios, for instance if a user links two objects from different applications and should not have the right to do so because one of them does not have the right status for that operation.
It is therefore crucial that the replication is correctly monitored and that each schema modification in one of the hot lifecycle databases is also done in the cold database.
Conclusion
This architecture solved the growth crisis we were facing. It helped to keep the lead time in control, by giving more independence to the subteams, and to fight complexity (at least locally). Nevertheless, it has some drawbacks: the entire ecosystem is dependent on the health of the platform; modern tools like Kubernetes makes it quite easy to maintain that health but it is something that must be monitored. The initial choice to build the application as a microservice based one, and to strongly isolate the data between databases, has proven itself very useful and was key to build the new architecture, thanks to its flexibility and its reduced coupling. Finally, this architecture does not reduce the need of a strong architecture guidance to decide whether new domains should be added to the ecosystem, even so it is now easy to do.