
Moving from orchestration to choreography - Part 3

{kind=link}

Here our journey together almost comes to an end with the third article of this series "moving from orchestration to choreography". In part 1, I explained how we convinced our organization to get rid of our Business Process Management solution and adopt an event driven solution with a choreography of micro services. Part 2 was focused on assembling a team during a COVID-19 locked down.
Now in Part 3, we'll share what happened in real life. And for this, we'll give the floor to the team who did it. We'll go through several perspectives so you'll have a 360° overview of these big changes. I hope you'll enjoy it.
The 'tech lead' point of view
By Benjamin Dumas (CGI)
When I joined the Team at the beginning of the first lockdown, one of the first thing we had to create was a core technical team, with a real ‘devops mindset’, able to handle all sort of tasks, from writing, having a critical point of view on functional specs to deploy to support any micro application in production.
From a technical point of view, we had to provide a real ramp up on the Kafka Streams framework and understand the internal behaviour of a Kafka Cluster. We also had to improve our skills on our overall technical stack: SpringBoot, Kubernetes, Gitlab… Our mindset was to avoid having a single team member on a specific topic; we wanted to have the ability to challenge each other on each technical topic. Another axis that required us a real in-depth work, was to accompany the existing ecosystem in its shift towards the construction of an application based on an Event Driven Architecture.
Looking at our ways of working: we started by force of habit with the working methods of the historical team that managed the ancestor of our new system. However, we quickly realised when carrying out the first developments, that the questions we were asking ourselves during development were not answered in the historical specifications. Elements that have a great impact on the technical design for us, such as the granularity of the events and their temporality were not covered by the first specifications, which caused us a good deal of rework at the beginning. As our knowledge of Kafka Streams grew, so did our beliefs about the best way to work with it, but they clashed with the habits of the team. We had to explain it to the rest of the team and convinced them that it was the best way of working for the project overall.

The 'software engineer' point of view
By Clement Vacher (CGI)
As a software engineer, being there at the premises of this project presented a few challenges. The main one, while simple as a statement revealed to be the main part of our job as pioneers:
how do you make a young, event based, microservice-oriented solution accessible and attractive for java developers, without prior knowledge?
The technology was barely out of the cradle; therefore the initial goal was to find out what its limits could be, and then find a way to standardize its use. The ambition for the project had the bar set quite high, with a couple hundred microservices in sights.
One of the first challenge we faced was the absence of error handling; in case of something going wrong during the processing of an event, nothing would be able to "catch" the error. This discovery led to a first set of technical solutions, with the creation of a framework that would allow for the streaming process to continue without crashing, using a generic error-handling mechanism.
public static <K, V, EV>KStream<K,V> processResult(KStream<K, ProcessingResult<V, EV>> inputStream) {
var branches = inputStream
.filter((k,v) -> v != null) // Remove null value from stream
.filterNot((k,v) -> v.getValue() == null && v.getException() == null) // Remove nprocess result will null content
.branch(
(key, value) -> value.isValid(), /* Any error occured */
(key, value) -> true /* error case */
);
var errorOutput = branches[1].mapValues(ProcessingResult::getException);
var nominalOutput = branches[0].mapValues(ProcessingResult::getValue);
errorOutput
.map( (k,v) -> new KeyValue<>(k == null ? "null": k.toString(), (ProcessingException)v))
.transformValues(GenericErrorTransformer::new)
.to(StreamExecutionContext.getDlqTopicName(), Produced.with(Serdes.String(), StreamExecutionContext.getErrorSerde()));
return nominalOutput;
}The second axis came from our ambition: knowing that we had a couple hundreds micro-services ahead of us, it seemed vital to us to figure out how to standardize the code implementation, through factorization and an abstraction layer preventing common setup mistakes during development phase. This abstraction layer was integrated in the same framework mentioned previously, and allows us to fully implement a deployment-ready microservice in a matter of a few days, if not hours, versus a couple weeks at the beginning of the project. Here is the abstract class that each micro-service app inherits from:
public abstract class StreamInitializer {
// ... traditional attributes with properties, logger, topology & stream
public void init(Consumer<StreamsBuilder> topologyFunction, String dlqName){
StreamExecutionContext.configureDlqTopicName(dlqName);
StreamsBuilder streamsBuilder = new StreamsBuilder();
topologyFunction.accept(streamsBuilder);
topology = streamsBuilder.build();
kafkaStreams = new KafkaStreams(topology, StreamExecutionContext.getProperties());
Runtime.getRuntime().addShutdownHook(new Thread(kafkaStreams::close));
kafkaStreams.setUncaughtExceptionHandler( (thread, e) -> {
ErrorHandler. closeAndLogStreams(StreamExecutionContext.getProperties().getProperty(APPLICATION_ID),e);
if(springCtx != null) {
springCtx.close();
}else{
logger.warn("No Spring Context set");
}
});
//State listener to force shutdown of SpringBoot context on ERROR state
kafkaStreams.setStateListener((newState, oldState) -> {
if(newState.equals(KafkaStreams.State.ERROR)){
if(springCtx != null) {
springCtx.close();
}else{
logger.warn("No Spring Context set");
}
}
});
kafkaStreams.start();
}
@GetMapping("ready")
public ResponseEntity<String> readinessProbe() {
if(null != kafkaStreams) {
logger.debug("Kstream current state : " + kafkaStreams.state().toString());
if( kafkaStreams.state() == KafkaStreams.State.REBALANCING) {
//If All thread (via StreamThread.State are starting /created dont trust KafkaStream status we are not rebalancing where are starting (probably no connection to the brocker for now)
var starting_thread_count = kafkaStreams.localThreadsMetadata().stream().filter(t -> StreamThread.State.STARTING.name().compareToIgnoreCase(t.threadState()) == 0 || StreamThread.State.CREATED.name().compareToIgnoreCase(t.threadState()) == 0).count();
if (((long) kafkaStreams.localThreadsMetadata().size()) == starting_thread_count) {
return ResponseEntity.status(HttpStatus.NO_CONTENT).build();
}
}
return kafkaStreams.state() == KafkaStreams.State.RUNNING || kafkaStreams.state() == KafkaStreams.State.REBALANCING ?
ResponseEntity.ok().build() : ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE).build();
}
return ResponseEntity.badRequest().build();
}
@GetMapping("liveness")
public ResponseEntity<String> livenessProbe() {
if(null != kafkaStreams) {
//Check if KStream is dead
return kafkaStreams.state() != KafkaStreams.State.NOT_RUNNING ? ResponseEntity.ok().build() : ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).build();
}
//Not yet initialize
return ResponseEntity.status(HttpStatus.NO_CONTENT).build();
}
@GetMapping("expose-topology")
public ResponseEntity<TopologyExposeJsonModel> exposeTopology() {
if(null != topology) {
return ResponseEntity.<TopologyExposeJsonModel>ok(ConvertTopology.convertTopologyForRest(kafkaProperties.getProperties().get(applicationIdKey), topology));
}
//Not yet initialize
return ResponseEntity.status(HttpStatus.NO_CONTENT).build();
}
}The last axis was centered around a well known issue when dealing with multiple systems: how do we ensure non-regression without spending months in testing phases?
Given the scale of the project, and the roadmap that we had initially planned for, this quickly became a core concept. We had to make sure that development practices, along with a robust CI/CD chain reflected this.
Automated unit testing had to go as deep as possible, and we quickly set a standard for code coverage to ensure future changes and fixes would not have undesired side effects. Again, this third abstraction layer was integrated to our quickly growing framework.
public abstract class TopologyTestBase {
// Generic topology DLQ TOPIC for each topology in test case
public final static String DLQ_TOPIC = "DLQ_TOPIC";
protected TopologyTestDriver testDriver;
private String directory = "C:/tmp/kafka-streams";
// Fake SchemaRegistryUrl to connect Serdes with Toology in same mock context
private String mockSchemaRegistryUrl;
@BeforeEach
void setUp() {
schemaRegistryScope = this.getClass().getName();
mockSchemaRegistryUrl = "mock://" + schemaRegistryScope;
serdeConfig = Collections.singletonMap(AbstractKafkaAvroSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG, mockSchemaRegistryUrl);
StreamsBuilder builder = new StreamsBuilder();
Properties properties = new Properties();
properties.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, "test");
properties.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "dummy:1234");
properties.put(AbstractKafkaAvroSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG, mockSchemaRegistryUrl);
Properties resetPrefixProperties = new Properties();
resetPrefixProperties.setProperty(TOPIC_PREFIX, "");
StreamExecutionContext.registerProperties(resetPrefixProperties);
StreamExecutionContext.configureDlqTopicName(DLQ_TOPIC);
StreamExecutionContext.setSerdesConfig(serdeConfig);
StreamExecutionContext.setNumPartition(1);
applyProperties(properties);
applyTopology(builder);
var getInitialDriverDate = getDriverDate();
// Initialized at Wednesday 1 January 2020 00:00:00
var topology = builder.build();
// System.out.println(topology.describe());
testDriver = new TopologyTestDriver(topology, properties, getInitialDriverDate);
}
@AfterEach
void tearDown() {
try {
testDriver.close();
} catch (Exception e) {
FileUtils.deleteQuietly(new File(directory)); //there is a bug on Windows that does not delete the state directory properly. In order for the test to pass, the directory must be deleted manually
}
MockSchemaRegistry.dropScope(schemaRegistryScope);
}
}The resulting product enabled developers in a safe, efficient and friendly ecosystem, which paved the way for our second set of challenges.
The most valuable part of our work came from something outside of that development ecosystem. Working with a team made of many members, most of them without technical background, meant that we had to find a way to communicate efficiently and speak the same language. Everyone around the table, whether business, dev, ops, support or architect needed to understand what was relevant to them, using the same ubiquitous language.
This second framework was created using very simple visual tools, and is twofold. First comes the "master topology" (also called macro topology). This diagram :
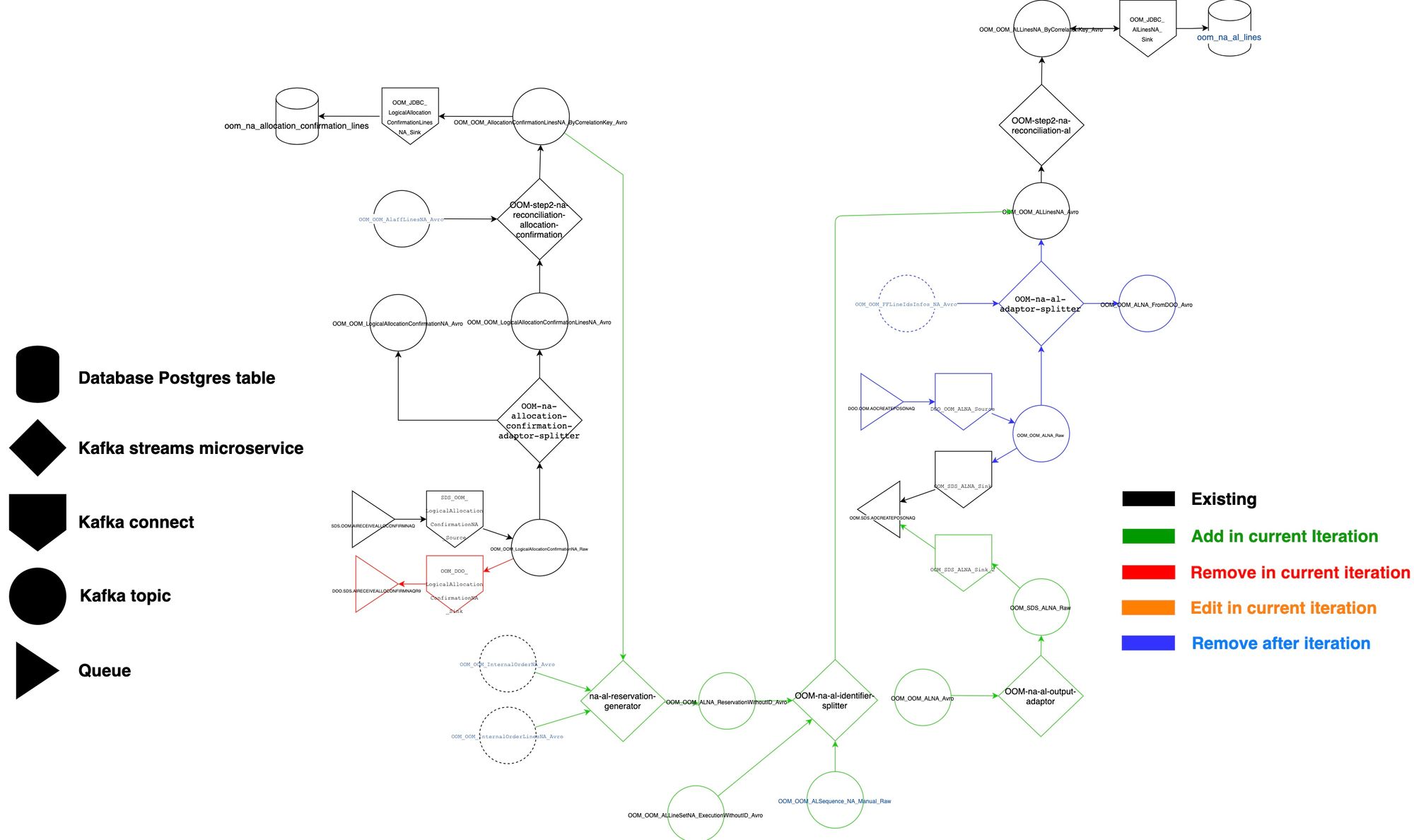
- features the exhaustive list of technical components for each functional scope, with their precise names (connectors, topics, microservices, databases, queues)
- is like a map, allowing the reader to figure out the pathing of each event
- can be used as a discussion tool for both technical & functional architects with the team
- is useful for microservice deployments, maintenance and initial problem analysis
Second, the "micro topology" diagram as depicted below
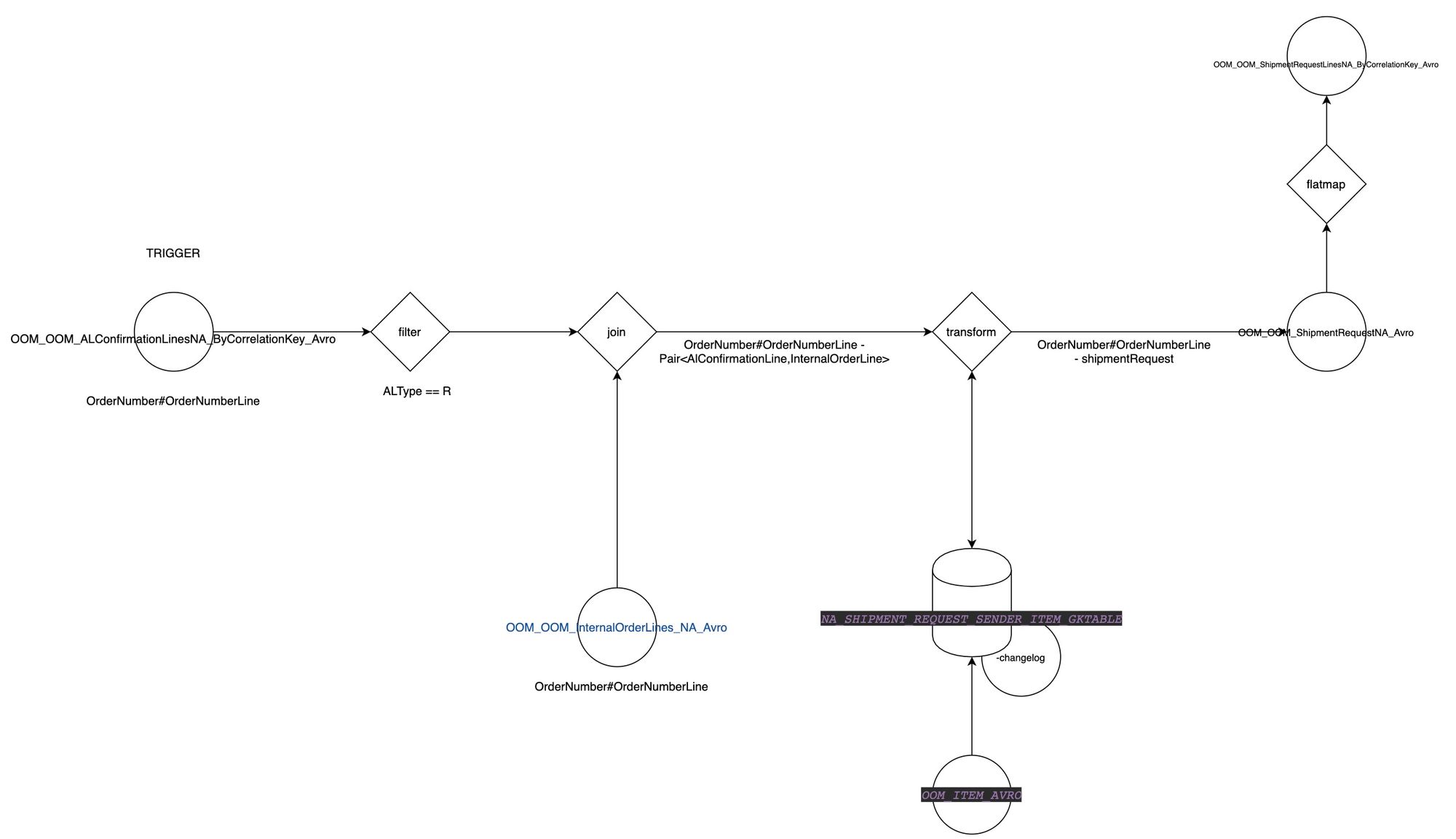
- acts as a visual description of the code for each microservice
- features a more in depth view, listing the kafka stream "nodes" or operations (join, split, merge, map, branch)
- acts as an in depth technical specification for less experienced developers
- can include business processing rules translated in technical terms (such as branching algorithms, stateful/stateless operations, etc.)
- can be used to figure out what the technical limitations might imply (partitioning, event distribution)
Using those two frameworks (technical & exchange) enabled us to tackle most of our issues. But obviously, this is not a Disney movie, and we would be lying if we told you that everything went smoothly. While this seems ideal, ideals tend to find themselves lacking when faced with reality. One of those realities was having to deal with legacy systems without an event driven architecture, and using outdated communication standards. This meant lots of head scratching especially when dealing with business reporting, and data aggregation from up to 20 different sources, trying to compensate and avoid breaking changes. While we came out of those trials with our head high, There are still a lot of challenges ahead of us, especially around the different reworks of the legacy applications.
Our expertise, acquired through challenges and built upon the described frameworks, has yet to grow from sharing with other programmers and teams, tackling more challenging problems using data retention, replayability and stream processing.
The 'devops' point of view
By Thomas Jouve (Sopra Steria)
As a DevOps onboarding the project, not yet in production, the main goal was to work on building a robust pipeline to ship all our Kstreams, but also automate topics & Kconnect provisionning. Given the microservice oriented architecture of the product, the need for a dynamic CI quickly arised; Automated unit testing to avoid code regressions, along with some tooling for integration testing became a must have. When it came to project layout, we decided to have one microservice (and stream) per module, some common libraries for factorization, and finally separate packages for the avro models.
At the time, the idea was to have a single project for all microservices, so that changes would easily impact the whole project without having cumbersome steps in between. With 15 microservices, that seemed like the best idea to simplify release trains and pipeline complexity.
Or so we thought...
All our testing was done with simulated data, a very low event throughput, and with message arriving at the expected time.
We quickly learned (the hard way) that operating the solution wouldn't be possible without any insight on the microservice's state, down to the Kafka Streams level. Head scratchers such as "why are they alive, but not processing any messages?", "why is it stuck in a reboot loop?" or more specific "what are those random rebalances for?" were quite common, and called for action.
To address those issues, we setup a monitoring stack based on prometheus/grafana aggregating data from kafka, kubernetes and our streams. We dug deep in all the available metrics to figure out which ones were the most relevant, and which ones would reveal the bottlenecks responsible for our myriad of issues.
This turned out to be a full time job for a while, given the wide range of possible root causes : code bugs, stream config, kafka brokers, kubernetes cluster config, pod sizing, and even network hiccups. Because guess what? all the fallacies of distributed computing are really true ;) .
Another challenge we faced, was the fact that all of those diagnoses had to be made with all the possible culprits in mind, and required broad knowledge on all of them (Kafka brokers-workers / Kstreams / Kconnects / Kubernetes sizing / deployments / statefulsets / configmaps / general infrastructure). This work allowed for live technical issues resolution, but didn't cover the functionnal side of things and also didn't allow us to be proactive instead of reactive.
In order to counter this, we took advantage of one of the very core concepts of kafka : event retention. Using a replicator, we were able to duplicate all the events from the production environment to a testing environment, on which we are then able to test new versions of the microservices, and also have a realistic amount of events; all of this for a dime.
Today the project represents more than 400 µServices instances in production (= around 100 Kstreams replicated on two K8S Clusters), 150 Kconnects and 400 Topics (excluding KStreams repartition / changelogs topics); and about as many components for our other four DEV/QA environments.
We've clearly gained some expertise on sizing, fine tuning and operating Kstream µServices. Although most of our challenges seem behind us, our trials are far from over; so here are some of them, profiling on the horizon : handling of a bigger CI / code base with frequent technical transversal updates, monitoring scalability, automation for housekeeping tasks ...
On top of all this, we have a need for automation tooling for topics / Kconnect / Schema provisioning on all our Kstreams environments.
A microservice architecture comes with a lot of benefits, but is not without its fair share of troubles; dealing with multiple versions in parallel is, of course, inherent to any self-respecting product.
The "team lead" point of view
By Marianne Baudot, Michelin
As a team leader, I will not talk about planning or budget but about how I experienced the post-booster phase (we covered this booster concept in part two of this series).
The first challenge I faced was recovering the material from the various workshops framed by the Scoping 360 methodology and launching operations. This incubation period allowed me to understand and apprehend the scope. But not being technical, one of the difficulties I had, was to tame our technology stack to accompany my teammates.
After these three months of framing I found myself faced with the following problem: how to get the trust of my ecosystem (top management, business stake holders, contributors ...) given the little maturity I had on this new technology when at the same time our main message was:
Within the next two years, we will migrate all order orchestration processes from one technology to another. A Technology on which we have no experience. And all this while limiting the duration of test phases with a BigBang deployment strategy.
Pretty scary right? To demonstrate that our testing strategy was adapted, we spend quite a lot of time to argue and explain it. For some folks, going through a power point presentation was adapted. For others, the narrative approach (similar to the famous Amazon 6 pages memo) was used. It allowed me to bring meaning to our choices, share our reflections & thoughts and explain our conclusions. This way of proceeding is especially appropriate as it helps people to understand the journey we've been through.
This testing strategy as well as the deployment strategy was revisited for each MVP. This exercise was facilitated thanks to the heritage of the scoping 360 method. Depending on the technical and functional challenges we had to face, I was able to select and lead the workshops independently in a ligh Scoping 360 approach, taylored in a way to the current challenges we were having.
Our initiative was somewhat a technological revolution but it was not limited to it. It had to be supported by a change of mindset and therefore different work habits. This change was not so well experienced by my teammates, especially by the team members who switched from DOO (the old system) to OOM (the new one). This phenomenon created a two-speed team. We worked day by day to fill this gap through training, shadowing and demonstrations.
On a personal note, it was as a real journey on several levels. On one hand of course, I had to step-up on the technology. By no means, I can claim to be streaming expert but I do understand the underlying concepts and if I did not spend time to get into this, I would not have been able to lead my team. This initiative was about creating a product that would help to decomission an old one after a migration phase. I had to complete my "project management toolkit" with other tools more product oriented. It took me some time to adapt.
This great adventure is currently a success thanks to the support and unfailing involvement of all the actors.
Take aways
I know we shared a lot in these 3 articles. And frankly, we did not disclose everything that happened in the last 18 months. I would be happy if you get out of it these key insights:
- An Event driven architecture is not simple. It requires a mindset shift in the way we design. The streaming topology concept must be understood by team members whether they are IT or not ! Waiting for this to happen (and it takes time), expect some rework along the way.
- Assembling a long live team with the appropriate skills is absolutely key. And if you need to get help from a consulting company, professional services or whatever, please consider this investment. You won't regret it.
- From day one, a real CI/CD pipeline and an obsession for automation is a must when you're implementing an event driven solution with microservices
- Go quickly in production (even with a small increment) to reassure your ecosystem, and iterates quickly. You may fail some move to production, but the more you practice the less probable it becomes.
- Observability is a must and it's not easy to achieve. But if you don't think about it right from the beginning, it will affect your capacity to overcome production issues that will arise because yes there will be issues.
- The Kafka technology allow you to think about regression testing differently. Start to capture as many messages as you can in Kafka, so you can endlessly test your streams against them. You can even prove that one version of your program delivers better results than the old one. Why? because you can compare the two runs.
I am just the messenger here. In this article, you saw some members of that team reflecting on this last 18 months adventure. I can not end this without congratulating warmly those explorers. They were the first to get so deep into the streaming paradigm at Michelin. They struggled and suffered for sure. At some point, they were overwhelmed by doubts. But their comitment and involvment were so complete that they've made it. First, their solution is working just fine. And they became a reference internally for sure, and quite humbly externally too.
We can always complain that it took them a little bit longer than expected. But it was not their call when they had to provide a roadmap upfront. That's maybe one of the key findings here too: long roadmaps are a fallacy. It always surprises me every time I see "plans" out of them. That may be a topic for a next article ;)