
Modern API Architecture: What Changed When We Moved the Front to APIM Gateway


{kind=link}

For years, our external B2B APIs looked perfectly adequate on paper. They were reachable, stable, and met their functional contracts. Clients integrated successfully, traffic flowed, and nothing appeared obviously broken.
Over time, however, operational reality told a different story. Incidents were harder to reason about than they should have been. Client attribution was blurry. Usage patterns were inferred rather than observed. The system worked — but operating it became increasingly costly.
At the center of this friction sat a quiet architectural choice: a network load balancer acting as the public front door of our APIs. What started as a pragmatic infrastructure decision gradually shaped how the entire API platform behaved.
This article is not a retrospective debate about whether that model was theoretically right or wrong. That conclusion had already been reached. Instead, it focuses on what changed in practice once we moved the API gateway to APIM— and how that shift transformed the way we observe, govern, and operate our APIs.
When Network Decisions Shape API Platforms
Like many enterprise environments, our Internet-facing APIs evolved through infrastructure-led decisions rather than API-first design. External B2B traffic initially entered through a load balancer, introduced primarily to shield consumers from backend change.
Clients invoked APIs using stable public domains. DNS resolved those domains to a load balancer virtual server, which acted as a reverse proxy in front of the platform. This allowed backend services and ingress endpoints to evolve without requiring customers to update domains, certificates, or connection details.
Over time, the load balancer’s role expanded. In addition to TLS termination, it applied routing rules and network-level security policies before forwarding traffic into Kubernetes ingress and backend services.
From a delivery perspective, this architecture worked well. From an operational perspective, it quietly blurred responsibility boundaries. Infrastructure components began carrying concerns that were inherently API-centric: consumer visibility, governance, and traffic understanding — responsibilities they were never designed to own.
Rather than incrementally patching these limitations, we used the migration as an opportunity to redefine the API edge with a clear, risk-aware objective:
- Remove the load balancer from the API front door
- Introduce a dedicated API management layer
- Preserve existing domains, endpoints, and consumer contracts
No consumer disruption. No breaking changes. Just architectural clarity.
The Original Architecture
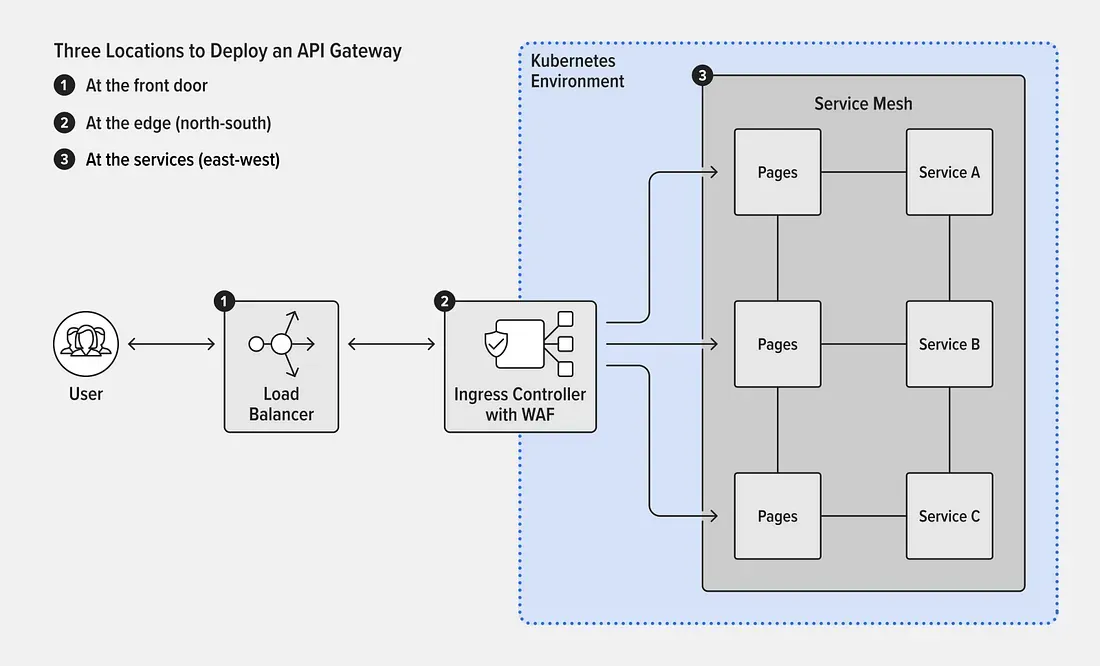
The original request flow followed a familiar enterprise pattern:
External B2B clients called https://xyz.com. DNS resolved the domain to a load balancer virtual server. The load balancer handled TLS termination, path-based routing, and network security rules, then forwarded traffic to Kubernetes ingress and backend services.
While functional, this design came with an implicit trade-off. From the perspective of downstream systems, all inbound traffic appeared to originate from enterprise-controlled infrastructure. The actual consumer calling an API was effectively hidden.
This limitation surfaced repeatedly during incidents, audits, and partner conversations — not as a theoretical concern, but as a daily operational friction.
The Quiet Cost of a Network‑Owned API Load Balancer Gateway
The most visible impact was loss of consumer identity. When issues occurred, identifying which partner was affected required manual correlation across logs, certificates, and timestamps.
Operational ownership was also fragmented. Routing lived in load balancer configurations, certificates were managed by infrastructure teams, and API behavior was partially embedded in application code. Troubleshooting required coordination across multiple teams, slowing response times and increasing cognitive load.
Finally, the platform lacked API-level intelligence. Load balancers are excellent at moving packets reliably, but they are not designed to provide insights into API usage, consumer behavior, or contract adherence. Capabilities increasingly expected in modern B2B ecosystems — analytics, quotas, and lifecycle governance — were simply absent.
These were not abstract shortcomings. They were operational constraints that shaped how safely we could evolve and how confidently we could scale.
The Decision: Move to Edge, Not the Backend
The realization was simple but decisive: a load balancer is not an API front door.
Network components are optimized for availability and transport efficiency. API gateways exist to solve a different problem space — identity, governance, observability, and lifecycle management. Conflating these roles created long-term operational debt.
Rather than layering Apim behind the existing load balancer, we chose a cleaner model: expose APIs directly through Apim virtual hosts and remove the load balancer from the external traffic path.
This did not weaken security or availability guarantees. TLS termination moved to Apim using enterprise-managed certificates. High availability was preserved through Apim's multi-node architecture combined with DNS-based routing. Network security zoning remained intact — responsibility simply shifted to the layer designed to handle API concerns.
From the outside, nothing changed. Clients continued to use the same domains and endpoints. Internally, responsibility boundaries became explicit.
Apim Edge Virtual Hosts as the Enabler
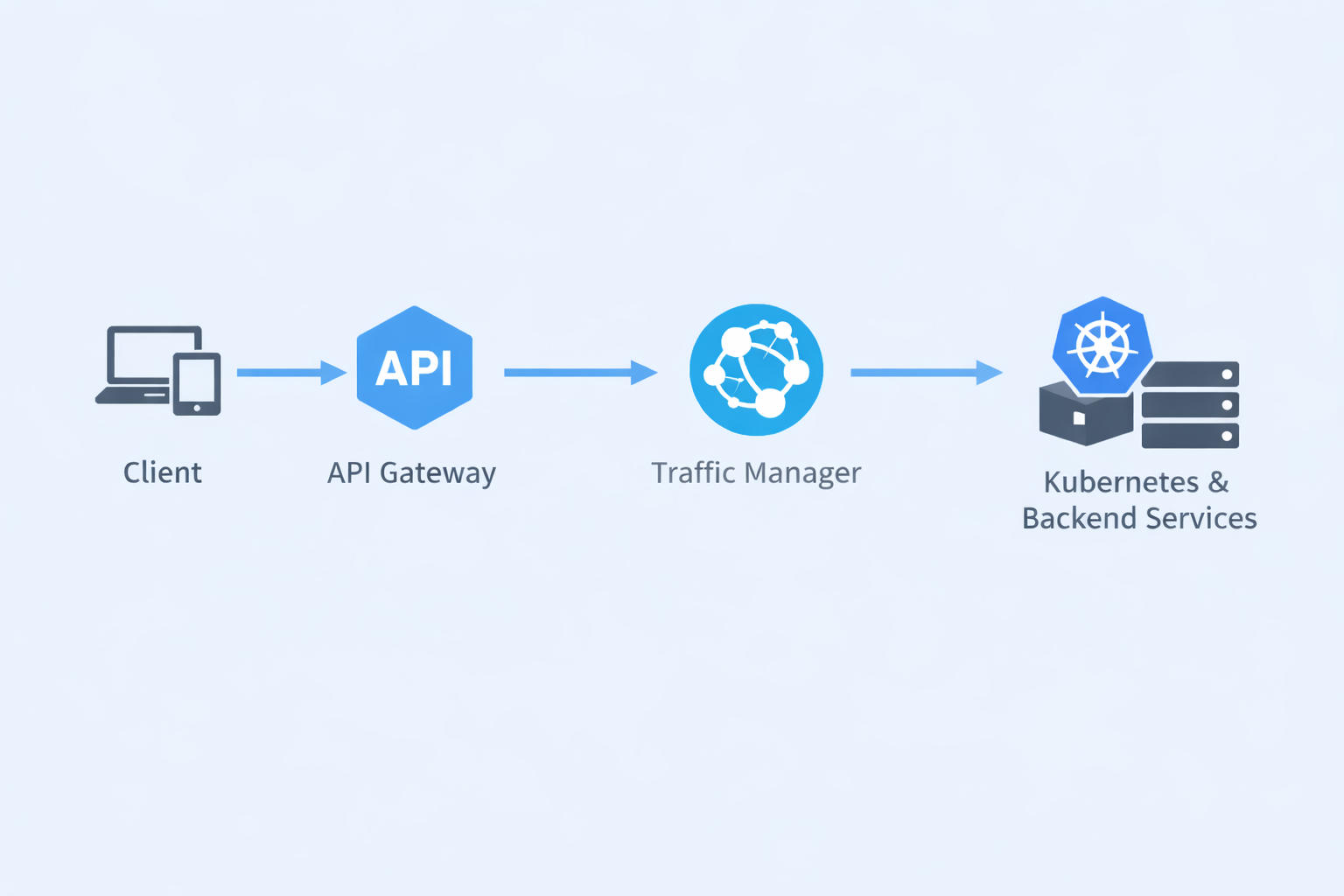
This shift was made possible by Apim virtual hosts, which allowed us to bind existing public domains directly to the API gateway without rewriting URLs or breaking consumer contracts.
Certificates, host-based routing, and TLS termination were handled centrally at the API layer. DNS changes were minimal and reversible, making the migration both safe and controlled.
From a consumer perspective, nothing changed. From a platform perspective, everything did.
What Moving the Apim Edge Unlocked
Once the API edge moved to Apim, traffic stopped being an abstract flow and became something we could reason about.
Geographic origin, latency patterns, and regional concentration were no longer inferred indirectly. They were visible immediately at the edge.
Visibility was not limited to where traffic originated. For the first time, each request could be traced end-to-end with full consumer context.
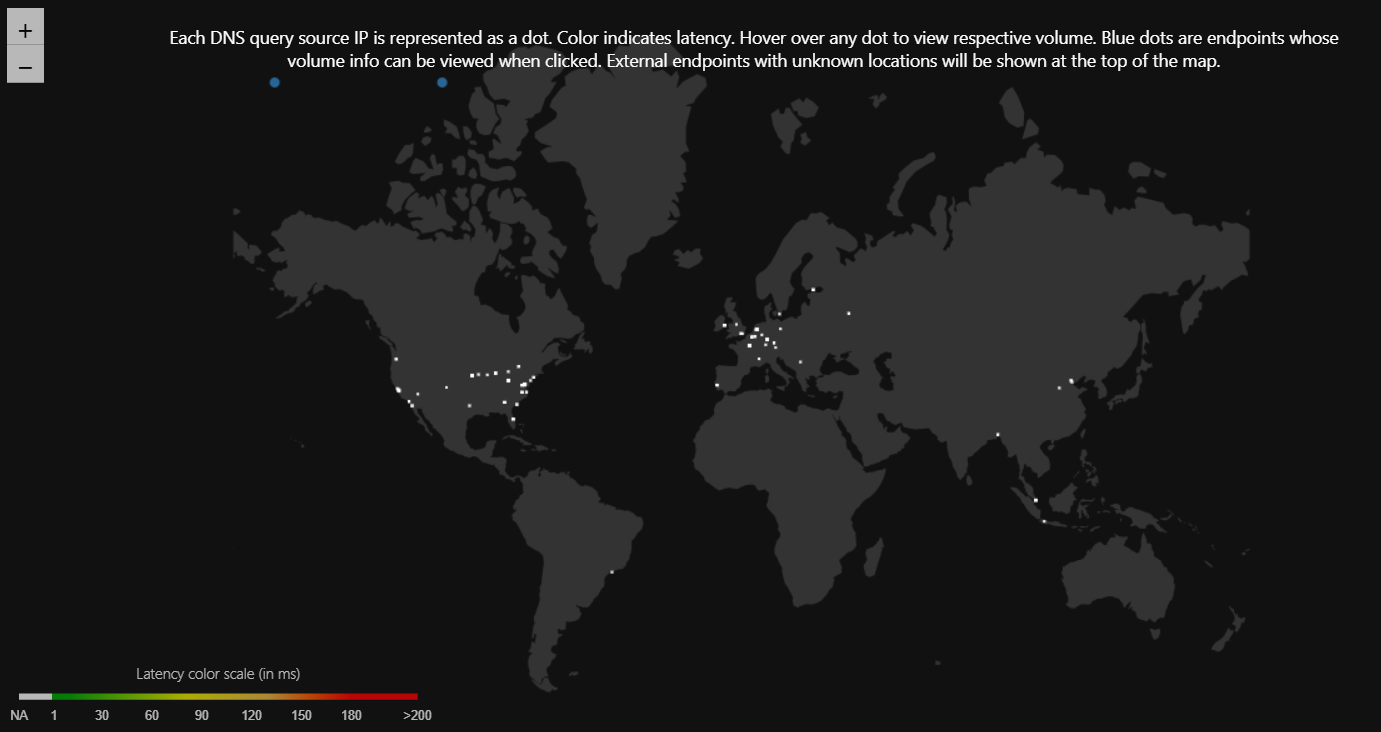
Rather than reconstructing incidents from fragmented logs, operators could inspect a single request and immediately understand who called the API, which policies were applied, and where time was spent.
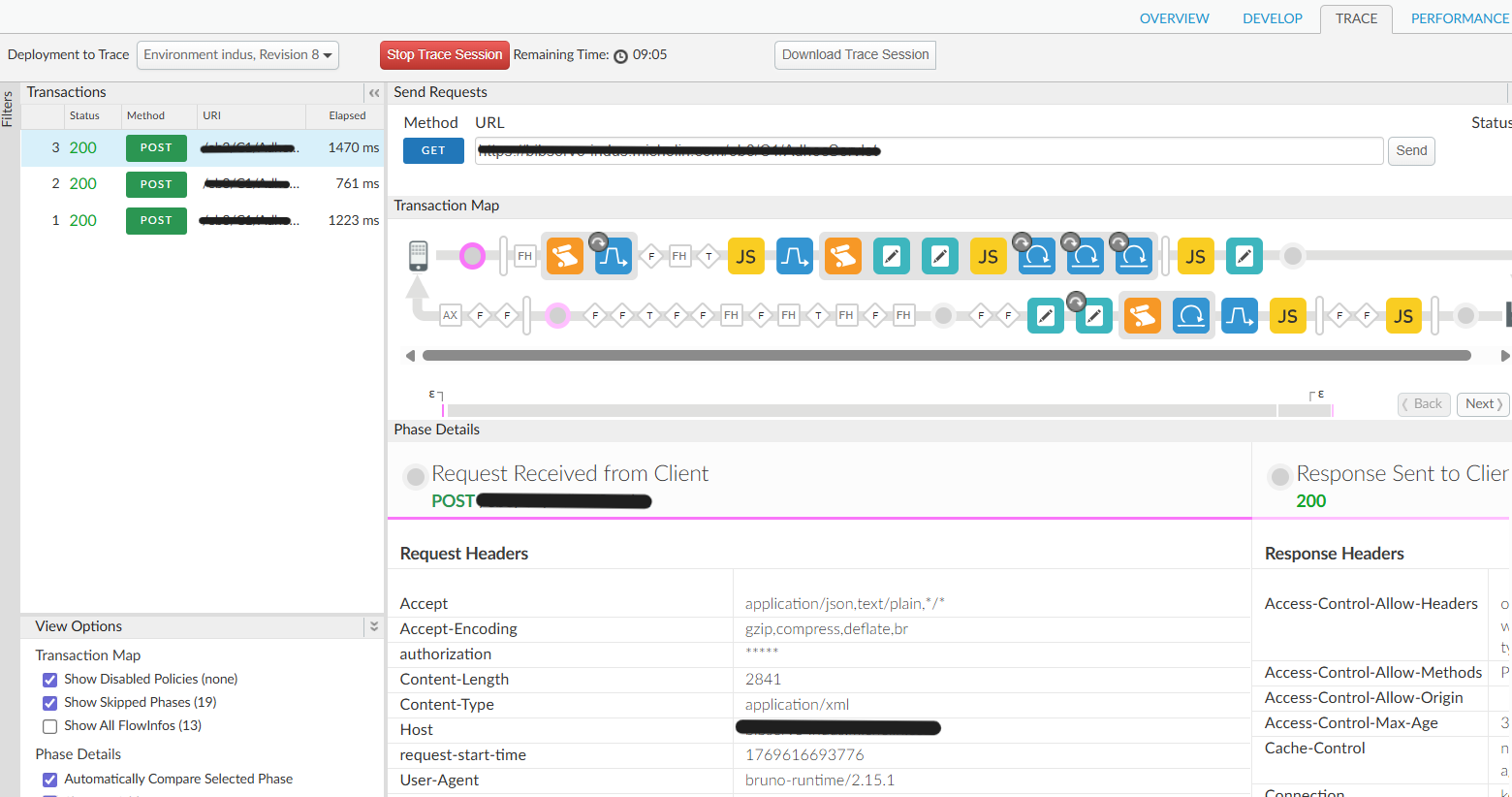
Consumer identity, usage behavior, and execution flow became first-class signals. Peak usage windows, anomalous patterns, and client-specific issues surfaced naturally — without cross-team correlation or manual reconstruction.
This marked a shift from infrastructure-centric monitoring to true API product observability.
Turning Insight into Operational Advantage
These new insights translated quickly into tangible operational benefits.
Incident triage became faster because impacted consumers were immediately identifiable. Rate limits and quotas could be tuned based on actual usage rather than assumptions. Security investigations focused on abnormal behavior instead of broad traffic suppression.
Partner conversations also changed. Discussions became data-driven and transparent, grounded in shared visibility rather than anecdotal evidence. Apim did not just centralize traffic — it changed how we reasoned about API usage and responsibility.
Supporting Layers, Deliberately Boring
Other platform components retained focused roles by design.
Azure Traffic Manager was introduced after Apim to handle DNS-level routing and global resiliency. It was intentionally kept out of API concerns and used strictly for traffic distribution and availability.
Traffic Manager operated in weighted routing mode, allowing inbound traffic to be proportionally distributed across multiple Kubernetes clusters where the same services were deployed. This enabled controlled traffic splits between regions or environments, gradual traffic shifts during cluster onboarding, and safe capacity balancing — all without exposing this complexity to API consumers.
Apim remained unaware of cluster topology. From the gateway’s perspective, it continued routing to a stable backend target, while DNS-level weighting determined where traffic ultimately landed.
Kubernetes and backend services themselves remained unchanged. Application teams continued to focus on business logic and service reliability, while the platform handled routing, resiliency, and failover externally.
Each layer operated within its natural domain:
DNS for global traffic distribution,
Apim for API management and governance,
Kubernetes for application runtime.
Migration Strategy: Controlled and Reversible
Risk was managed through a phased approach. Virtual hosts and certificates were prepared in advance, DNS TTLs were reduced and DNS switch for domains was done to Apim resolution, and changes were validated in non-production environments.
Partners were onboarded gradually, latency and error rates were closely monitored, and a rollback path was always preserved. The production cutover ultimately consisted of a DNS switch — observable, reversible, and controlled.
Closing Thought
Modern API platforms demand clarity of responsibility. By removing the load balancer from the API front door and adopting Apim as the primary gateway, we simplified the architecture and dramatically improved how we operate it.
Sometimes the most powerful optimization isn’t adding another layer — it’s removing the one that no longer belongs.