
Horizon Cloud VDI - Change Subscriptions or Build New & Universal Broker
Moving our Horizon Cloud VDI from a shared subscription to a dedicated one was not going to be as simple as I thought.

{kind=link}

This really should have had the title of Securing a Virtual Desktop Environment in a Public Cloud - Part 2.5 as it's part of our journey for securing our Virtual desktop environment. What I will detail below is the start of our journey of going from having Horizon Cloud in a shared subscription with other services to having it in its own dedicated subscription.
Background
When we deployed our Horizon Cloud VDI environment a couple of years ago we deployed in a shared subscription. At the time, given our cloud policies and knowledge this seemed like the right thing to do. Almost two years later we have gotten smarter and realized this was not the right thing to do. Some key reasons behind why this was not as smart as it seemed are:
- Subscription is shared with many other services so changes in one area or the other can be impacting
- Support model of multiple partners supporting the environment creates SLA issues due to rights given or not given to various support partners in this environment (This has led to major headaches for our end users and not provided a good user experience)
- It proved to be difficult for a product (VDI) in this environment to be continuously improved
Challenges and Decisions

The first challenge in front of us was how to get our Horizon Cloud VDI platforms (INDUS(what we call our 'test' environment) and PROD) from the shared subscriptions they were in into dedicated subscriptions with as little user impact as possible.
After reaching out on numerous messages boards and with VMware directly we could find no one who had performed a move like this. Since we had no referential on how to move the platforms we encountered our first major challenge and decision.
- Build new Horizon Cloud Platform (including user vms) in the target dedicated subscriptions.
- Migrate existing infrastructure via an unsupported and unofficial way that was discovered.
We chose to build a new Horizon Cloud Platform in dedicated subscriptions as the reference architecture was known and published, and the design would be supported by VMware.
The next decision was for the Universal Broker. The decision in front of us was:
- Continue using a Single Pod Broker for each environment
- Migrate to a Universal Broker
We chose to migrate to a Universal Broker. The benefits of going to this outweighed the benefits of staying with a Single Pod Broker. I pushed hard for this to be accepted as just the value I can see it bringing by simplifing user access regardless of where the pods are or what they are used for as it's all accessed from the same url. This will allow us to install more pods if needed, in any region, and simplify the activity by using a single url or fully qualified domain name (FQDN). It creates a scenario of something we can grow into instead of grow out of. The ability to create a multi-pod image is another big benefit to me as it can reduce the number of images we need to manage (See the point about Azure Service Principal rights under Lessons Learned below to avoid the problem we had). Another benefit of the Universal Broker that I hope we can leverage soon is global pod connectivity and awareness. The Universal Broker can manage end users' connection requests and route them to virtual resources directly without the need of implementing any type of Global Server Load Balancing. In the diagram below the user is determined to be closer to the New York pod so they are routed there.
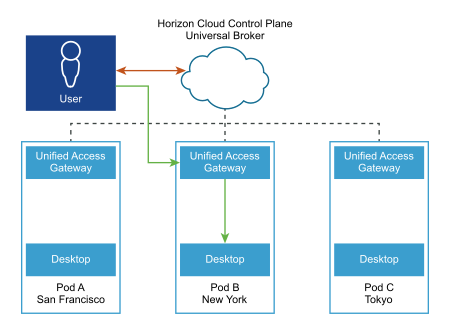
I had no problem influencing management that migrating to the Universal Broker was the right thing to do for our needs today as well as in the future.
It should be noted that this decision to migrate to a Universal Broker is valid even if we were not moving our VDI environment due to the benefits I mentioned previously.
Migration
The migration itself was fairly painless. We scheduled the date and time and in parallel began working up a communication to our users to inform them of the change and how they would need to connect to a new url.
As I mentioned, the migration itself was pretty seamless. I think our environment converted in a matter of minutes. Seeing this when I logged in to the Horizon Console was a relief!
Simple testing of desktops and assignments validated all appeared to be working as expected. With the Universal Broker setup and working we could now concentrate on building the new pods in our new subscriptions knowing that eventually they would be accessed via the same url we had just implemented with the Universal Broker.
An interesting point to note, we had different answers on how the existing single pod urls would function after the migration. We were told they would still work and could be used as admin access and, we were also told they would not work once we migrated to the Universal Broker. I can tell you now after having done the migration that direct access to both our INDUS and PROD Cloud urls did in fact still work after migrating to the Universal Broker as well as our new url. As mentioned previously the Universal Broker is intended to provide a single url for all users acessing different pods instead of having different single pod urls to remember.
The following diagram shows at a high level how the Universal Broker works within Azure:
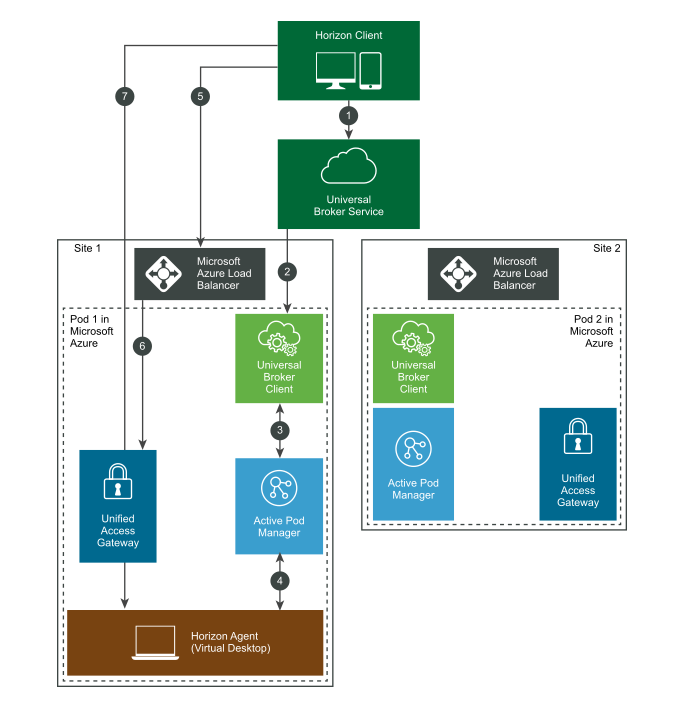
Lessons Learned
We access our Cloud VDI platform from internal as well as external. For internal access we had a pair of Unified Access Gateways (UAGs) that managed this connection and private IP addressing. This was done for a 'trust' relationship so that internal users would not have to two-factor authenticate like external users do when accessing the environment. Due to the migration to the Universal Broker, all users regardless of location (private IP or Public) access the platform via the public IP address of the Broker. This means that for internal users to access the Broker, their private IP address has to be converted to a Public IP address (NAT), and everyone accessing Cloud VDI now has to two-factor authenticate. This is not a bad thing as it simplified our support stream (everyone has the same steps to connect) as well as added a layer of security for internal users.
Azure Service Principal rights is another item. We discovered the hard way that five (5) additional rights needed to be added to our existing service principal to be able to use Horizon Image Management . If you have an existing service principal and plan to reuse it also ensure that these additional rights included for your service principal.
"Microsoft.Compute/galleries/read",
"Microsoft.Compute/galleries/write",
"Microsoft.Compute/galleries/delete",
"Microsoft.Compute/galleries/images/*",
"Microsoft.Compute/galleries/images/versions/*"
The complete document can be found here.
We discovered that the 'old' single pod url's are actually still used even after the migration to the Universal Broker. It seems that the Universal Broker will communicate with client and pass off the single pod url on the Azure Load Balancer (Step 5 in diagram above). This was confirmed with a network trace shown below:
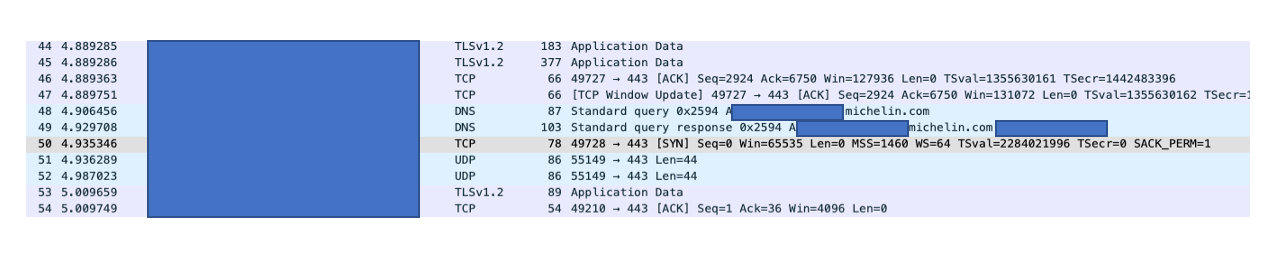
Prior to packet 48 above all communication was with the Universal Broker. Once a Published Application icon was clicked the client was informed to connect to the 'old' single pod url instance that exists on the Azure Load balancer. Evidence of that is packet 48 where the client make a DNS request for the url. Once the DNS response is returned communication directly with the url begins. This confirms the fact that the Universal Broker brings a single url for users to remember but leverages pod url's for the handoff of the user request.
Another lesson learned was that the character limitation for vm names was changed from eleven (11) to nine (9). "After the transition to Universal Broker, the VM names prefix can consist of at most nine customizable characters. Any VM names prefixes that were previously longer than nine characters are automatically truncated after the transition." Reference the article here. Existing names were truncated to the new nine (9) character limit and moving forward this required us to come up with a new naming pattern that aligned with the new requirement.
Next Steps
We have already started building out some of the foundational Azure infrastructure like new subscriptions, defining and assigning vnets, etc. We have also decided and implemented multiple subnets. The reasoning behind this is to segment Michelin users from non-Michelin users. Soon we will begin the building/deployment of new pods in these new subscriptions and begin the process of migrating user configurations to the newly created vms.
Summary
In summary we made the right choices to 1) Build new Pods in our new target subscriptions and 2) Implement Universal Broker. We do have some strange things to resolve after the migration to the Universal Broker but nothing that cannot be resolved or understood, with a fix forward mentality. The lessons we have learned are captured in hopes that they will help someone else who may be thinking about doing this.
Special Thanks
Special thanks to @David DeCarlo and @Fabien Anglard. Their contributions and knowledge are crucial to this effort.
Coming Next
Watch for my next article "Creativity and Innovation in Michelin IT". I think you will enjoy it.