
Self Service BI Development - Value Generation or Chaos Management? - Part 1


End user development. Increased adoption of the Power Platform. Empowerment. Data literacy. Do-it-yourself reporting.
These are all hot button topics in both our business intelligence department, our greater IT department, and beyond into the business. And why not? The company's goal is to make intelligent and informed business decisions backed by data. We have incredible product squads within our BI department that deliver great results to their business stakeholders. But they can't do everything.
The emergence of simpler user interfaces and more accessible BI tools has greatly empowered your average end-user. Gone are the days where one had to resort to 1) learning how to code, 2) making a friend in the IT department and calling in a favor or 3) resorting to Excel or Access.
As a result, why not put that knowledge, responsibility and technical capability directly in the hands of those closest to the business processes and related information? Provide access for these tools, provide some training and let the business run with it.
Is this the answer? As a full-stack architect, I answer with an architect's favorite two words: it depends.
I wrote a post a couple years ago when I started in this role, and I mentioned self-service as a vague goal among many other pieces of becoming data-driven. I want to focus more on self-service BI development in particular in this post. More specifically, an individual project that has influenced my view on it, and what we're doing technically in that case. This blog post is part 1. I'll cover the project, problem, and immediate plan to industrialize this. The project is still in its infancy. In part 2, I want to address this from a larger approach and cultural standpoint, as I found myself asking many times during this analysis: how did this happen, and how can we prevent this from happening in the future?
To be clear, the goal of the post is not to advocate for or against self-service BI work, because in my opinion that is pointless. It's going to happen with you or in spite of you, but it's going to happen regardless.
Beginning of 2024, I was approached by a new product owner in our department. "Matt, we need some architecture guidance on the feasibility and effort required to industrialize this PowerBI tool. I'm going to send you a meeting invite." These requests always make me a little nervous; I have no idea of the scope of what I'm walking in to.
I enter the meeting, and am presented with a very high level functional diagram. There is no documentation on the current solution, so some items are educated guesses to be investigated further. I'll show the original rough drawing below with some names removed or changed. There is a process for taking sellout data from customers, cleaning it up, feeding it to our legacy mainframe, correcting potential errors in addresses and customer information, sending the corrected info back to the mainframe, and then feeding this information to several BI reports, along with a couple other systems. The process is error-prone and involves regular manual intervention and processing from two people in the business who aren't really responsible for managing technical processes. Hence the request for architecture guidance. Two things to note: we have an application that processes EDI data from customers. I've code-named this Emerald. Michelin also has a global ecosystem for data storage, aggregation, manipulation and reporting. We call this our Corporate Data Lake. You'll see this abbreviated as CDL throughout this post.
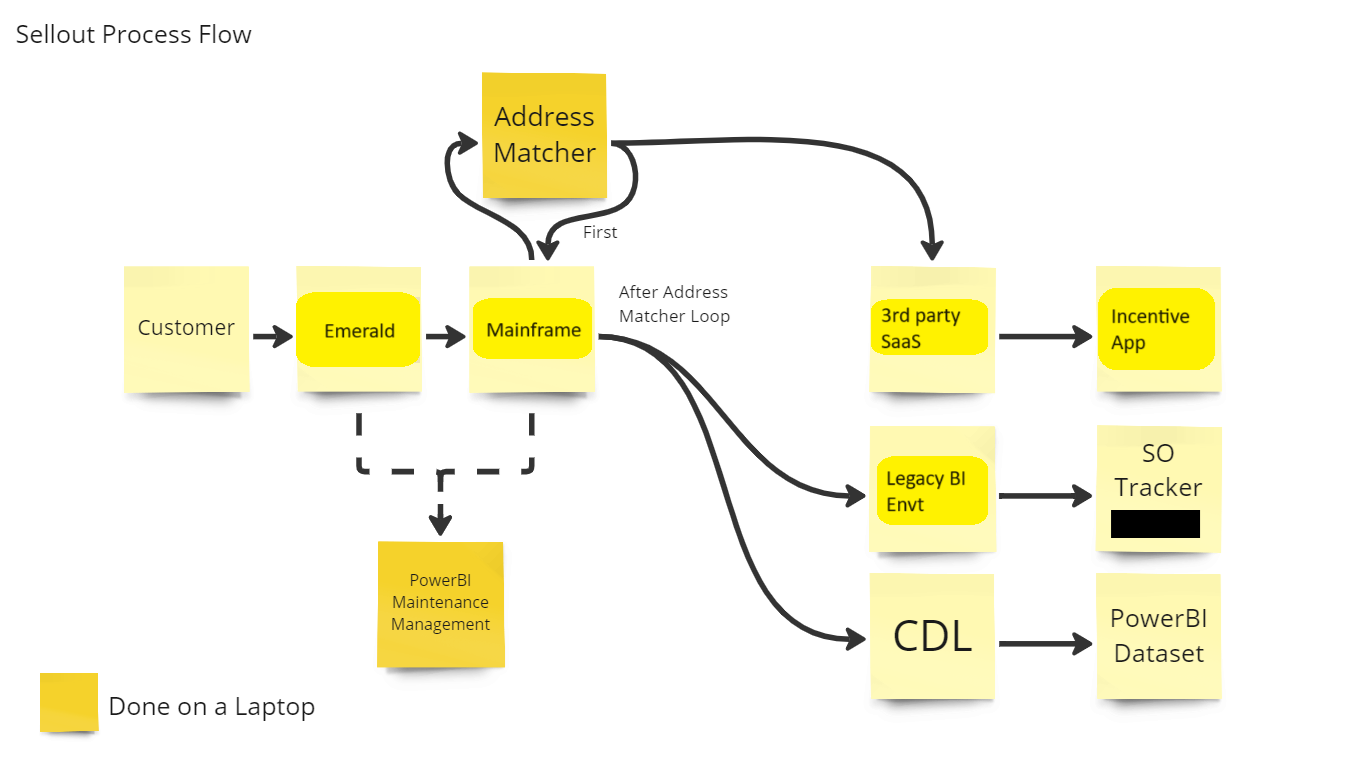
I took the action item to work with the two business analysts and find out more about the process. I could then propose an architecture and provide a high level estimate on effort.
I met with the business analysts that work with this program on a daily basis, and they provided me rights to view and edit the same things they could. They were also kind enough to give me a crash course of how they interact with the ecosystem and what they know about it. I also met with the mainframe team about how this interacts with our legacy system. Then I started digging in myself.
I won't bore you with all the details of analysis, but I will tell you it involved many cups of coffee, energy drinks, and a little ibuprofen for my headache. Here are some facts about the existing solution:
- 40 Power Automate jobs, all connected in some way
- 38 batch scripts, most of which are triggered by the Power Automate jobs
- Batch scripts with the sole purpose of writing another script to move data to or from our mainframe
- A Sharepoint site, used as a clearing house for any file manipulation, output and storage of these batch scripts
- Multiple daily points of manual intervention by business analysts on their laptops
- A private team area on our CDL
- No documentation
The Problem
For those working in or around IT, the above bullet points probably made you think of a dreaded term: Shadow IT.
For those of you unfamiliar, Shadow IT is a concept that's been around as long as IT departments have. And it exists in some capacity in most companies.
A team has funding and enough know-how to be dangerous. They find the process to engage IT too cumbersome, they dislike a lack of autonomy, they think IT is too slow, they don't even know what the process is, etc. There are many possible reasons. So they go around the IT department and do it themselves. A small example - a team doesn't like the security restrictions around a server used for mathematical calculations around research and development. So they buy a high powered desktop PC, plug it in at a desk, install their required software and instruct their users to connect to that system (yes this is an actual example I saw in a previous job, for anyone curious).
This provides perceived short-term relief to this team. But what happens when the program this PC is running gains additional users, sometimes from different groups? How does this solution scale, and who pays for it? What happens when this PC starts to aggregate potentially confidential data and violates company security standards? What happens when a critical vulnerability needs to be patched? The situation gets well beyond the capabilities of the team, and no processes are in place to handle it.
I mentioned previously these new tools empower end-users, and I think that's a wonderful thing. But it also makes Shadow IT more accessible and dangerous than ever before, as it removes several previous barriers including funding and technical skills.
Shadow IT often results in the IT department coming in, taking ownership and redesigning the entire system to meet standards. The resulting project consumes far more resources than designing it to meet standards from scratch. Which is exactly what is happening here.
The Plan
I have several theories about how this Shadow IT solution grew to this point, but none change the current situation. We have an out-of-control system we need to replace, and that should be the focus.
We can debate between what is an ideal company solution and what can be done in a reasonable amount of time. But one thing is clear - the current solution is not reliable, not sustainable and not standard. Michelin has a standard data tool stack for industrialized data processing and reporting. This will be our target.
The elephant in the room - our legacy mainframe processing. Parts of this process were created to highlight when issues occur with this processing on the mainframe. I would love for this piece to be replaced by a new application, which would simplify the BI work. But this operational piece is entirely supported, architected, and owned by another domain in IT. The project manager has raised this issue with this team's management and the item is on their backlog.
The project team agreed to redesign all the parts of the flow focused around data quality and business intelligence reporting. The PM has negotiated time from the mainframe support team to provide information about that system's jobs when needed.
With that out of the way, cutting through the complexity of all these jobs and scripts, I can (over)simplify this process down to different permutations of 5 activities:
- Creating files
- Moving files
- Deleting files
- Manipulating files (cleanup and/or applying business rules)
- Triggering, either one of the above activities or sending a notification
We already have a toolset available through our CDL ecosystem to handle all these activities. The key will just be dividing it up, organizing it and documenting it. We also have a very mature data product team with experience on similar data processing writing the code.
Our CDL environment uses Azure Data Lake Storage (ADLS) Gen 2 for storage, Data Factory for orchestration and file movement, Databricks for manipulation and business rule application, and Event Grid (integrated in these other items) for event triggering. The ADLS has three levels of refinement - 10_rawdata, 20_datastore and 30_datamart, which correspond to the industry standard terms of bronze, silver, and gold respectively. Each of these is divided into subfolders, separated by either responsible team or application. With this provided context, here is a diagram of the to-be process below followed by an explanation:
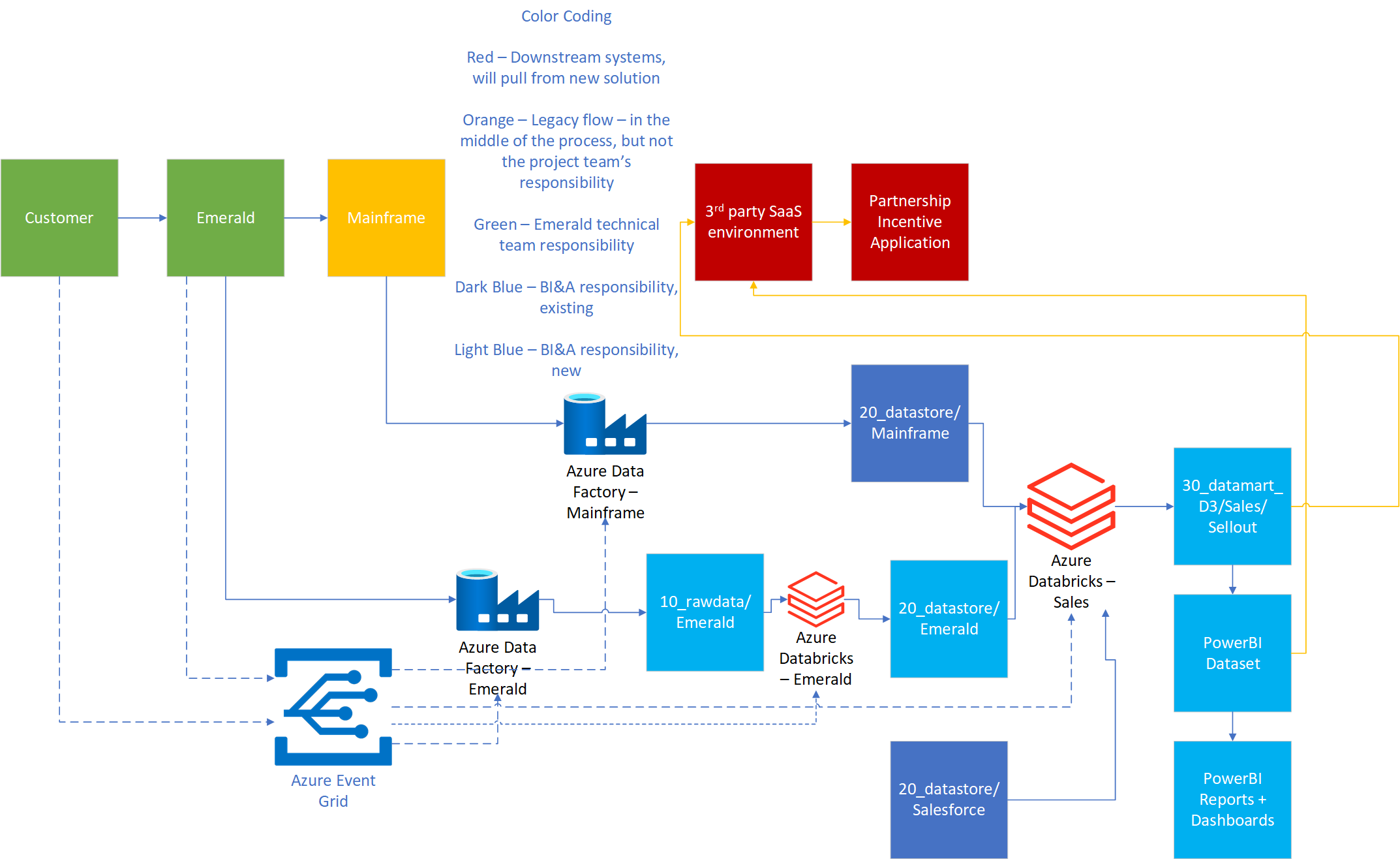
- Ingestion of data
- Customer data enters Emerald application. Responsible team for Emerald will forward customer data to 10_rawdata/Emerald in ADLS.
- Already processed data in the mainframe will go to 20_datastore/Mainframe.
- Cleaning of data
- The data engineers on the BI squad will format and clean the data using Databricks in 10_rawdata/Emerald. Output goes to 20_datastore/Emerald.
- Business rule application
- This will include two high level functions, both of which will go in subfolders of the same area.
- 30_datamart/Sales/Sellout/BI-Maintenance - activities to create the similar functionality for the datasets currently used for PowerBI maintenance tool dashboards
- 30_datamart/Sales/Sellout/Address-Matching - the address matcher Power Automate and script functions will move to Databricks, the output will go to the folder mentioned above
- Note: the team may be referencing an existing area of Salesforce data in our CDL, 20_datastore/Salesforce, as needed for BI work
I've also provided some required roles and capacity estimates to the project management team.
- Data engineering and development: 40 man-days
- Mainframe support staff (as needed): 5 man-days
- Transverse CDL support: 3 man-days
- Architecture: 5 man-days
The BI squad is now engaged in the project, and has time allocated to this as a priority. We just went through a sizing estimation exercise together, but haven't progressed into development yet. But I feel optimistic we have a clear path to fix this particular issue.
Wrap Up
As for the overall approach around self-service development, what can we learn from this? Does it affect how we measure success? What tools users have access to? What level of access they have? What training is provided? What is the IT department's role in the whole thing, and what is its responsibility? There are many possibilities and no clear-cut right or wrong answers.
Be on the lookout for my Part 2 post where I share my thoughts around those questions and how this project has shaped them.