
A story on how Michelin continuously modernizes its information system


Introduction
Over the past years, we at Michelin Group, have been trying to think about how to deeply change the way we plan, build and operate our information system to adapt to the VUCA world and we have many transformations on the way around that.
These series of articles will describe this IS modernization journey, from an enterprise architect perspective.
The context
Probably like all multinationals a few decades old, we have a complex and aging information system, which relies on a huge diversity of technologies accumulated over the years.
A 12-year-old Information System as an average
The number of applications that the Michelin IT group has under its responsibility varies over the years according to merge & acquisitions, decommissioning, IT shadow initiatives and others, but as of today the application portfolio represents around 2000 applications covering all the business domains of the company (from research & development up to the CRM through manufacturing and/or group support services like HR) and supporting solutions & services sold to our customers.
The average age of these 2000 applications, if we consider the lead time since the first go-live, is 11.3 years (was more than 12 years when we started our modernization journey). As we have a lot of systems that are quite recent (25%, less than 3 years), it means that we have many systems that are much older, especially in factories or around order-2-cash processes where main applications are still running on mainframe systems. It is not uncommon in these areas to find systems that are over 20 years old.
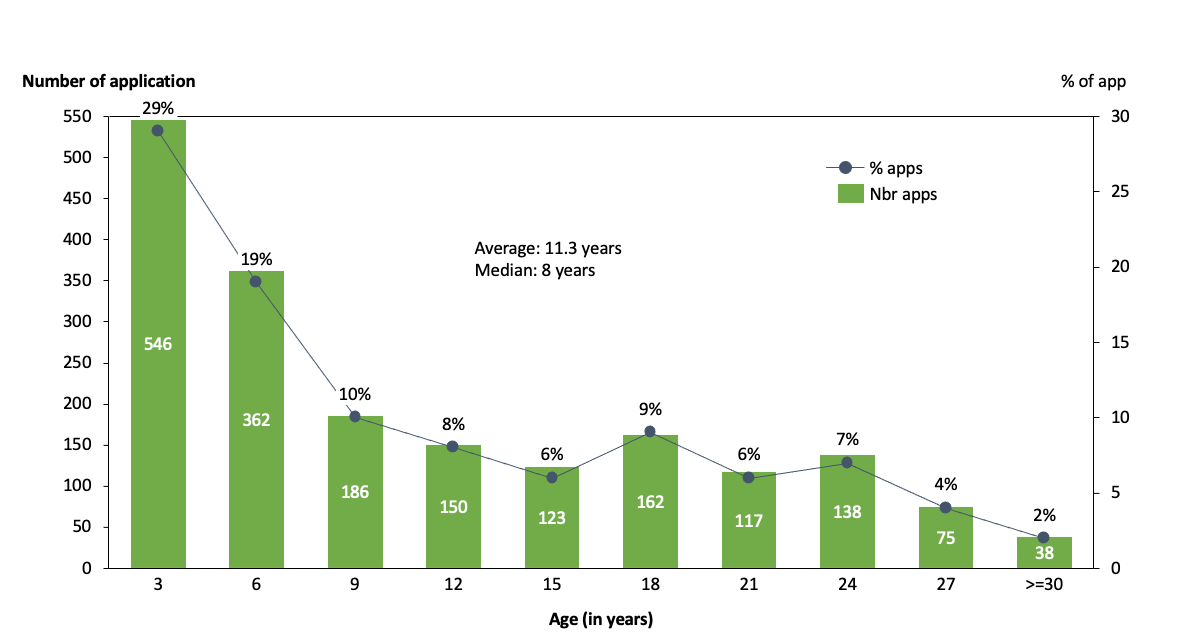
It is not so easy to get benchmark data around this subject (if you are interested in sharing don’t hesitate to contact us!) but we think It’s 2 to 3 years older than our peers in the industry.
Complex & costly to change
This system has suffered over time a quite disordered evolution mainly because time and cost constraints. Despite IS modernization efforts these past 3/4 years, our Information System is still based to a large extend on a set of siloed applications, mainly integrated between them in batch mode. The below diagram illustrates well the result of this messy evolution. It reflects the complex structure generated by the interweaving data flows between applications .

This is sometimes referred to as the “spaghetti syndrome” which implies that the resistance of the system to change is at its maximum as state by Rushby.
“A badly structured program is likened to a plateful of spaghetti: if one strand is pulled, then the ramifications can be seen at the other side of the plate where there is mysterious turbulence and upheaval”
(N.Rushby 1983, as cited by P.Grubb - Software Maintenance Concepts and Practice 2nd edition - 2003, p.56).
And that's not a good news considering the requirements of a VUCA world 🙁
From my side I will prefer to compare it to a social-network rather than using the metaphor of the plate of spaghetti 🙂 as we can observe two characteristics found in many social-like networks:
- First, the network contains several denser subnetworks, held together by a sparser global web of edges.
- Second, it is organized around a small subset of highly central applications (the big nodes in the graph).
But the result is the same, over time our information system has become too strongly coupled, difficult to evolve, costly to maintain and subject to failures.
Obsolescence and technical debt are increasing
As it is increasingly difficult to maintain it, we are less and less able to reduce obsolescence and the technical debt is increasing. For example, about a quarter of our VMs were running obsolete operating system versions.
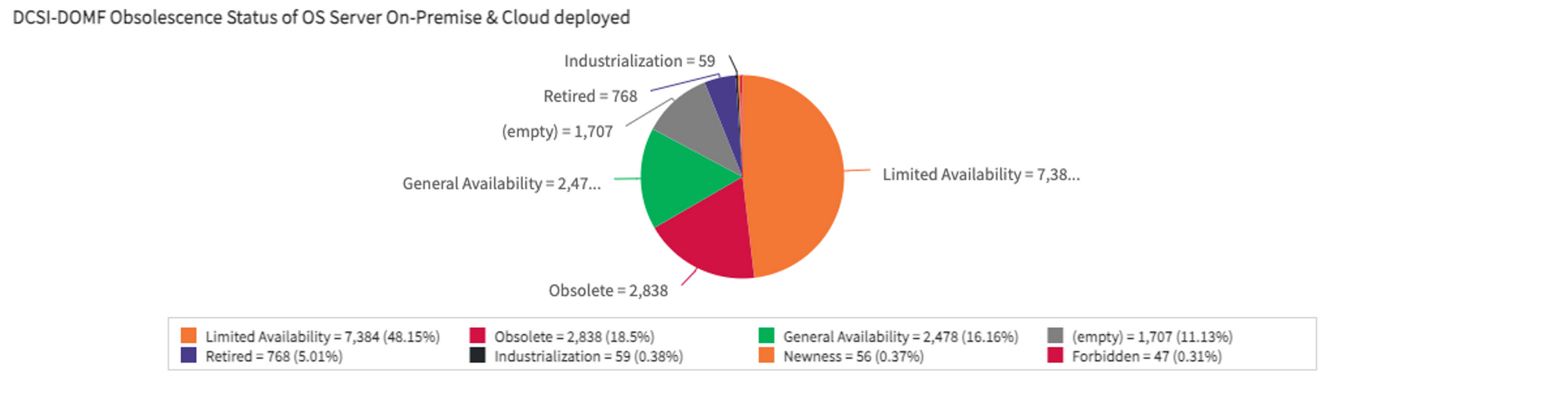
It’s even worse when we look to some middleware like database where half of our systems are using no longer supported versions of databases.
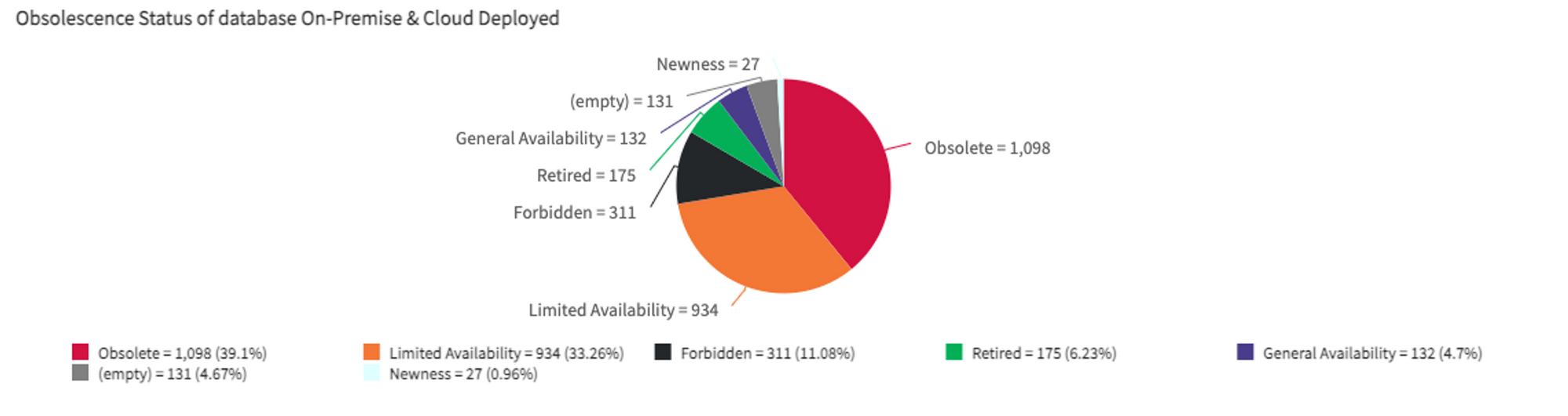
This results in a degradation of SLA (we had experiencing a high incident rate on some part of our systems with business impacts, hopefully fixed now) and increase security risks as well as our run costs.
Mitigation of security risk leads to additional security costs as we need to isolate systems or deploying specific rules (such as the treatment of web facing applications that must not use obsolete components under any circumstances). This requires focus and resources from our organisation that are no more available for tasks of higher value.
Call for Action - Continuously modernize our information system
Let’s summarize the situation:
- On one end, we have an aging and complex information system, the resistance of the system to change is at its maximum. It's more and more difficult to deploy new features at the expected rate of change. Maintaining the system is costly, technical debt is increasing and the risk of failure is increasing with negatives impacts on quality of service.
- On the other end we are under an exponential flow of changes to support new business ambitions and an increasing rate of change of technologies.
This situation was our wakeup-call in 2018 to start to deeply modernize our information system.
As stated by the law of continuing change formulate by Lehmans [Lehman, M., (1980), "Programs, life cycles and the laws of software evolution," Proc. IEEE, 15 (3).],
“systems must be continually adapted or they become progressively less satisfactory to use”
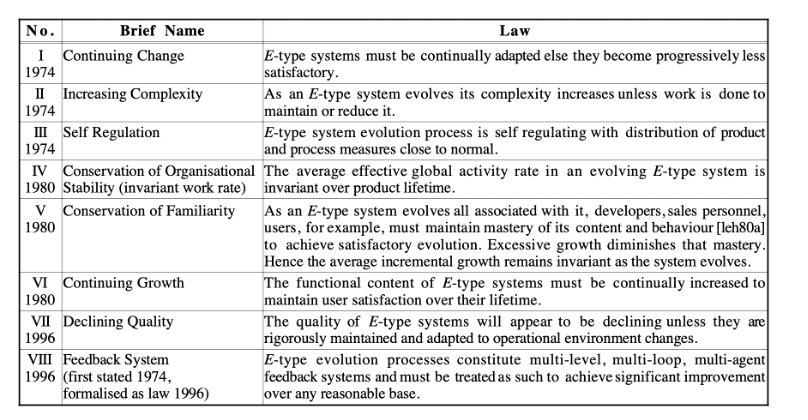
This law says that systems evolve in a way comparable with biological organisms where species (plants, animals,…) had to change to survive. They had to adapt to the variations of their environment. It means that software systems will no longer deliver value to the organization if they are not evolving continuously. To survive, our information system needs to be organized to change continuously in a sustainable way.
So what does it mean from an architect perspective?
1) Agile architecture operating model
If we agree with Martin Fowler’s definition stating that software architecture is those decisions which are both important and hard to change. It means we must as an architect make important decisions quickly and continuously. But the architecture process hasn't really changed for 20 years. It has not been designed to operate on short cycle and is perceived by delivery teams as a bottleneck.
So, the first thing we did was to define and deploy a new architecture operating model adapted to agile and devops practices, as this is the way of working of most of our delivery teams. Our main goal was to develop team autonomy while providing them with a broader architectural perspective and keep the integrity of the information system at scale.
This operating model highlights key principles to design and architect software systems continuously like:
- Architecting as a team activity
- Managing dependencies
- Clarity of architecture decisions
- Develop architecture skills beyond architect
- Develop leadership and influence of architects
- …
Internally we call it Continuous Architecture, as everything is Continuous something nowadays (continuous integration, continuous testing, continuous delivery, ...), but we discover just after that Murat Erder & Pierre Pureur coined the term long before us 😞. Anyway, we keep it and now, we have open-sourced this architecture toolkit. A future article will be the opportunity to share a more in-depth overview on it.
Continuous Architecture will help to bridge the gap between Enterprise Architecture (focus on long term, vision) and delivery squads (focus on short term).
2) Agility & reliability as properties of the system
In order to obtain a permanent adaptation to its environment, our information system need to move away from large “best-of-breed” on-premises monolithic applications tightly integrated towards a modular multimodal highly distributed service architecture, whose different parts, loosely-coupled, evolve at different rates and can be extended and recomposed to offer new experiences.
For that, we defined a new set of architectural principles to apply:
- Architecting for scalability and resilience
- Architecting for evolutivity and modularity
- Architecting for continuous delivery and operability
These principles form the basis for our architects to make decisions when designing new versions of our systems and are there to remind us that we have to design systems that will have to adapt to future needs that we don't know yet, in a sustainable way.
Modularity is key as monoliths impede agility. By increasing isolation between software components, we can deliver parts of the system both rapidly and independently.
Improving agility is not the only benefit of modularity. Jim Gray in his study “Why Do Computers Stop and What Can Be Done About It?” , one of the first fundamental papers of fault-tolerance in distributed systems , discusses the origins and implication of failures and what should be done to design resilient, fault-tolerant computer systems and key ideas to achieve high availability are: modularity and redundancy
“Combination of modularity and redundancy is the key to providing continuous service even if some components fail. “
Jim Gray, June 1985, Tandem Technical report 85.7
Monoliths tend not to be very reliable as they share infrastructure and middleware resources, a failure in one component can spread to others, causing downtime for users. The risk of making a breaking change in a monolith increases with the amount of effort required by teams to coordinate their changes. The more changes that occur during a single release cycle (and with a monolith there is a lot), the greater the risk of a breaking change that will cause downtime.
With modularity, a failure in one module affects only that module (isolation). With redundancy (also call process-pairs in Jim Gray’s paper) if a module failed, you give the illusion that you have an instantaneous repair, meaning that the MTTR is zero. If the MTTR (Mean Time To Repair) is zero, then availability is 100%, always on (as availability = MTBF / (MTBF + MTTR)). I let you do the math 😄.
So you need redundancy and modularity to achieve resilience.
Event Driven Architecture has become our preferred architecture pattern to design our applications as it is based on minimal coupling and enables flexible composition of software components. The micro-services pattern is also more and more used to implement application services as it’s easier to have redundant deployment of each service and to leverage self-healing kubernetes platform feature to give the illusion of a zero MTTR.
Composition and integration between the different building blocks were more and more lead by APIs, both asynchronous (Kafka topics as an ex.) and synchronous APIs (REST APIS mostly), with event-driven APIs as the first choice.
On top of that, we have reinforced our monitoring and automation practices as they are the necessary ingredients to design, operate and master the inherent complexity of this modular event-driven architecture. The progress made on monitoring practices does not only benefit the new modern systems, but also our existing systems. They have allowed us to significantly improve our business services availability for example by reducing the MTTR by coupling the alarming of the monitoring tools with our ITSM tool and event management. To go a step further we just start to deploy gradually SRE practices adapted to Michelin context, focusing on bringing more automation to eliminate toil in our day to day run activities or implement error budgeting to help delivery squads to prioritize between additional features or reinforcing some non-functional requirements.
In addition to bring agility and resilience, we see also other benefits to go with EDA (and streaming architecture) which are:
- Reducing complexity by mixing transactional model and batch model in one programming model (waiting a batch of events using windowing techniques for example when it’s needed)
- Merging operational workload and analytical workload and build context aware “translytic” applications to implement real-time analytics use cases that can allow businesses to get ahead of the curve in One System (Luigi Scappin in his post “How a Distributed Data Mesh can be both Data Centric and Event Driven” explains well why the boundary is blurring between operational data producers and analytical data consumers in “translytic” systems)
3) Set up new capabilities
Technology is not the silver bullet and for example you can very well design an unmanageable giant distributed monolith if you do not carefully design your micro-service application. But designing a highly distributed, modular & resilient information system, even if it’s not sufficient, requires technologies that I call “transformational”. And we have started to deploy and used them actively:
- Cloud computing with IaaS but above all PaaS services (Our preferred cloud provider is Azure, but we use other hyperscalers like AWS)
- Container and Kubernetes platform (10 clusters and around 60 applications in production to date)
- API Manager (we use gravitee.io and Google Apigee Edge)
- Event-driven broker and streaming platform (we use intensively Kafka technology, and more than 30 clusters are moving our data now)
Not surprisingly, many of the articles on this blog, written by my colleagues, talk about these technologies and the different learning we have through our use cases.
Micro-services architecture, even-driven architecture, modularity, all are software architecture principles or patterns which have been around for a long time, but there are new for our architecture community. So to help them designing systems using these patterns, we added DDD (Domain Driven Design) in our Continuous Architecture toolkit and start to use it for what I call macro architecture (architecture at systems level). Here are the DDD tools we used the most so far:
- Bounded-contexts help to move away from monolith and design cohesive domain model for each business microservice. It forces to think about vertical decomposition instead of horizontal one such as other technics like Archimate.
- strategic patterns help to describe flow of data models and relationship between business domains/business context. It helps to make explicit where we need flexibility, where we need rigidity in our information system.
- Event-storming workshop help to identify domain events and model the behavior of business domain.
4) Continuously change our foundational technologies
We have found also that there was no chance we could maintain our applications continuously if the shared technologies and software components/middleware on which they relied on were not also updated and maintained continuously.
To address this, we setup a product-centric delivery approach, as of today, made of 11 IT Platforms that are long-live agile/devops teams with the responsabilities to plan-build-run technologies capabilities (internally developed and/or externally procured) used to build applications (by technologies capabilities we mean: data bases, integration middleware, infrastructure as code, containers, monitoring toolsets, …). Each two months, they provide new releases to the whole organization. We have an agile@scale governance to manage dependencies between them and to prioritize the backlog at system level that represent our technology roadmap.
We can already see benefits like reducing lead time to maintain or deliver technical capabilities. For example, all our container clusters are updated four time per year following the kubernetes releases cycle. These updates are fully automated without any downtime impacted hosted applications.
But we still have some progress to do mainly around improving experiences the IT platforms provide to their audience and better prioritize based on value creation.
We call this management system “OneSystem IT Platforms” or “Evergreen IT Platforms”, you can have a look to the previous article Platforms, you said platforms of my colleague Olivier Jauze if you wants to have a more in depth explanation on it.
Moving forward
Modernizing an architecture usually take years. Even a decade or more is nothing out of the ordinary for large organizations who have accumulated legacy and heritage systems over long periods of time. And it's no different for us, we think that our IS modernization path will be an effort of more than 10 years.
So we decide not to set up a classical strategic program with a multi-years plan but rather develop what Yves Caseau, our CIO call the “situation potential” through several initiatives.
One of these key initiatives is to improve our "technical grip" by promoting technical career paths in IT, leveraging our fellow internal program and IT expert network. For example, our top professional performers are now granted IT Expert, Distinguished Engineer or Fellow in recognition of their significant achievements and contribution to our strategy. Most of the authors of this blog got one of these company’s distinction.
But perhaps, one of the most impactful initiate we launched is what we call internally “Boosters”.
The idea was to learn to build & operate this resilient, reactive and highly distributed information system by doing first use cases, show case to the rest of the organization and set up capabilities (knowledge, technologies, support team, way of working, …) that should make easier for delivery teams to grasp modernization opportunities and start their journey. In a sense we will build, no more a roadmap, but rather a map of roads toward IS modernization 😄.
To encourage delivery teams to embark on the adventure, a facilitation team of experts is leading the paradigm changes by bringing expertise, generating momentum & remove obstacles. An incentive budget is distributed each year to help the booster teams with most impactful modernization initiatives proposal.
To support risk taking a reward ceremony that we call ‘Evergreen awards’ is regularly organized by the leadership team and the management. It recognizes, values and thanks teams that help our organization to make progress toward our goals (we have 5 levels to highlight the progression: from the initiate person to the sage person 🙂).
Although much remains to be done, Boosters initiative give very good results so far. We started to refactor and gradually replace some of our legacies systems using “born to the cloud” technologies, improving quality of service and quality of experience for our end-users. Some have been fully rewrite and move to the cloud, opening the door to new functionalities of high value for our businesses.
The next articles in this series will be dedicated to deep-dive to these achievements.