
Legacy integration, a story of modernisation
Discover the challenges faced by Michelin teams to transform a 15 years old legacy system into domain-oriented streaming data source.

{kind=link}

Introduction
Just like any modernization story, our will start presenting the “Legacy system”. Before diving into the actual presentation of our victim, let’s focus on what a “legacy” term means when used in an information system context.
“...legacy system is an old method, technology, computer system, or application program, "of, relating to, or being a previous or outdated computer system," yet still in use”
https://en.wikipedia.org/wiki/Legacy_system
Usually, people are proud of their legacy, it’s something you pass from generation to generation and the older it is, the better. In information systems, “legacies” are seen as the opposite. In our industry where the “new” is idolized, the “old” has a negative perception and should be at any cost replaced. Yet these systems are still here, keeping us busy… but why? The answer is simple: Money.
Legacy systems have common characteristics, over the years, they have been taking a critical position (with or without customizations) in core functions proving their ability to support the company's fundamental needs in order to generate or save cash. Perturbing these systems is facing the risk to impact the monthly incomes. In this scenario, the standard behavior (no need to be a senior risk manager) is to secure your actual position rather than taking a bet on hypothetical gains or savings.
So we’re facing a nice paradox, everyone wants to replace legacy systems by new faster, stronger, nicer solutions but nobody is willing to take that risk considering it as critical for your company. That’s the starting point of our journey, how to break things in a safe environment.
Just as “production” everybody has its own “legacy” definition, so rather than debating on semantics, let’s jump in our study case.
The context
Our application, is a warehouse management system born 15 years in one of the Michelin factories as a fork of a flow management system. The application was made by people coming from the Operational Technology/mechanical ecosystem with the tools and patterns they know back then. In a nutshell, the application is a set of C/C++ batches and smart client applications persisting directly the data into a relational database (no any kind of backend service).
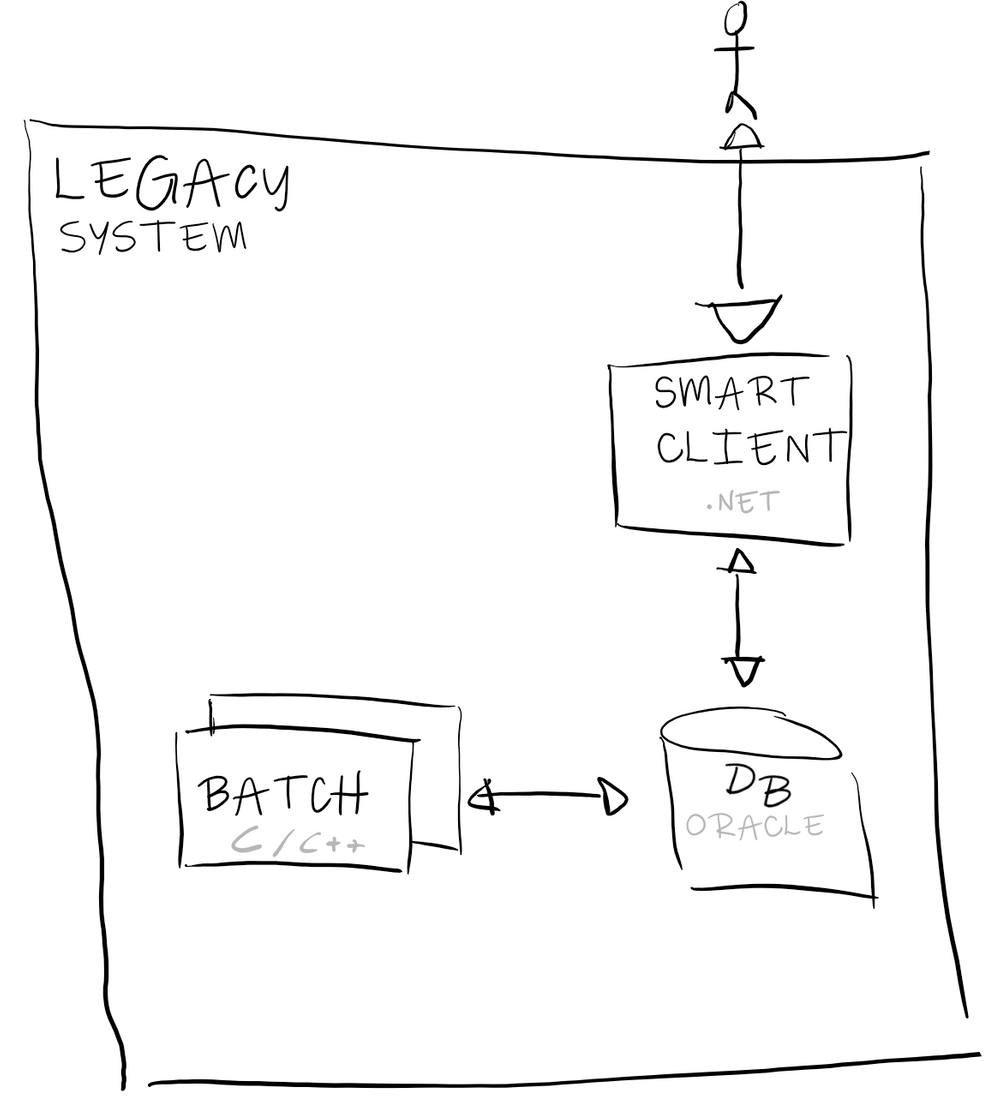
After a couple of years, organically, the application replicated to other factories until the point where the headquarters decide to manage it as a “corporate” application. The developments are still made in C/C++ and keeping the original structure of the applications. Over the years, the app has been extended to cover each factory specificity/release speed forcing the team to manages dozen versions in parallel.
Nowadays, each and every one of the application change is rigorously evaluated to keep a complex balance of feature/risk (cost).
In 2020, we decided to start a project to expose, in real-time, the stock events hosted in this legacy application as first-class information through the Information System.
The challenge was to find a way to extract data from the legacy application without impacting the application performance/scope while also not creating a coupling to the development team and deployment planning. In this context, we introduced an anti-corruption layer based Qlik Replicate as Change Data Capture tool and Apache Kafka as streaming platform.
Qlik Replicate, Change Data Capture
Change Data Capture (aka. CDC) qualifies a category of tools able to identify changes to a database in order to be applied to another data repository or made available for other integration tools. In the context of Michelin, we limit the CDC scope to Relational Database Management Systems (and more specifically to the Oracle DB).
There are 2 main Change Data Capture strategies:
- Query-based: Execute a periodic “select” query to capture and propagate a set of table’s state (Eg. ETL solutions)
- Log-based: Read the internal database log (aka. transaction or redo log) to forward DDL and DMLs events (DB to DB replication/synchronization solutions)
In the context of a legacy database, the log-based strategy is particularly interesting because:
- Low impact on CPU(Central Processing Unit): By simply reading the database log files the performance impact is very low (<10%) regardless of the size of the DB.
- Near Real-time: When using a query-based solution, the data freshness is based on the query frequency where “tailing” the logs permits to react (almost) instantaneously whenever a change occurs.
- No impact on data model: No need of “COMMIT_TIMESTAMP”, “LAST_UPDATED_TIMESTAMP” columns to detect updated data. If a change occurs it will be traced in the log and the event timestamp is free of charge.
- Built-in delete detection: With query-based change detection, “deletes” are a nightmare, either you do a logical delete (ie. toggle a flag in the record) or detect it in ad-hoc processing. With a log, a DELETE is nothing more than a simple event just as an INSERT or an UPDATE.
- Fault-tolerant: Imagine you can’t extract data from your DB due to a downtime of your CDC. With a query-based CDC, all the intermediate state are lost forever while with a log-based solution, you can resume your processing and consume all the operations that occurred during the downtime.
At this point, you should think log-based CDC is a silver bullet but it’s important to say that not all the databases are compatible with a log-based CDC. First, the database must provide access to its event log (in addition, due to editor partnerships/licensing not all CDC can access to all Database event logs). Secondly, configuring the access to a DB log requires a DBA intervention (and some time a DB downtime) which is more complex than just getting read-only access to the set of tables we want to read.
Back to Michelin, we use Qlik Replicate (former Attunity Replicate) as Change Data Capture. It provides a query-base option to capture an initial Database state (aka. Full Load) and a log-base option (aka. Change processing) to capture database events. In the context of our study case, we plugged Qlik Replicate to an Oracle DB as source and forward the changes to Apache Kafka.
Apache Kafka
Do we still need to introduce Apache Kafka in 2020? Kafka is an open-source distributed streaming platform with a set of interesting properties to support an Event-Driven Architecture. In the context of Michelin, and more specifically in the Manufacturing domain, we position Kafka as a data backbone enabling pub/sub and “on the fly” data processing.
Since log-based Change Data Capture tools are turning database into a streaming data source where each new transaction generate a set of database events, they work nicely with Kafka and its ecosystem. For each database event, Kafka will permit us to filter, transform, join or aggregate on the fly thanks to the Kafka Stream library.
Now that we have a tool to extract data and another one to carry/process it, let’s see how they are combined to build an Anti-Corruption layer.
Anti-corruption Layer
What’s worse than having a legacy application? Having its semantics spread into all your information systems. It’s a common pitfall when integrating a legacy system, the data exchange are shaped inside-out (the legacy ends up exposing its physical model) rather than adapting to a ubiquitous language.
This problem is particularly present when you using CDC tools, you basically expose your database model and this is where the Anti-corruption Layer (aka. ACL) pattern can definitively help you.
An Anti-Corruption Layer is a pattern used in legacy system integration. By preventing the propagation of non-desired semantics, an ACL avoids corrupting the domain model of new services. In simple words, it’s a translation layer between old and new (incompatible) systems.
In the context of modernization of legacy systems, we use a one-way ACL to expose "business-oriented" Stock events (in our use case we don't need to write back to the legacy system).
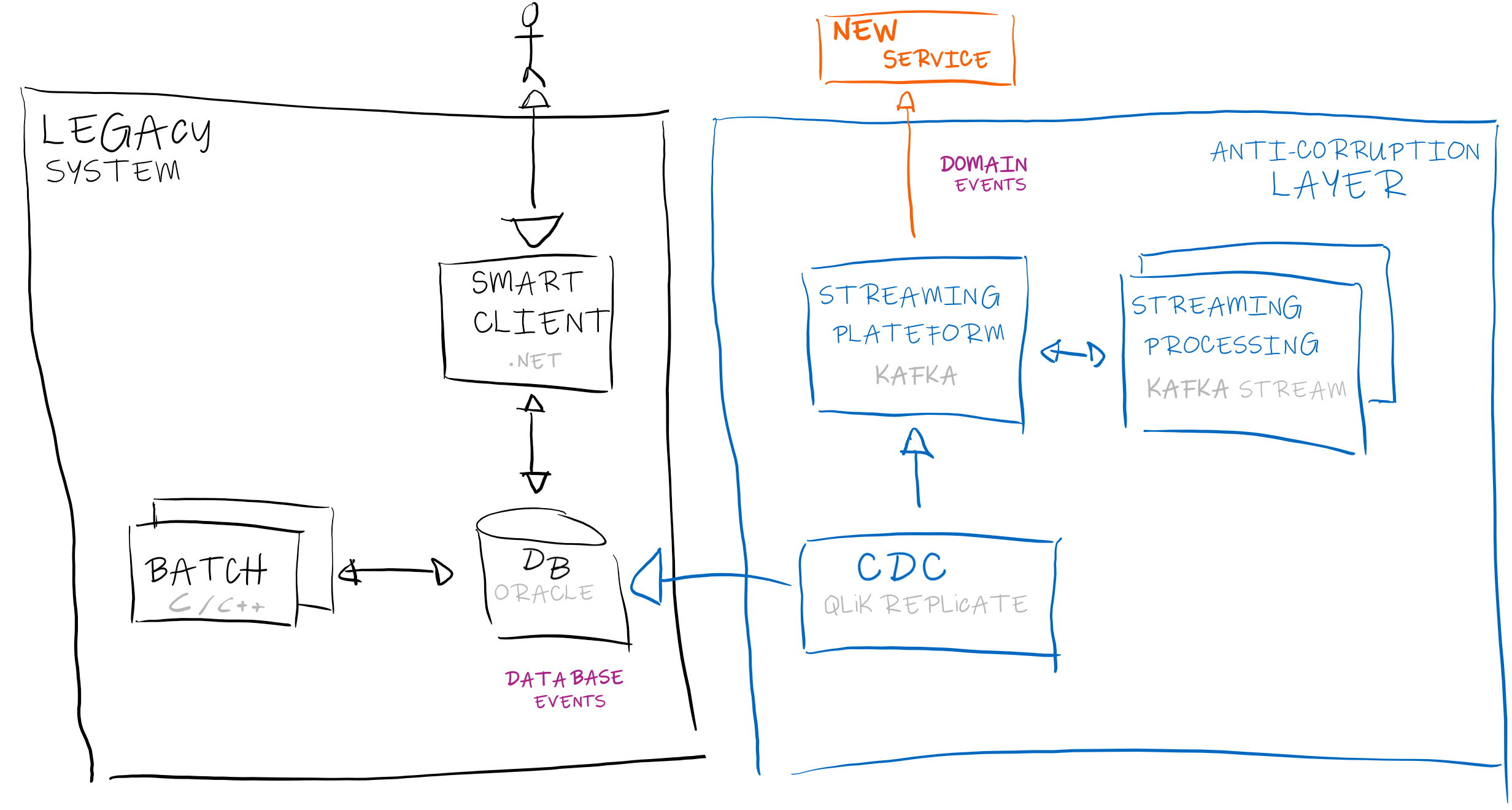
The interesting points are:
1- Whenever a change occurs to the databases, Qlik Replicate detects it and sends it to the Kafka platform.
2- A set of Kafka Streams, cleanse, and consolidate database events to build domain events.
3- A facade exposes a set of clean domain-driven events ready to be consumed by new services.
As a side effect, you also have built a contract for your legacy which can act as a functional safety net for refactoring. Knowing how new services will request your Anti-Corruption Layer and the expected results/structure you can apply a "white-box" design approach (as we do with "white-box testing") and reconsider the technical implementation.
Looks easy? It's not... While the value of dismantling legacy system is unanimously accepted there's no magic. Building an ACL still implies to discuss with the old system and certainly requires a higher level of technical and functional knowledge of the underlying applications. On the functional hand, such patterns are basically duplicating part of the business rules thus introducing a risk (never forget that the legacy already proves its reliability where your new solution has not). On the technical hand, bridging the gap between a historical Relational Database Management System and event-oriented technologies like Change Data Capture and Kafka is not trivial and will be covered in this blog (event ordering, transaction identification, eager vs lazy data structuration, etc.).
Conclusion
At Michelin, our position is that delivering value is not a one-shot operation but a continuous and dynamic process (and the faster, the better). Legacy systems are key components of any Information System landscapes and its pretty likely you will have to deal with them at some point, just accept it. The challenge is to set up a context where improvements or replacements are risk-free and cost-effective.
This post explained how a Michelin production-application is using Qlik Replicate (Change Data Capture) and Kafka to build an Anti-Corruption Layer. This pattern permits to "decorate" the legacy system in order to build new services while creating a refactoring opportunity.
Stay tuned for more details on challenges of integrating legacy systems ;-)