
From Kafka to Delta Lake using Apache Spark Structured Streaming
Using Spark Structured Streaming to consume Avro events from Kafka and consolidate them with Delta Lake format on Azure Data Lake Storage

{kind=link}

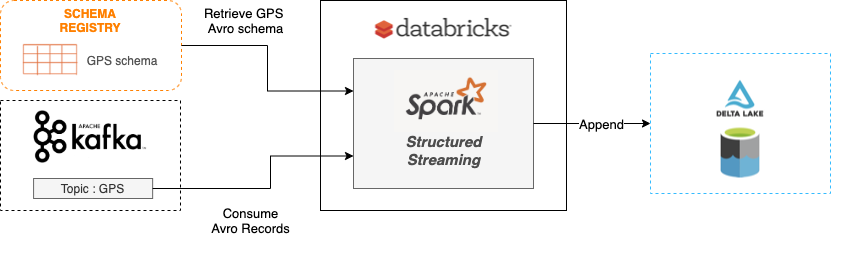
In our journey of building an IoT Ingestion Platform around connected tyres and vehicles, we have been testing Spark Structured Streaming and Delta Lake together to consolidate our data in our Azure Blob Storage.
Spark Structured Streaming is a distributed and scalable stream processing engine built on the Spark SQL engine. It provides a large set of connectors (Input Source and Output Sink) and especially a Kafka connector one to consume events from a Kafka topic in your spark structured streams.
On the other hand, Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads. It helps unify streaming and batch data processing. A Delta Lake table is both a batch table as well as a streaming source and sink. As data are stored in Parquet files, delta lake is storage agnostic. It could be an Amazon S3 bucket or an Azure Data Lake Storage container.
By using Kafka as an input source for Spark Structured Streaming and Delta Lake as a storage layer we can build a complete streaming data pipeline to consolidate our data.
Let’s see how we can do this.
First of all, we will use a Databricks Cluster to run this stream. This example will be written in a Python Notebook.
We have a Kafka topic named "GPS" in which our vehicles are publishing their GPS positions. The data is serialized in Avro with the following schema
{
"type": "record",
"name": "Gps",
"namespace": "com.michelin.telematic",
"fields": [
{
"name": "timestamp",
"type": "long"
},
{
"name": "deviceId",
"type": "long"
},
{
"name": "latitude",
"type": "double"
},
{
"name": "longitude",
"type": "double"
},
{
"name": "altitude",
"type": "double"
},
{
"name": "speed",
"type": "double"
}
]
}
1. Configuration
Let’s start by creating a cell in a Python Notebook and define some global variables
# Kafka Broker infos
kafkaBootstrapServers = "..."
kafkaUser = "MY_USER"
kafkaSecret = "MY_SECRET"
# Schema registry infos
schemaRegistryApiKey = "MY_API_KEY"
schemaRegistrySecret = "MY_SECRET"
schemaRegistryUrl = "..."
# Topic to consume
topicName = "gps"
- The Kafka instance and schema registry connections informations: servers, authentications details
- The Kafka topic name we want to consume events from
2. Schema Registry
The data coming from our GPS Kafka topic is Avro serialized. So the first thing we need to do is retrieve the Avro Schema to deserialize records in the stream before writing them to our Delta Lake table.
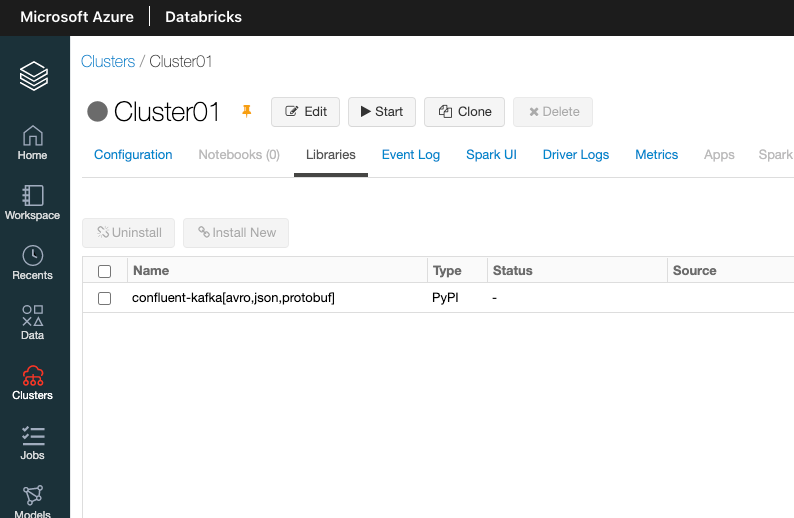
By default, Databricks does not provide python Confluent libraries to query schema registry.
Let's add this dependency to Databricks with two external librairies pointing to the PyPi confluent-kafka[avro] package
We can now retrieve our schema using this Confluent's Python client for Apache Kafka.
# Retrieve GPS Schema grom Schema Registry
from confluent_kafka.schema_registry import SchemaRegistryClient
schema_registry_conf = {
'url': schemaRegistryUrl,
'basic.auth.user.info': '{}:{}'.format(schemaRegistryApiKey, schemaRegistrySecret)}
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
gps_schema_response = schema_registry_client.get_latest_version(topicName + "-value").schema
gps_schema = gps_schema_response.schema_str
First, we instantiate a new SchemaRegistryClient with the authentication details. Then we lookup up the latest version of our GPS schema. The schema name is the topic name suffixed by "-value". The gps_schema var now has a JSON description of our Avro Schema.
For simplicity we will consider that all the data of our topic use the same value schema version. In real life we would write a dedicated function which for a batch of records collects the disctint schema ID and retrieve them from the Schema Registry to deserialize individually each record with the right schema version.
3. Configure the sink
To sink our stream in an Azure Blob Storage, we create a mount point from our Databricks Cluster to an existing Blob Container.
# BLOB STORAGE INITIALIZATION
containe_name = "datalake"
folder_name = "telematic"
storage_account_name = "STORAGE_ACCOUNT_NAME"
saas_token = "YOUR_SAAS_TOKEN"
config = "fs.azure.sas." + containe_name + "." + storage_account_name + ".blob.core.windows.net"
if not any(mount.mountPoint == '/mnt/datalake' for mount in dbutils.fs.mounts()):
try:
dbutils.fs.mount(
source = "wasbs://{}@{}.blob.core.windows.net/{}".format(containe_name, storage_account_name, folder_name),
mount_point = "/mnt/datalake",
extra_configs = {config: saas_token}
)
except Exception as e:
print(e)
print("already mounted. Try to unmount first")
We use the dbutils Databricks library to mount under a local folder (/mnt/datalake) an Azure Blob Storage folder (telematic) from a container named datalake.
In this example we use a SAS Token to access the storage service.
4. Let's Stream it
Now, it's time to create the stream.
gpsDF = (
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaBootstrapServers)
.option("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(kafkaUser, kafkaSecret))
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.mechanism", "PLAIN")
.option("subscribe", topicName)
.option("startingOffsets", "latest")
.load()
)
Spark Structured Streaming has built-in support for reading and writing to Apache Kafka. So let's start to read events from our GPS Kafka topic by just specifying the kafka format and give some options to specify how to connect to the source.
- The option startingOffsets controls how we consume the topic.
- latest: we consume only the new incoming events in the topic.
- earliest: we consume all the events present in the topic.
Each record consumed from Kafka will have the following schema :
- key: Record Key (bytes)
- value: Record value (bytes)
- topic: Kafka topic the record was in
- partition: Topic partition the record was in
- offset: Offset value of the record
- timestamp: Timestamp associated with the record
- timestampType: Enum for the timestamp type
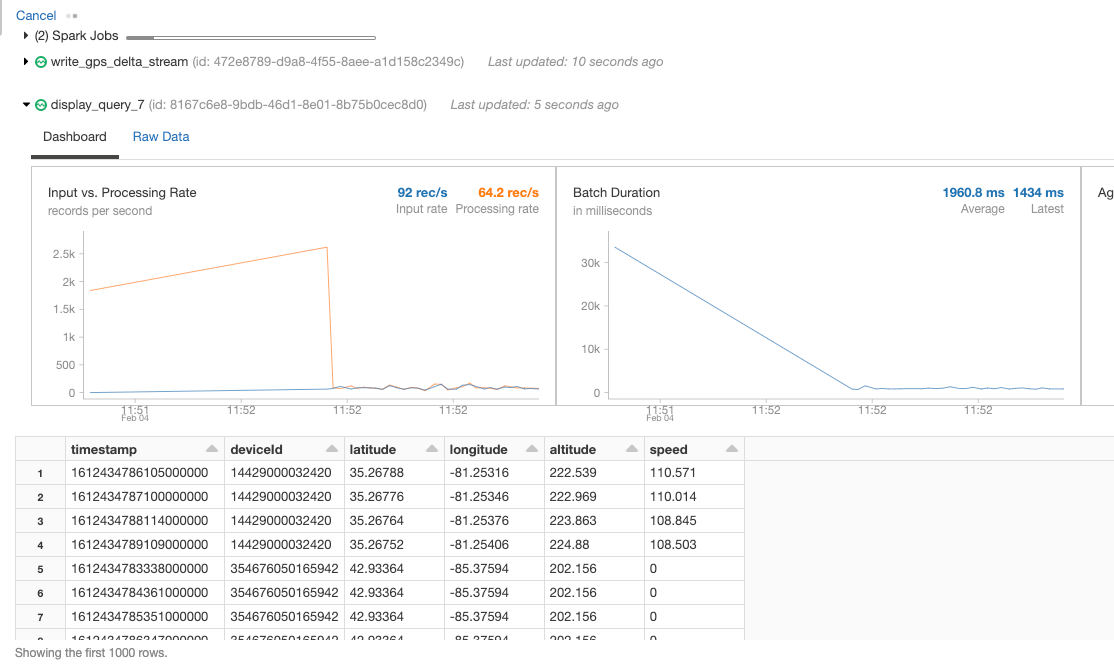
If we display the gpsDf DataFrame here is the output:

We now have to deserialize the value column from our gpsDf DataFrame
from pyspark.sql.avro.functions import from_avro
from_avro_options= {"mode":"PERMISSIVE"}
structuredGpsDf = (
gpsDF
.select(from_avro(fn.expr("substring(value, 6, length(value)-5)"), gps_schema, from_avro_options).alias("value"))
.selectExpr("value.timestamp", "value.deviceId", "value.latitude", "value.longitude", "value.altitude", "value.speed") \
)
display(structuredGpsDf)
We first use the from_avro function from pyspark.sql.avro.function to deserialize the record.
The 5 first bytes of the value retrieved correspond to the Magic Byte (0) and the schema ID so we only take the data after.
We also give to this function the GPS Avro schema retrieved from the schema registry. The last argument is a configuration to control the behavior of the stream when the deserialization fails.
- FAILFAST: Throws an exception on processing corrupted records.
- PERMISSIVE: Corrupt records are processed as null result.
Then we use selectExpr to flatten the JSON representation in separate column in the DataFrame.
Here is the output if we display the structuredGps
We can now write this stream into a Delta Lake table.
structuredGpsDf.writeStream \
.format("delta") \
.outputMode("append") \
.option("mergeSchema", "true") \
.option("checkpointLocation", "/mnt/datalake/gps/_checkpoints/kafka") \
.start("/mnt/datalake/gps")
We just use the built-in delta format with the append mode.
The checkpointLocation option is not particular to the delta format but to the Spark Structured Streaming API. It allow us to use checkpointing and write-ahead logs to recover in case of failure (more about this here).
Finally we give the path under the mount point created within Azure Data Lake Storage to start writing under a dedicated folder "gps"
Here are few things the delta format allow us :
- allows to write in the same table from both stream and batch processes
- allows ACID guarantees under concurrent writes
- allows multiple instances of the stream to append data into the same table
It's also possible to write this 3 steps into one like this
spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafkaBootstrapServers) \
.option("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(kafkaUser, kafkaSecret)) \
.option("kafka.security.protocol", "SASL_SSL") \
.option("kafka.sasl.mechanism", "PLAIN") \
.option("subscribe", topicName) \
.option("startingOffsets", "latest") \
.load() \
.select(from_avro(fn.expr("substring(value, 6, length(value)-5)"), gps_schema, from_avro_options).alias("value")) \
.selectExpr("value.timestamp", "value.deviceId", "value.latitude", "value.longitude", "value.altitude", "value.speed") \
.writeStream \
.format("delta") \
.outputMode("append") \
.option("mergeSchema", "true") \
.option("checkpointLocation", "/mnt/datalake/gps/_checkpoints/kafka") \
.start("/mnt/datalake/gps") \
5. Reading the data
Finally, to read the data from the GPS Delta Lake table we can create a tempory view using the delta format and the table location.
spark.read \
.format("delta") \
.load("/mnt/datalake/gps") \
.createOrReplaceTempView("gps")
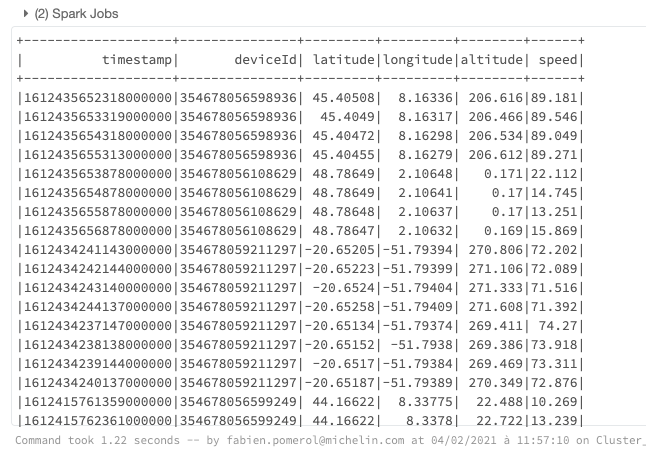
spark.sql("SELECT * FROM gps limit 100").show()
Conclusion
As we see, configuring a stream consuming kafka events and appending them in a Delta Lake table with Spark Structured Streaming is quite easy and do not require tons of code.
The real potential of Delta Lake starts when you want to do more complex operation than the append mode in your datalake. Like for example update / merge /delete operations.
We will explain this in a future article ;)
Stay tuned.