
Rolling Out AIOps Without a Grand Vision: What We Did, What We Would Change

{kind=link}

AIOps is everywhere in slides and vendor pitches.
In real IT life, it looks more like this:
- IT managers: “Sounds interesting, but what’s the concrete value for us, right now?”
- Ops teams: “AI could help, but if I say we can save 30% time, does that mean 30% fewer people or 30% tougher KPIs?”
- Architects: “We don’t have final scope or KPIs yet, but governance still wants an architecture and risk assessment.”
- Global IT: “We already have a roadmap—are you aligned or building your own island?”
If these questions feel familiar,this article is a retrospective of how we started an AIOps initiative using Dify as a low-code AI app platform on AliCloud, and how we engaged these stakeholders along the way:
- What actually happened (the real sequence of steps).
- What turned out to be right.
- What we would reorder or do differently, so other IT teams (especially in other regions) can go faster and smoother.
We have not finished this journey yet, but we already have enough lessons to share.
Context: Local Need and Global Frame
From a local architect / IT operations point of view, several things came together:
- The LLM and GenAI ecosystem is now good enough for real operations tasks (summarisation, log analysis, knowledge search, workflow orchestration).
- Our environment already has monitoring and telemetry, ITSM (ServiceNow), and Kubernetes running on clouds.
- The volume and complexity of incidents, changes and manual checks is not going down when process optimisation and traditional automation have been done.
So locally I had a strong belief:
If we are going to try AIOps seriously, now is the right time to start.
At the same time, globally:
- IT has been running the “Game Changer” program for two years to make AI initiatives visible, support and coordinate them across IT teams, and avoid duplicated effort and fragmented solutions.
- At the start of this year, Our Core Technology Platforms announced to invest in a Model Context Protocol (MCP)–based approach to support AI initiatives across IT tools and platforms.
We talked with the global CSD (Customer Satisfaction Delivery) team and agreed that our local initiative would follow the central governance model, adopt the new MCP-based approach, and act as an early user rather than a parallel platform.
In my recent demos, I already used the first version of the MCP for ServiceNow delivered by the global team.
So the idea is not to build a separate China-only AI stack, but:
- Use Dify locally as a low-code “AIOps app builder” on AliCloud.
- Plug it into the global MCP ecosystem (ServiceNow MCP today, others later).
- Follow global governance while solving local operations pains.
The Actual Journey
To make the journey reusable, I’ll describe it as a set of “activity boxes”.
You can treat these as building blocks to adapt in your own region.
One thing to note: we didn’t have this neat flow on day one. It’s a cleaned-up journey we reconstructed afterwards from experiments and mistakes, and it is descriptive, not a recommended target flow—I’ll explain what I would recommend now in a later section.
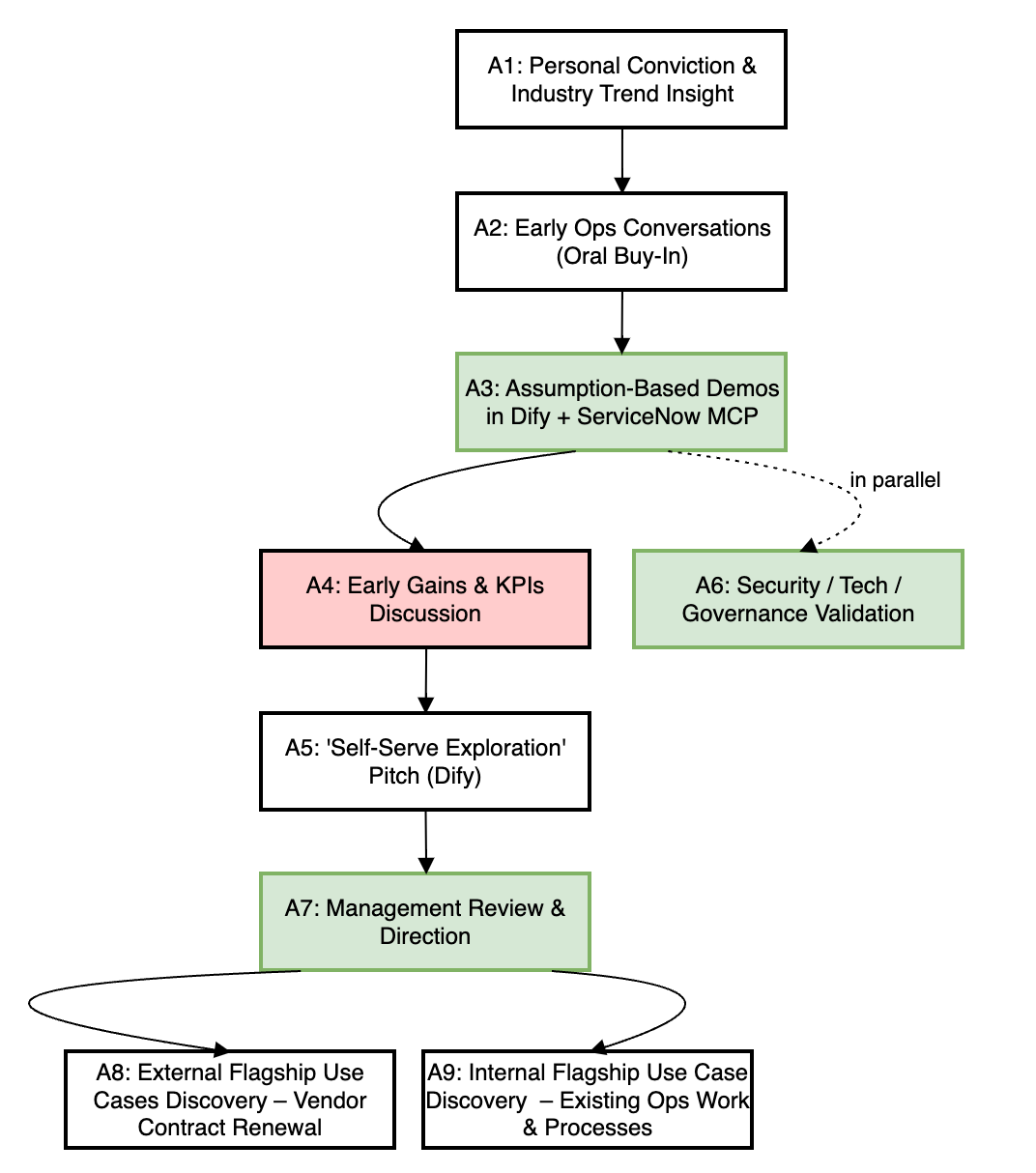
A1. Personal Conviction & Industry Trend Insight
As architect / IT expert, I form a strong view that AIOps is timely and relevant, based on:
- Industry trends and vendor roadmaps
- My own operations experience
- The maturity of our monitoring, ITSM and cloud platforms
I don’t need a full strategy here, but do need more than “AIOps looks cool”.
A2. Early Ops Conversations (“Oral Buy-In”)
Informal talks with operations teams (CloudOps, DevOps, platform engineers, etc.):
- “Do you believe AI could help your work in principle?”
- “Which areas feel repetitive or low-value?”
At this stage, we got soft agreement:
- People agreed AI could help.
- Nobody was ready to commit to numbers or formal objectives yet.
A3. Assumption-Based Demos in Dify (Using MCP Where Possible)
Next, I started building working demos.
Why Dify:
-
It lets me build bots and workflows without being a full-time application developer.
-
It’s good for wiring together:
- LLM
- Tools and APIs (including MCP tools)
- Workflows with branches, loops, conditions
Demos included:
- A chatbot for DBA support.
- A chatbot for Kubernetes admin tasks.
- Other “AI assistant for ops” flows across the IT support lifecycle.
Critically, in the ServiceNow-related demos I used the first version of the global MCP for ServiceNow to query tickets.
This significantly sped up demo development — we could wire ServiceNow into Dify and get a working AIOps prototype in just a few hours.
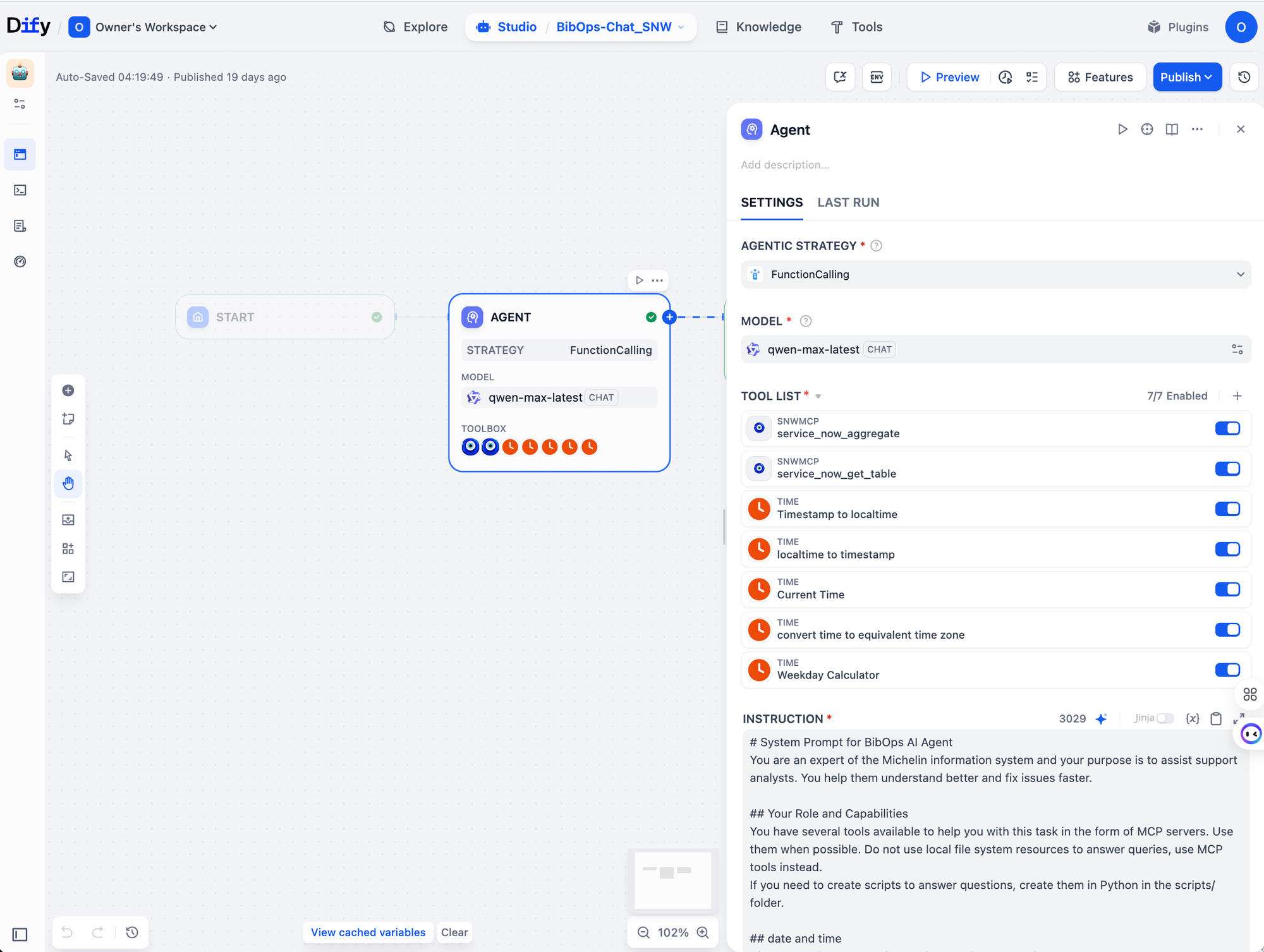
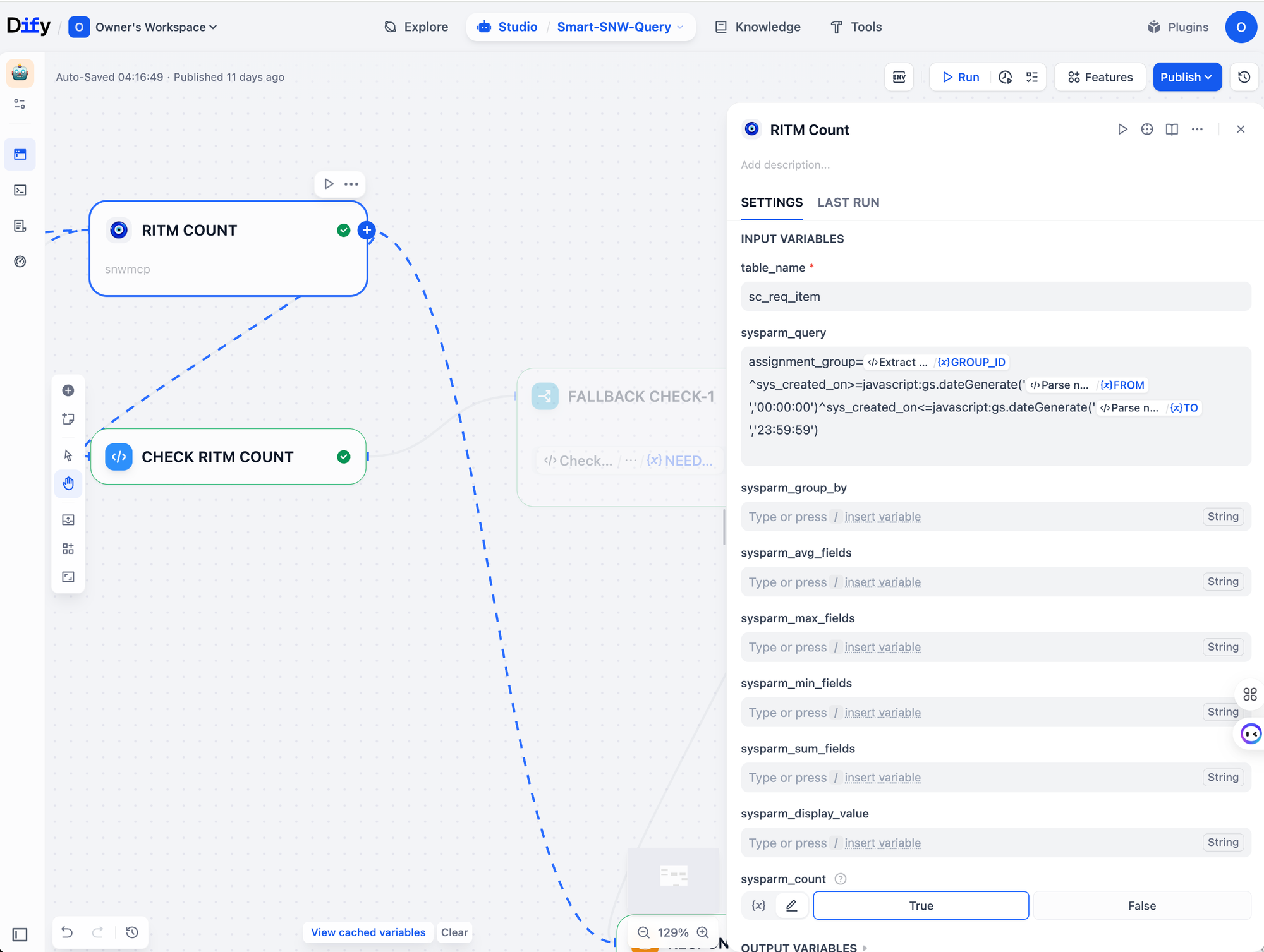
Figure 1 uses SNW MCP in an agent node, Figure 2 uses it in a Tools node.
These demos helped:
- Validate that Dify + MCP can implement real operations flows.
- Give ops teams something concrete to react to, not just slides.
A4. Early “Gains & KPIs” Discussion (Too Early)
After showing demos, I asked operations teams:
- “What real gains do you expect from this?”
- “Which KPIs could we improve, and by roughly how much?”
This is where resistance showed up:
-
People could not or would not give numbers.
-
Two fears were common:
- “If we say we can save 30% effort, will headcount be reduced by 30%?”
- “If we say MTTR can improve, will this become a hard KPI before the solution is mature?”
Result: no shared, quantified objectives.
Intent was good (we wanted measurable impact), but the timing and framing were wrong.
A5. “Self-Serve Exploration” Pitch (Dify as Low-Code Platform)
Because we couldn’t get numbers, I tried another angle:
“Let’s position Dify as a low-code platform for operations.
Ops teams can explore, build workflows and bots themselves.
Their know-how will be materialised in prompts, workflows and scripts.”
At this point, I started to explicitly highlight that:
- Dify is easy for non-professional app developers.
- It can be a sandbox where ops teams test AIOps patterns.
- Over time, operations know-how is captured and can be reused.
From a company perspective, this would:
- Build AIOps literacy in ops teams.
- Start making their tacit know-how explicit.
However, for the IT management, this argument alone was not enough.
It still sounded like “tool exploration”, not yet “solving clear operations pain”.
A6. Security / Technology / Governance Validation
In parallel, I moved on security and governance.
A natural question is:
“How can you go to validation and gate reviews when objectives and scope are not final, and when there is already a global AI program and MCP roadmap?”
We addressed this in three ways.
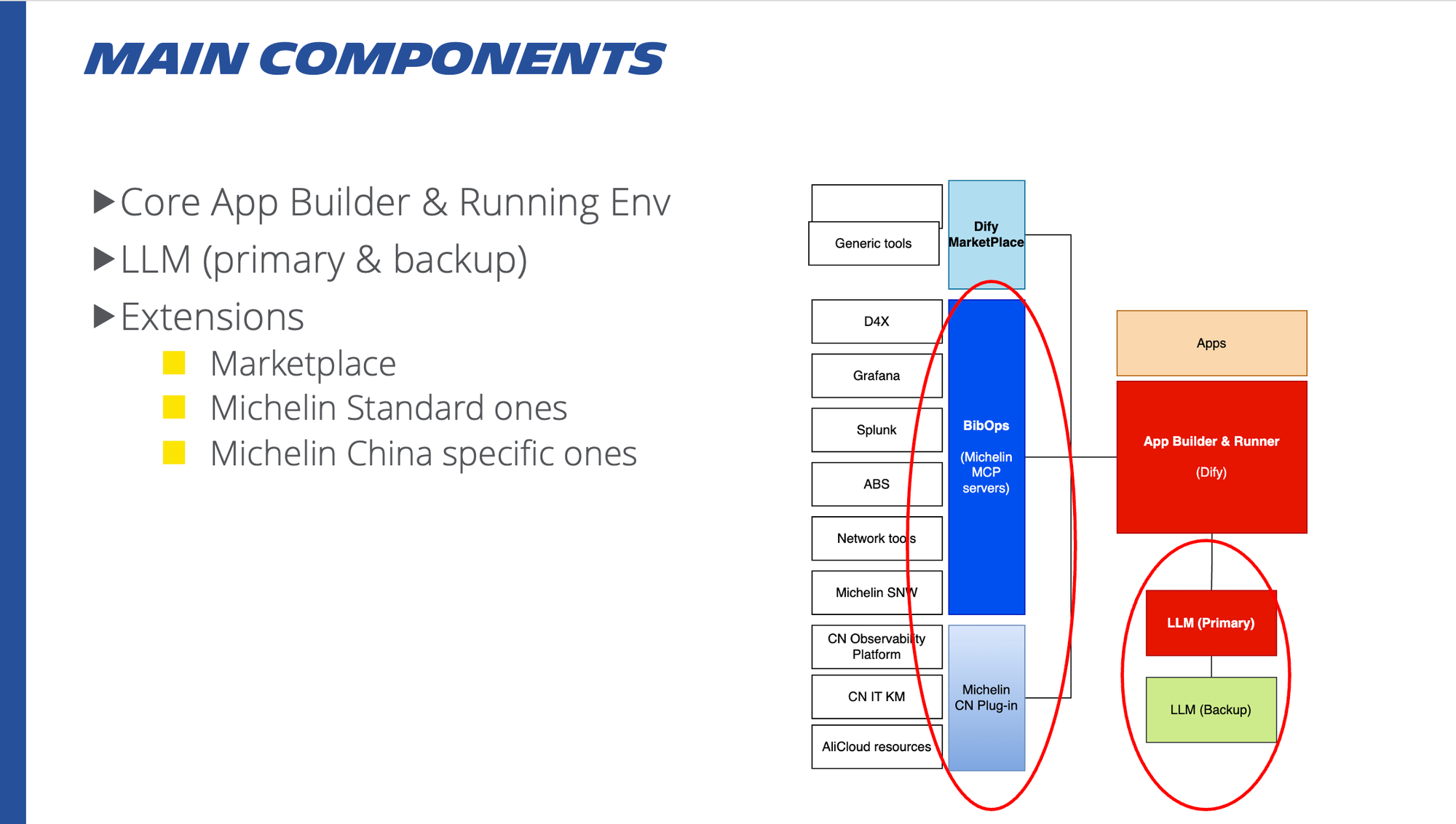
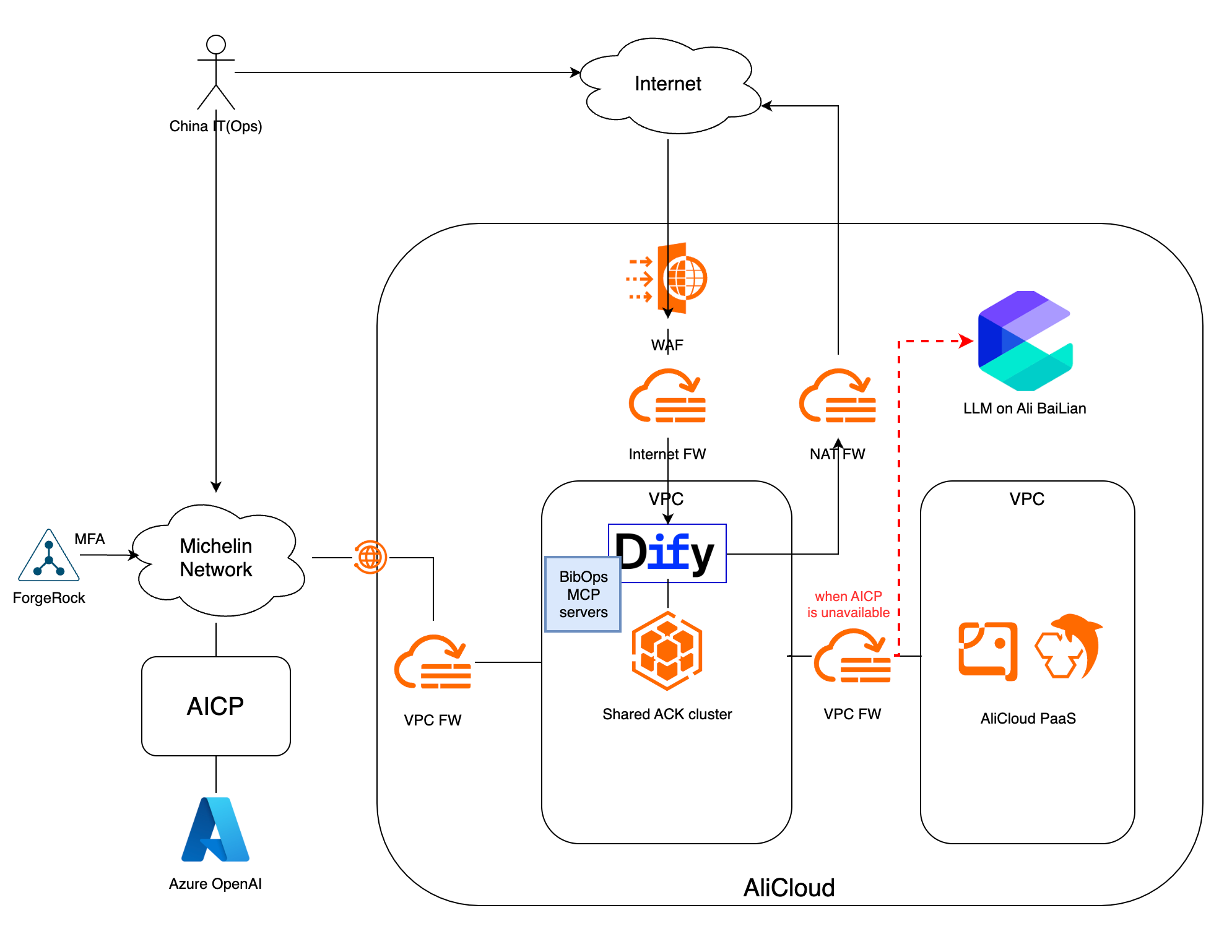
a) Modular architecture: pattern, not product
We defined a modular architecture:
-
App builder & runtime – currently Dify, deployed on AliCloud.
-
LLM “brain” – chosen LLM(s) for reasoning, summarisation, etc.
-
Extensions / tools – MCP-based tools and other integrations:
- Global MCP for ServiceNow, GitHub, asset list, IPAM, etc.
- Local MCP for AliCloud resources, local Observability Platform and China specific systems.
- Dify marketplace plugins for generic capabilities .
In the technical solution, we clearly stated:
-
App builder/runtime (Dify) and extensions are replaceable later:
- When global standards evolve, or
- When requirements show another tool fits better.
-
The stable part is not a specific LLM model, but the “LLM brain” role and its interaction pattern: an LLM orchestrator using MCP tools and workflows via stable tool contracts, workflows, and governance.
-
The know-how (prompts, workflows, tool-calling logic) is portable.
So we were not asking global IT to “bless Dify forever”.
We were asking them to approve an AIOps pattern built around MCP, where most value is in reusable logic and knowledge, not in the specific app builder.
b) Hosting and security anchored on AliCloud landing zone
For hosting and security, we stayed within existing standards:
-
Whatever app builder/runtime we use, we deploy it in the validated AliCloud landing zone.
-
We reuse mandatory security components:
- Secure network links to on-prem / other clouds
- Firewalls / WAF
- IAM/RBAC and SSO
- Logging and monitoring tools
Message to security and global architecture:
“We are deploying a new workload inside the existing secure architecture, not inventing a new security model.”
c) Data categories and sensitivity defined up front
Instead of defining data handling per use case, we:
-
Listed all data categories that this AIOps platform could realistically process across the SDLC:
- Operational know-how (hands-on), like SOP, Runbooks, Troubleshooting guides, Error dictionaries, Postmortems/RCAs, Change recipes, etc
- Environment/context knowledge, like service catalog, CMDB slices, runtime topologies, data flows, Golden dashboards, alerting rules
- Automation assets (stored externally), like remediation scripts, runbooks, workflows, APIs
- Governance and compliance, like policies, standards, etc
- People & processes, like ownership & escalation paths, operational calendars, vendor & platform notes
- External (public) intelligence, like vendor advisories & CVEs, best practices, etc
-
Using the Core/Non-Core standard checklist, we confirmed that we are not sending core business secrets or algorithms to this platform.
With that, we got:
- Architectural approval for the MCP-based AIOps pattern.
- Security approval for deployment on AliCloud landing zone.
- Data handling approval for defined categories.
This is the foundation global IT expects from regional initiatives.
A7. IT Management Review & Direction
When I presented the initiative:
-
The IT management did not block it.
-
But it is requested that, before a formal request:
- We work with the head of China IT operations to clarify value and expectations.
- We come back with objectives and scope that are jointly defined with related leaders
This turned the initiative from “good individual idea” into a sponsored exploration, but with the condition: value must be clearer.
A8. External Flagship Use Case Discovery – Vendor Contract Renewal
One obvious good place to look for flagship use cases is our external support contracts – not to “beat up” vendors, but to find automation opportunities that are win-win.
During renewal of an application support contract, we spoke with the China BSS (Business Systems Solutions) head and demoed the Dify + MCP–based flows. He immediately had several ideas, such as:
- Reducing manual periodic checks and reporting currently done by vendor staff.
- Using automation and self-healing to handle repetitive incident patterns.
So A8 is:
Channel 1: use opportunities like vendor contract renewals (or other external negotiations)
as a channel to discover AIOps use cases in the vendor scope, and then co-design automation with them
We focus on cases where:
- Manual work is clearly visible and measurable.
- Cost impact is direct.
- Political risk is low.
This gave us at least one strong external flagship use case candidate:
automating the periodic checks and reports currently performed by vendor staff, so their capacity can be freed up and redirected to higher-value work.
We are now waiting for precise numbers (frequency, volume, effort) from their side to size the potential impact.
A9. Internal Flagship Use Case Discovery – Existing Ops Work & Processes
In parallel, there is another channel for flagship use case candidates:
Channel 2: mine our existing internal work and processes.
Based on the pain inventory and existing ways of working, we can identify:
- Repeated manual tasks by internal ops teams (e.g. monthly health checks, standard reports).
- High-friction incident patterns (e.g. log-analysis-heavy incidents).
- Areas where people already try “shadow automation” with scripts or copy-paste.
One concrete example from this channel is a ChatBot for DBAs (see screenshots below).
It helps DBAs quickly:
- Check database health against a set of standard indicators.
- Evaluate performance based on slow query logs and top SQL statements.
- Suggest potential root causes for errors identified in the logs.
This was not just a theoretical idea: after the demos, the DBA team expressed clear interest and agreed to continue working with us to see how this kind of chatbot could be integrated into their real operations.
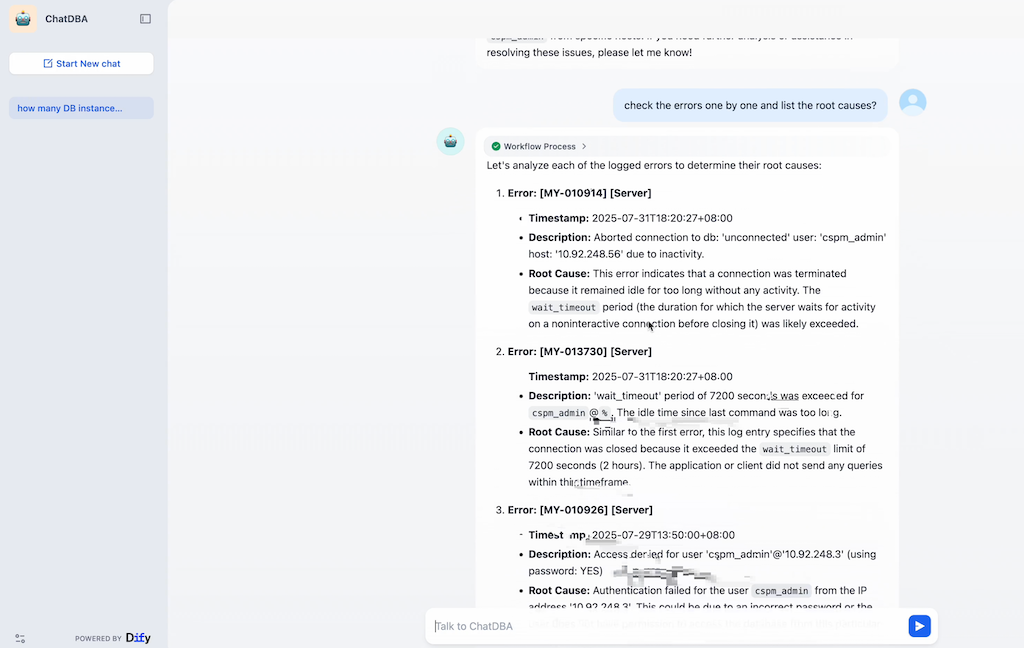
The next step, based on management's guidance, is to:
- Work with people nominated by the head of IT operations.
- Use this internal channel (A9) to list and rank candidates for AIOps support.
- Combine internal candidates with the external ones from A8.
From there, we plan to define:
-
A small set of flagship use cases (e.g. one external + one internal).
-
A time-boxed AIOps exploration charter:
- Learning-first, not “KPI punishment”.
- With clear guardrails and simple metrics.
Other channels are also possible, for example:
- Repeated audit findings about manual checks or documentation.
- Recurring escalations to senior engineers.
- Repeated management requests for reports that are currently manual.
A8 and A9 are just two primary channels we started with.
Key lessons from Flow 1, the actual Journey
What worked well:
- Building real demos early with Dify and reusing the global ServiceNow MCP.
- Securing security / tech / governance approvals on a modular, MCP-based pattern.
- Staying aligned with the global governance model instead of creating a local island.
- Accepting the management’s condition to align with ops head and IT management.
- Recognising external contracts (A8) as a clear flagship use case channel.
- Preparing internal process mining (A9) as another channel.
What we would change:
-
We pushed for hard gains & KPIs (A4) too early, before:
- A clear exploration-oriented framing, and
- A formal charter with CIO and ops head.
-
We treated flagship use case as loosely defined pilots. In hindsight, we should have:
- nailed the AIOps exploration charter first, then
- used it to drive both external and internal flagship use case discovery (A8/A9) and to pick 1–2 flagship use cases.
-
We initially positioned “self-serve exploration” as a quick fix to scale adoption. We later realized it only works for teams with enough operational maturity. Next time, we’d use the flagship use case pilots to prove that maturity with a few teams first, and only then position self-serve (A5) as an optional, earned capability for them—not as the default entry point for everyone.
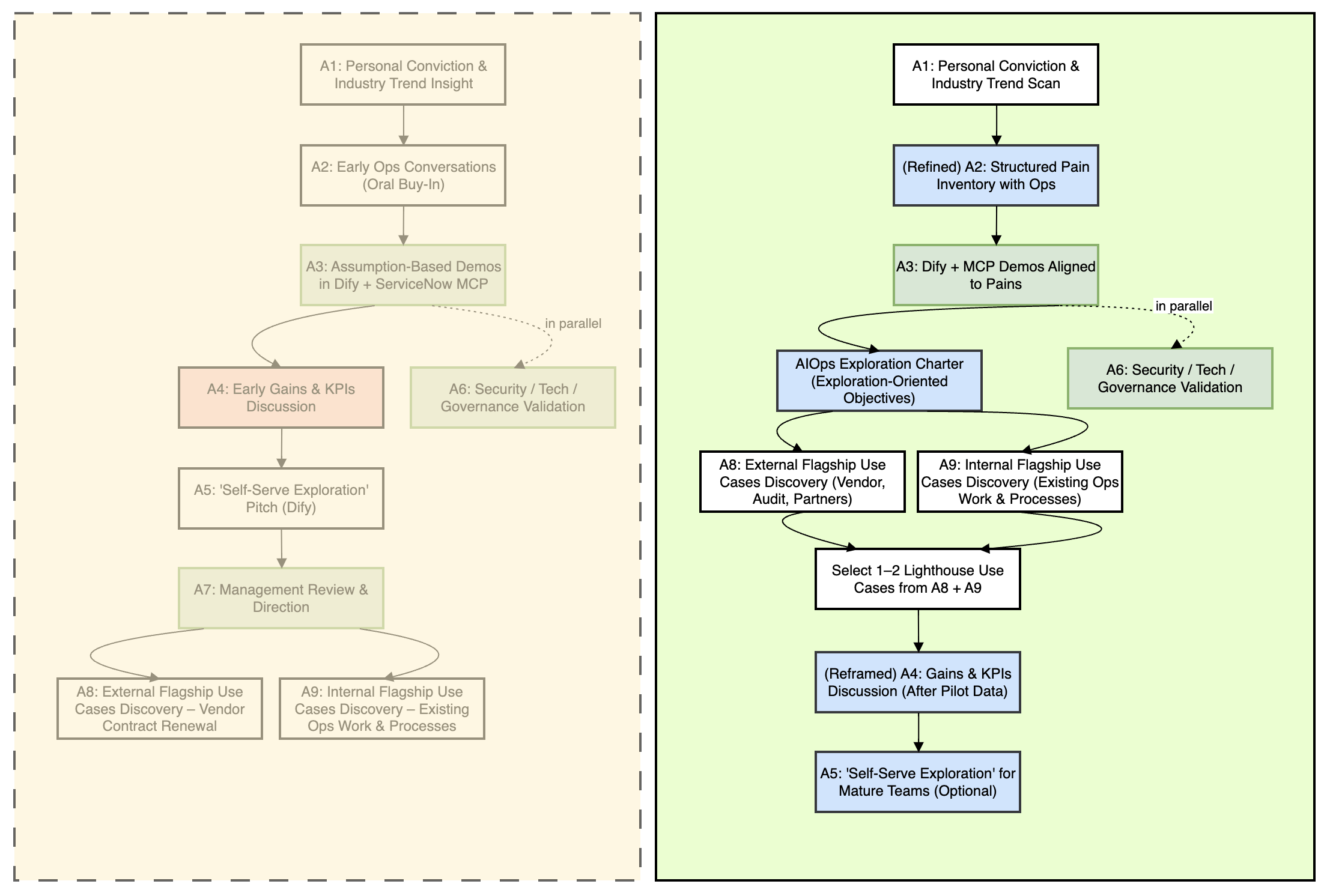
Flow 2 – Recommended Journey for Other Teams
Using the same activity boxes, here is how we would structure it if starting again.
4.1 Recommended sequence
A1 – Personal Conviction & Industry Trend Insight
(Refined) A2 – Structured Pain Inventory with Ops
- Short workshop with ops teams: list and rank pains and repetitive tasks.
A3 – Demos Aligned to Pains
- Build demos around the pains, not purely assumed scenarios.
- Reuse global MCPs (ServiceNow, GitHub, asset list, IPAM, etc.) from day one.
A6 – Security / Tech / Governance Validation (Pattern-Level, Aligned with global governance)
- Approve the pattern: LLM + low-code builder + MCP tools on standard landing zone.
- Clarify data categories and sensitivity in advance.
AIOps Exploration Charter (CIO + Ops Head)
Here is where we explicitly set exploration-oriented objectives.
The idea is: the first phase is not a “big-bang AIOps program”.
It’s a learning commitment with clear boundaries.
Example objectives:
- O1 – Reduce uncertainty, not promise miracles
- O2 – Prove technical and data feasibility on a small scope
- O3 – Materialise know-how into reusable assets
- O4 – Build confidence and guardrails
Even if flagship use cases are not very “sexy” or high impact, these objectives still make sense: they convert vague AIOps hype into concrete knowledge and patterns the organisation can reuse.
The charter should be:
- Time-boxed (e.g. 3–6 months).
- Scoped (1–2 flagship use cases from internal + external channels).
- Clear on decision points: at the end → Go / Expand / Stop.
A8 – External Flagship Use Case Discovery (Vendor, Audit, Partners)
Use renewal of:
- Vendor support contracts,
- Managed service agreements, or
- External audit recommendations
to spot flagship candidates:
- Manual checks and reports
- Repeated ticket categories billed by volume
- SLAs that depend heavily on manual work
A9 – Internal Flagship Use Case Discovery (Existing Ops Work & Processes)
-
From the pain inventory and existing processes, identify:
- Repeated manual tasks
- High-friction incidents
- Areas with “shadow automation” (scripts, copy-paste processes)
Select 1–2 flagship Use Cases from A8 + A9
-
Typically:
- One external (e.g. vendor manual checks/reports).
- One internal (e.g. incident summaries or triage assistant via ServiceNow MCP).
Even if each flagship use case individually is “small”, together they can:
- Validate feasibility.
- Exercise the whole chain: data → MCP → LLM → workflow → human.
- Feed back into the exploration objectives above.
(Reframed) A4 – Gains & KPIs Discussion After Pilot Data
Once pilots run under the exploration charter:
-
Measure:
- Time saved per task
- Noise reduction
- MTTA/MTTR changes (if any)
-
Then discuss gains based on real data, not guesses:
- “We saw ~X% reduction in manual effort for this report.”
- “On this service, MTTA improved by Y minutes from better triage.”
A5 – “Self-Serve Exploration” for Mature Teams (Optional, Later)
- Once the platform and patterns are trusted, gradually open more self-service capabilities for advanced teams.
- With guardrails: templates, reviewed workflows, approval flows for risky automations.
4.2 Recommended journey diagram
Takeaways for Other Regions / Teams
If you are planning something similar, a few practical points:
-
Don’t wait for a perfect grand vision.
Your first “Why” can simply be:“We want to test, safely and cheaply, whether AIOps can reduce pain in 1–2 concrete areas.”
-
Use exploration-oriented objectives.
- Focus the first phase on reducing uncertainty, proving feasibility, and materialising know-how.
- Treat flagship use cases as experiments, even if their direct impact is modest.
- Success is: “we learned what works and what doesn’t, and we have patterns we can reuse”.
-
Anchor early on global programs and standards.
- Check if you have something like Game Changer.
- Use existing MCP connectors (ServiceNow, GitHub, asset list, IPAM, etc.).
- Don’t treat MCP servers as “just API wrappers”. They are how your agents discover and call the right capabilities at the right time in a governed way. Your prompts and tool descriptions are part of that contract, so tune them deliberately. When you find prompt patterns that reliably trigger good behaviour, feed them back to the MCP server builders so they can package those patterns (defaults, examples, tool descriptions) and improve the MCP server for everyone.
- Follow the global governance model so you are seen as a pilot, not a side project.
-
Make the pain inventory explicit and early.
- Don’t stay at “AI could help in theory”.
- Run a short workshop, collect pains, and rank them.
-
Use a low-code platform as demo engine first, platform second.
- Dify helped us move fast and show real flows.
- Only later did we position it as a platform to encode know-how.
- The core is MCP + patterns, not the specific UI.
-
For governance, validate the pattern, not a fixed product.
- Separate app builder/runtime, LLM, and MCP tools.
- Make it clear that builder/runtime can change.
- Reuse standard landing zones and security components.
- Define data categories and sensitivity in advance.
-
Create a learning-first charter with CIO, ops head and global AI program.
Make it explicit that the first phase is about learning and reducing pain, not cutting people or tightening KPIs. -
Use multiple channels to discover flagship use cases.
- External channel (A8): vendor renewals, managed services, audits, external partners.
- Internal channel (A9): existing ops work, recurring incidents, manual reports.
- There can be more; the point is to look across both external and internal angles.
-
Discuss gains after you have some data.
- Early on, define direction and metrics.
- Once pilots run, use measured outcomes to shape the real business case.
We are still on the journey, not at the finish line.
But this path has already:
- Enabled an MCP-aligned AIOps platform in place on AliCloud.
- Passed security and governance under the Game Changer framework.
- Started concrete work with operations teams and vendors on flagship use cases.
If you’re about to start a similar initiative, I hope this helps you reuse what worked, skip what didn’t, and design a smoother path from “AIOps slide” to “AIOps in production” without falling out of sync with your global IT strategy.