
Syncing on-premises Active Directory computer Distinguished Names to Azure Active Directory

{kind=link}

Transitioning device management to the cloud has been one of our strategic directions for years but has proven easier said than done. So complicated in fact, that we are still operating in 2024 with hybrid devices (Hybrid Azure Active Directory-Joined - HAADJ), attached to both on-prem and cloud Microsoft environments, which has resulted in unique challenges for us.
Introduction
As we turned to the cloud, it did not take us long to realize our traditional way of configuring devices through Active Directory Group Policy Object (GPO), relying on a hierarchical tree-like structure of Organizational Units (OU) to apply specific settings on machines, would not so easily be converted to the flat structure of Azure Active Directory (AAD) and Intune where everything is group-based.
AAD is no Active Directory (AD) and it shows. Right from the start we realized we would need to, somehow, carry over to the cloud the information previously given by the relative position of devices within our hierarchical structure of OU, as our GPO were based on this.
Originally our thought was to start re-creating a complex structure of groups representing the various OU layers we have in our Active Directory. Basically reproducing what we were doing on-prem in the cloud, turning all the OU in the originating directory into what would have been essentially a 1:1 mapping to AAD groups. While it could have worked technically, it looked like a nightmare to maintain from an operational standpoint... And did not feel right either.
We eventually came to the conclusion we were chasing the wrong rabbit. In truth, what we really were after when using Organizational Units in our Active Directory to assign configuration to devices, was the combination of information represented by the hierarchy of OU in the directory and the relative placement of devices within the tree.
Particulars such as geographical location of the device, its nature, its status as a Production or Standard device, its OS version, etc. were the valuable data reflected by the Distinguished Name (DN) of the object in the directory.
Here are 2 sample fictitious DN to illustrate, using the well-known contoso.com Active Directory domain:
Text representation
CN=T14s-21458976,OU=PAR,OU=FR,OU=EMEA,OU=OFFICE,OU=WORKSTATIONS,OU=CORP,DC=contoso,DC=com
CN=M70q-89756891,OU=LYO,OU=FR,OU=EMEA,OU=PROCESS,OU=WORKSTATIONS,OU=CORP,DC=contoso,DC=com
Semi-graphical representation
contoso.com (DC)
└── CORP (OU) <---- GPO could be applied here,
└── WORKSTATIONS (OU) <---- or here,
├── OFFICE (OU) <---- or further down the tree,
│ └── EMEA (OU) <---- on this EMEA OU for example,
│ └── FR (OU)
│ └── PAR (OU)
│ └── T14s-21458976 (CN)
└── PROCESS (OU)
└── EMEA (OU) <--- or this one !
└── FR (OU) <--- Anywhere, really ! :-)
└── LYO (OU)
└── M70q-89756891 (CN)Fictitious example showcasing the hierarchical structure of the directory and the variety of info that can be derived from the DN
To store them we decided to leverage the, then new, capabilities offered by AAD device extension attributes. Although we could have broken this down into a set of different properties, the flexibility offered by the formula for dynamic groups, allowed us to keep the DN "literally" as it was (no transformation). We merely had to "tap" into the information of that single attribute by targeting subparts of the DN string in dynamic groups formula.
A GPO applied in the on-premises Active Directory to
OU=EMEA,OU=OFFICE,OU=WORKSTATIONS,OU=CORP,DC=contoso,DC=com
in the previous example would become an Intune policy
applied to a dynamic group of devices in AAD with a formula of:
(device.deviceTrustType -eq "ServerAd") and (device.extensionAttribute1 -Contains "OU=EMEA,OU=OFFICE,OU=WORKSTATIONS,")Example group targeting HAADJ Office EMEA devices. Note the use of the , in the condition to avoid collision with, say, another top level OU that would start with "WORKSTATIONS"
At this point you may be wondering why we had to do this and did not use a built-in attribute. Surely there must be one available that contains the on-prem DN for synced computer objects ?
Well, mind you, what exists for user objects (the onPremisesDistinguishedName property) does not for devices... Why ? No idea but the schema is nowhere near as rich as it is for users. Thus we needed to come up with our own set of scripts to write the DN into each and every new hybrid device in AAD.
Syncing Distinguished Names
Our original approach to getting the info we needed, where we needed it, was a bit brutal to be honest. We periodically looked for new computers in our on-prem directory (based on the whenCreated attribute), matched them to the corresponding devices in AAD based on hostname, before eventually writing the on-prem DN as extensionattribute1 over there.
While this worked, and was "good enough" for the project we were working on at the time, we were very aware of the limitations of the implementation. When things settled down, it became evident we needed to do something to address the 3 main issues we were facing.
- It was far from being reliable, with misses related to timing issues between the script and actual sync of computer objects to the cloud (a part of the HAADJ process).
- It was rather inefficient, in fact quite heavy in the query department needing periodic lookups of tens of thousands of objects (overall) to single out newly created computers.
- It did not handle (at all) subsequent moves of computers objects once the DN had been written on a cloud device.
After giving it some thought we reversed our logic: instead of querying our on-prem AD, we created a dynamic group in AAD targeting only HAADJ device objects that had an extensionattribute1 that did not contain our organization name (which is part of the DN). Our PowerShell script then only had to periodically list the content of that group, look for the DN of the originating computers in our on-prem AD, finally writing it in the extensionattribute1 of the corresponding cloud devices.
Dynamic formula used:
(device.extensionAttribute1 -notContains "orgname") and (device.deviceTrustType -eq "serverAD")Dynamic formula for the AAD group we are periodically polling. Note the use of -notContains which could certainly be improved as it is not the most efficient operator
No more timing issues as we were only targeting HAADJ devices by design, no more heavy queries, a much smoother and reliable approach. However, one challenge remained: handling of computer moves past the initial update of the attribute in the cloud.
Although not a common occurrence in theory, the particular situation we are in right now when it comes to computer imaging, coupled with the natural movement of computers in our environment, especially between Production and Standard branches, meant that if left unaddressed we would keep drifting.
And indeed, a one-time reconciliation effort ran recently highlighted the extent of the problem: thousands of machines did not sport their current on-prem DN in the cloud anymore. Which meant incorrect configuration of the devices, including non-obvious side effects resulting in wasted time troubleshooting and fixing issues...
Addressing the final challenge
To put it simply, we essentially saw 3 different ways out of this one.
Big data: a periodic reconciliation where we would basically query both directories for computer objects / devices, compare DN to value found in extensionattribute1, look for discrepancies and correct them. A variant would have been to run differential extracts on our on-prem AD, determine which computers had moved in-between, to update them afterwards in the cloud. Technically possible but of course heavy handed and cumbersome in both cases. Also could not be run often given the amount of time it takes to retrieve and process the data. Would be our last resort.
DN attribute change: focus only on these computer objects in AD that have had their DN changed recently. Idea was to query attribute metadata on computer objects, find out when the DN was last changed and from there overwrite the content of extensionattribute1 on corresponding cloud devices. Worked well for... plenty of things except the DN, which of course turned out to be no ordinary attribute. Too bad, because this solution looked like a strong contender. Commandlet below if you want to have a look. Definitely something interesting to keep in mind because even though we could not use it here, it could come in handy in other situations. See this link for more info.
Get-ADReplicationAttributeMetadata -Object "fullDN" -Server yourDC | Select-Object -Property AttributeName,AttributeValue,FirstOriginatingCreateTime,LastOriginatingChangeTime,LastOriginatingChangeDirectoryServerIdentity | Out-GridViewTracking attribute changes through PowerShell
Audit trail: use of Active Directory's auditing capabilities. Since there seem to be events for just about anything, why not track moves? Fortunately it just happens there is an event specifically dedicated to this, that conveniently lists previous and new DN. How nice is that ? Event 5139. This looked promising and we decided to investigate further.
We quickly found out this worked as expected, and once properly configured (enabled auditing for the event, scoped it on proper OU and computer object classes only, etc.) were indeed able to track moves across the entire directory on the Domain Controller (DC) they were initiated from.
The next step was to collect all such events from all DC in the environment as these could be generated on any of them. The one solution that came naturally to mind in our case was to leverage our monitoring infra, based on SCOM (System Center Operations Manager - Microsoft's monitoring solution), already tasked with collecting many different events.
So we created a new reporting rule targeting event 5139 on all DC to gather the data, and from there, periodically ran a local script on one of the SCOM Management servers to extract old and new DN from the events, outputting them as a .csv file. Said file was then used as input for another regularly scheduled script tasked with updating extensionattribute1 on target devices in the cloud.
Having the main script tap directly into the database of SCOM was another option we considered. It was ultimately rejected though as outputting events through the use of SCOM-specific commandlets (Get-SCOMEvent) and a bit of parsing / formatting of event data in a separate piece of code proved to be both simple and convenient.
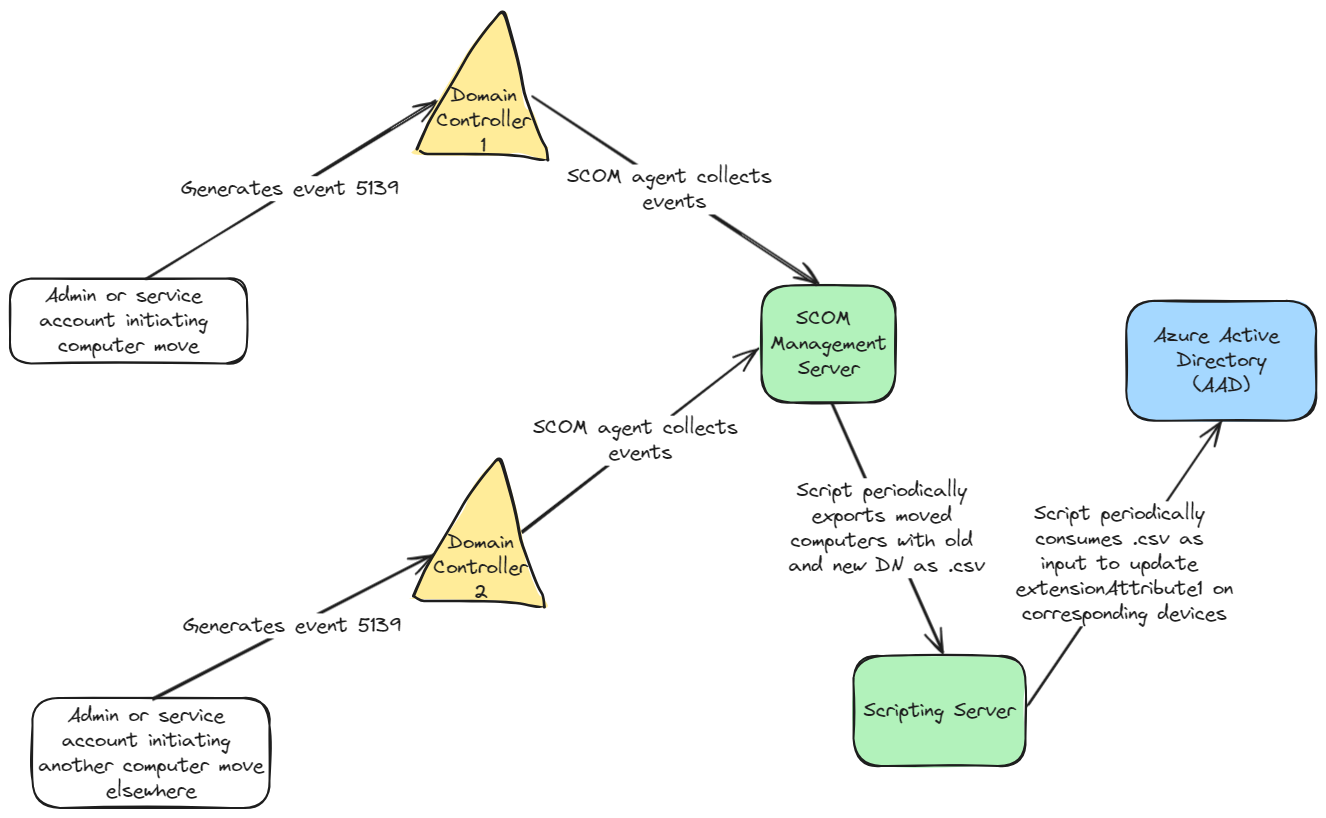
At last, we were able to get past this hurdle and properly replicate information over to the Cloud. Overall, we are now processing in average 6 to 10 machines every business day, so probably around 2 500 yearly. Definitely nothing to sneeze at !
Next on the horizon is completing the transfer of the few remaining GPO-based settings to Intune (Firewall, AppLocker, QoS, etc.) to complete our transition and start building cloud-only devices !
Special Thanks
I would not want you leaving, thinking I did all of this by myself. 😉
As always it really was a team effort, so allow me to thank, by order of appearance, Laurent Bros and Maxime Lescure who made the original "good enough" sync work years ago. Without you we would not be where we are today.
Smitesh Sarmalkar, Ajinkya Sherkar and Imad Nazim (with help from Rajat Khonde) under the lead of Abhishek Eklare who made our event-based solution a reality a few months ago, helping us to finally put this topic to rest. Kudos to them !
Last word will be for Fabien Anglard. Thanks for putting up with me on all these matters (and plenty of others as well) !