
When AI help us find a strong password

{kind=link}

This article was co-authored by Edgar Peronnin, a Telecom Nancy student who wrote all the code, and Pierre Raufast, based on an initial idea by Maxime Escourbiac (CERT Michelin).
Why is a strong password important?
Password strength remains a key issue in cyber security. Indeed, password hashes are regularly compromised (via data leaks or attacks aimed at recovering them). If the password is weak, it can be recovered with its hash using specialized software such as John The Ripper or Hashcat. Once the password is known, the attacker has legitimate access to a resource, making it virtually undetectable.
For example: "password" has the following hash (SHA256): 5e884898da28047151d0e56f8dc6292773603d0d6aabbdd62a11ef721d1542d8
Simply choose a strong password
The answer seems trivial: ask the user to choose a "strong" password, i.e. one that is beyond the reach of specialized software. To do this, users can use their favorite password manager, which creates strong passwords. But let's be realistic: how many users actually use a password manager?
For the rest, there's the question of what constitutes a "strong password". Certainly, there's a question of entropy and length, and our security policies often impose rules: minimum length, lowercase, uppercase, special characters and numbers. But this entropy, while necessary, is not sufficient.

For example, Company !2024-05 respects all the rules but is breakable because it uses an obvious pattern: dictionary name + date (YY-MM).
Solutions do exist, such as measuring entropy at input or detecting the presence of prohibited keywords (trademarks, etc.). Unfortunately, even if these checks improve robustness, they cannot replace the billions of combinations tested by specialized tools. Worse still, they can give a false sense of confidence to users who have entered a password that respects all the rules but is weak. For example: MickaelJackson !2009
The truth is, finding a good password that's complex to crack but easy to remember is not that easy. So, we need to help users. But how? As we have seen, a simple indicator of compliance with the rules is not enough. It could even give a false sense of security.
It is also impossible, for reasons of computing time, to test the robustness of a password "on the fly" with adhoc software (unless we're only testing "compliance" rules, mostly based on a simple entropy measure - but, even if that helps, it's not enough to certify a strong password).
Artificial Intelligence to the rescue
We came up with the idea of implementing a Machine Learning model to help users estimate the strength of their password. Is it possible to learn from millions of known weak passwords?
Difficulties with supervised learning
The principle of supervised learning is to make the model learn not only weak passwords (dictionaries like RockYou list millions of them), but also strong passwords (for which, by definition, there is no database 🤓).
The first step was to generate strong passwords that were also realistic (i.e. imagined by humans, not password managers).
We used various algorithms based on words in the dictionary, with letter permutations, syllable insertions, leetspeak and so on. For example: Pomme95Mujer%, Comp2002Probl#, FraiAchi154+, Mundo!Part4
Next, all words are converted into numerical values (ASCII code). For example, portugal93 becomes:

With a model like Scikit-learn RandomForestClassifier or a neural network (MLPClassifier) we get excellent results (99%) ... in deception. In reality, the model has only learned our patterns for constructing good passwords! A purely invented strong password will be perceived as weak. For example: MOT2passe% (or CAR2nists%) is considered strong (resembles one of our patterns) whereas E9-LM14zyak2 is considered weak.
We then added meta-data, such as Jaro-Winkler and Levenshtein distances (similarity between two strings of characters), number of lowercase, uppercase, digits, special characters, Shannon entropy, but with no further satisfactory results.
Finally, we used an approach with several neural networks, each giving a score on a simplified version of the password: lowercase only, leetspeak converted to letters, etc. However, this approach revealed the same weaknesses as the previous one.
In conclusion, supervised learning is hampered by the absence of a dictionary of "human" strong passwords.
Unsupervised learning
The idea is to work only with a large volume of weak passwords and calculate clusters (built automatically on patterns defined by the model).
The distance of a new password from the center of each cluster will give us an indication of its robustness. All that remains is to find the right "threshold": strong/weak.
We've opted for AgglomerativeClustering, a hierarchical clustering system whose operation we'll understand from a few examples:
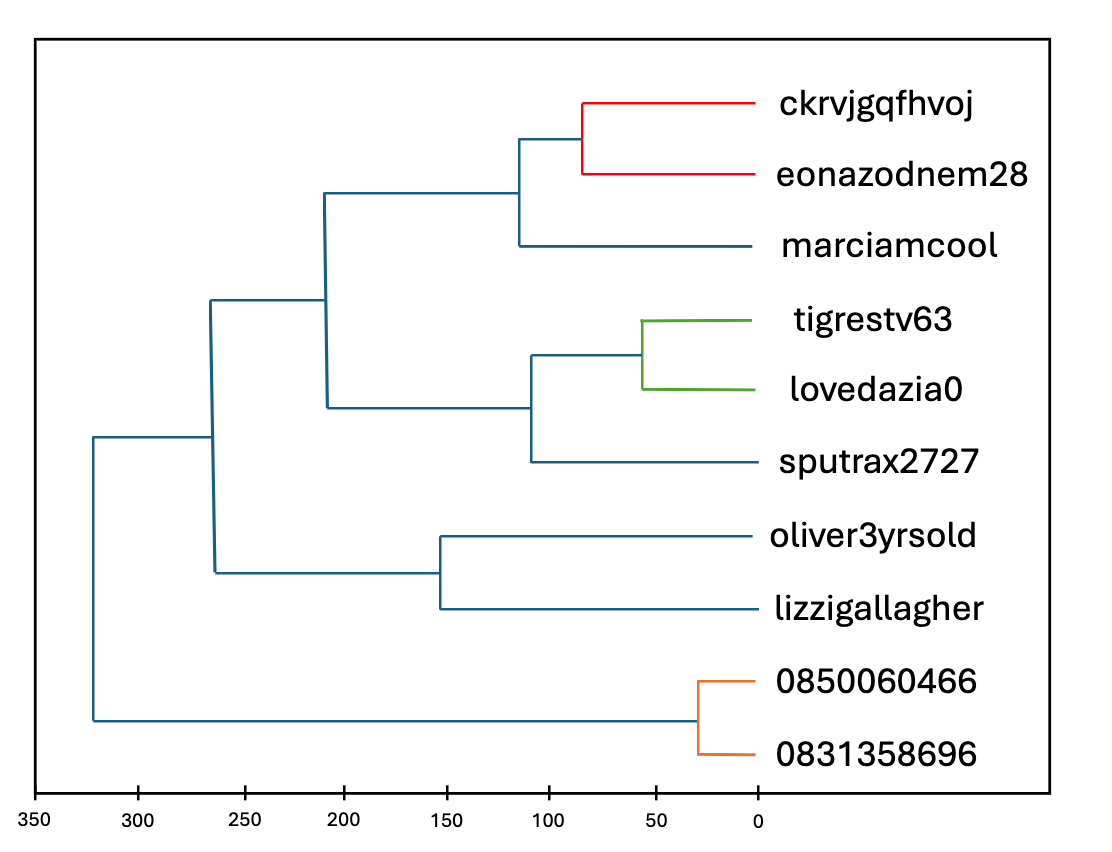
We found too many clusters, most of them of poor quality, i.e. not representative of a pattern. The silhouette score (a value between -1 and 1 that quantifies the independence of the clusters, i.e. the quality of the pattern) has a value of 0.21.
In itself, it's not shocking to have a slight superposition of clusters, but the context here tells us that passwords as text is too precise (too many possible combinatorics). We therefore simplify the model by using a mask rather than the literal password. Idea is to focus more on the "model/pattern" than on the literal word. M for upper case (2), m for lower case (1), and so on.
Portugal93! becomes MmmmmmmmCCS,
Conversion to numeric:

With this nomenclature, patterns start to appear:
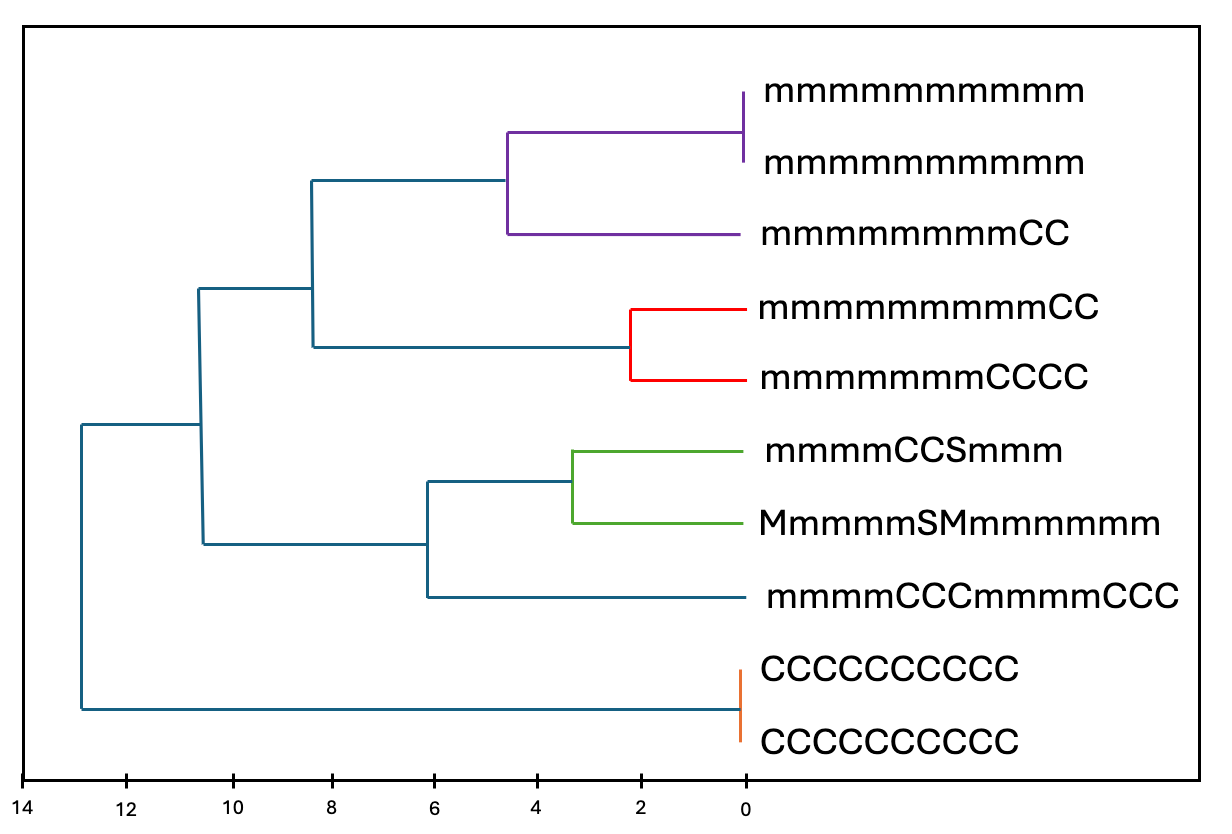
First results
With a threshold distance of 8 between 2 clusters, the algorithm finds 518 clusters for 50k input passwords.
The barycenter of each cluster is stored. This list is used for a new input: the NearestNeighbors algorithm gives us the distance to the nearest center of gravity of a cluster in the list.
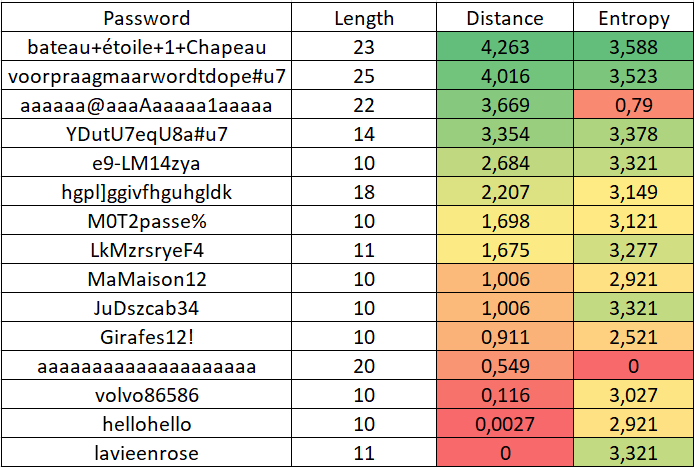
The (Shannon) entropy column is added to check for possible correlation.
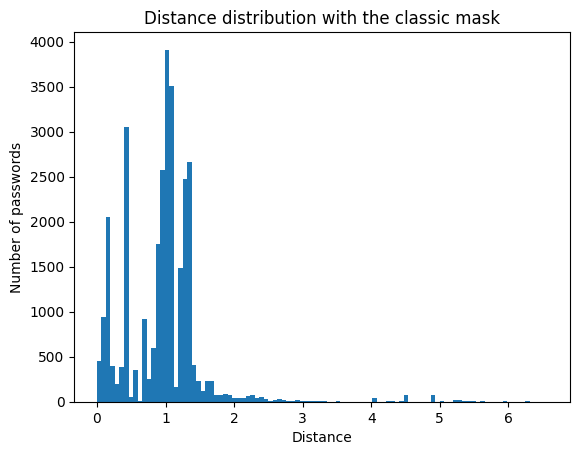
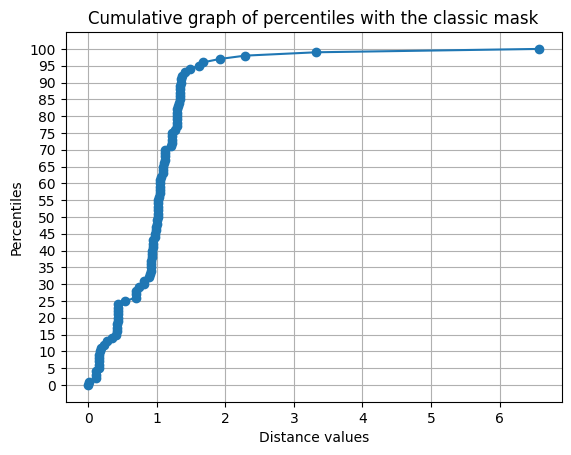
Among 30,000 newly compromised passwords, 97% have a distance of less than 2 from one of the cluster centers.
Model improvement
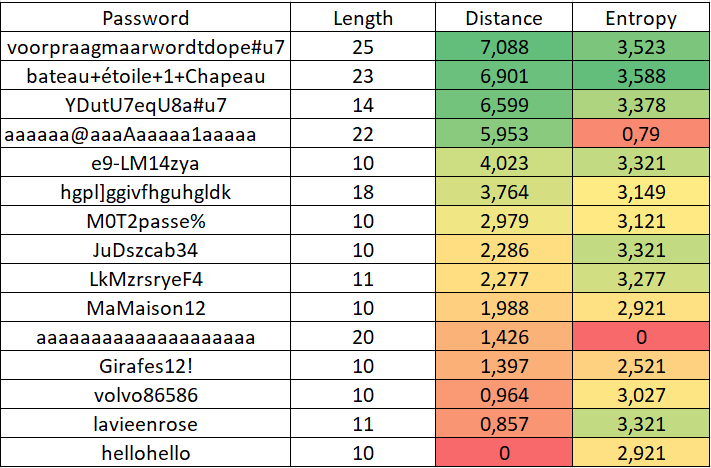
The problem with this mask-based algorithm is that it doesn't differentiate between a dictionary word and a random sequence of letters. MaMaison12 (MyHouse12) and JuDszcab34 have the same score, which is not entirely satisfactory.
We have therefore improved it by distinguishing letters and special characters by their frequency of use (low/high each time) in English/Spanish/French languages.
|
1 |
e, s, a,
i , t , n, r, u, o, l |
5 |
Numbers from0 to 9 |
|
2 |
other lowercases |
6 |
>,<,-,?,.,/,!,%,@,& |
|
3 |
E, S, A,
I , T , N, R, U, O, L |
7 |
Other special characters |
|
4 |
other uppercases |
0 |
padding |
For example: Most frequent letters (e,s,a,i,t,n,r,u,o,l) = 1 otherwise 2
This gives Portugal93!

The same cluster learning with this new refined mask, gives better results. JuDszcab34 becomes more complex than MaMaison12. The distance distribution starts to look like a Gaussian.

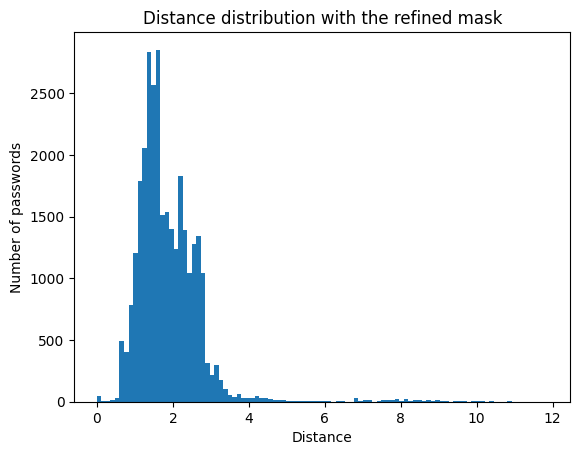
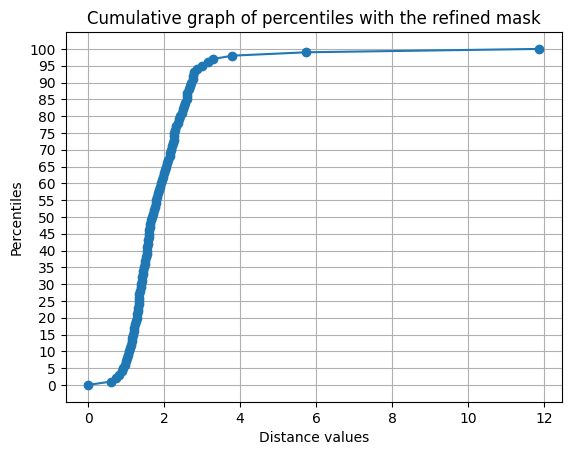
98% of passwords have a distance of less than 4. The silhouette score is between 0.3 and 0.4. This is still acceptable, where the variety of possible passwords means that we can be close to several clusters.
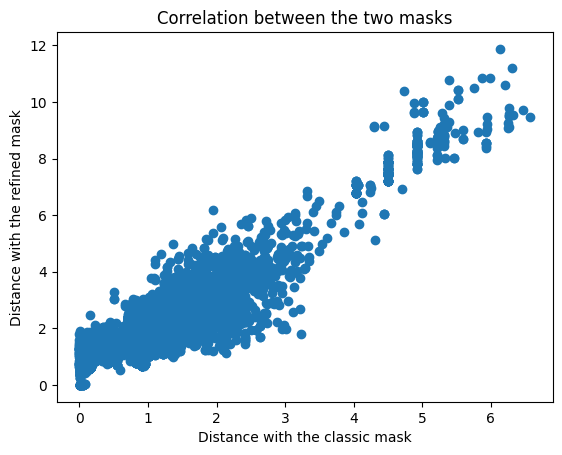
Model validation
To validate the model, we need to test it with "good" passwords. To do this, we use the crack-resistant passwords generated by our algorithms (the one used for supervised learning). We sort them by length to avoid bias:
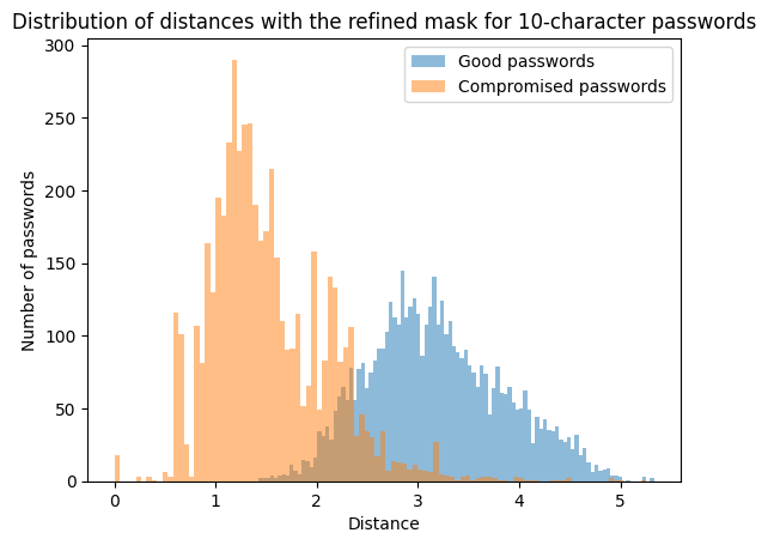
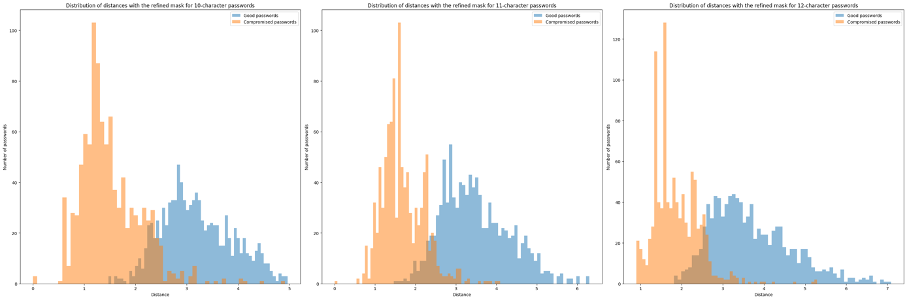
These results validate that the unsupervised learning model recognizes both weak and strong passwords (2 distinct curves). The overlap between the 2 curves enables us to define an acceptable distance that minimizes the risk of error.
However, we still need to test the approach with real strong passwords, i.e. those devised by users. The difficulty lies in the fact that we have no dataset!
One approach we are considering is to calculate the distance of each new password when it is renewed, and then compare it with the results of periodic cracking campaigns. In this way, we can "tune" the "strong/weak" threshold distance.
Going further...
Once the model has been validated and the threshold distance well defined, the idea is to propose a confidence indicator to users when they change their password. This will give a better overview than the classic entropy evaluation we see most of the time.
This is the ultimate goal of this work, to achieve a real-time password detection capability to guide the user.