
Drupal on Kubernetes (a.k.a stateful application)
The production implementation detail of our API portal developed on top of Drupal and hosted as a stateful application on a Kubernetes cluster.

 by %23Michelin&pic=https://blogit.azureedge.net/images/2021/04/drupal-1.jpg&ralateUid=&language=en){kind=link}


Introduction
On DDi we are starting our journey to API Monetization. We have more and more customers who are asking about accessing our data and ready to pay for it. To meet customers expectations and provide them easy to use services helping them create value for their own, Michelin DDI is launching a Service Catalog, a great showroom gathering all available Michelin Connected Mobility APIs. This approach is aligned with Michelin strategy around developing services & solutions in the mobility market.
This article aims to present a production implementation of our API portal developed on top of Drupal and hosted as a stateful application on a Kubernetes cluster. Among other things, you will find one of the technical challenges we encountered: the elasticity of the solution.
The Context
API Monetization is about different tiers and services, and below I will describe the showcase part: how we implemented it and the way we handle the its elasticity.
Our showcase is based on Drupal (v9… no, you don’t need to know 😆) a famous CMS. We’ve seen several implementations of Drupal on Infrastructure as a Service, and it was the solution proposed by our integration team. I was quite worried about such approach due to our requirements and the complexity to be … elastic and highly available.
Components used in Drupal Architecture
DDi showcase is the first touchpoint prospects will have with us. As the first impression is often decisive in the success of a digital service that’s why it’s important to provide a best-in-class experience to maximize the famous “prospect to revenue”. Obviously, there is a big User eXperience challenge behind hosting this showroom so it has to be Highly Available and scalable was equally important.
Here below is a simple architecture overview of a typical Drupal implementation.
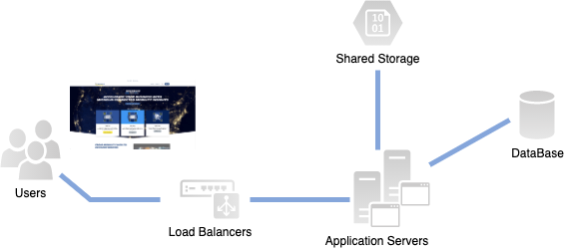
Drupal needs shared persistent storage
As said before, we decided to instantiate our Drupal on a Michelin Kubernetes platform (hosted on Microsoft Azure) to manage elasticity and high availability.
First, regarding Kubernetes features, Drupal is a stateful system and has one important requirement that we had to cover before starting: shared & persistent storage, with good quality of service regarding throughput.
This storage is a must-have to allow sharing content between Drupal pods and to persist all content brought by users even if we are losing or spawning new pods.
There are several different storage bricks available in the Kubernetes ecosystem and our Michelin implementation:
- Ephemeral Storage
- Azure Files ‘CIFS’
- Azure Disk
- Azure Files ‘NFS’
Based on the solution on the shelf, the choice was made to use Azure File ‘NFS’. Let us describe what were the constraints of other solutions available:
- With Ephemeral Storage, the application content is removed any time the pod is deleted (as suggested by the name) which does not satisfy our persistence need.
- Regarding Azure Files ‘CIFS’, this solution is based on file share. Kubernetes creates on demand the volume on top of the Azure File feature. The main drawback for our use case if that this is not entirely POSIX compliant. No way to modify file and folders access mode and their ownership for everything created on that kind of volume. It's obvious that there is an issue with this as we are talking about a CMS solution managing content and access permissions on what you expose on the Internet.
- Azure Disk is based on the block-devices created on-demand by Kubernetes using Azure API. Disk(s) created are attached to the VMs (k8s node) where the pod runs. We can manage quite deeply POSIX accesses (👍), the throughput/performance is there as we can use Premium SSD. But, that being said, the major issue for us was the number of disks you can attach to a VM. It's limited in Azure by the size of the VM (K8S node) which clearly impacts the scalability of the solution.
- Last solution, Azure File ‘NFS’, let’s see if it covers our need. Azure File ‘NFS’ is based on Azure file shares, created on demand (Okay, after asking our ❤️’ing K8S Team) like the solution Azure File ‘CIFS’. The difference is on the way to access the volume. NFS accesses avoid issues around the number of disks you can attach to a VM. And it's fully compliant with POSIX! By chance, this solution is available in the region we were running our K8S, so Drupal. Okay, let’s go!
Note: as of now, the K8S team is working on setup Ceph cluster within Kubernetes using Rook.
Here below, the PVC implementation.
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: drupal-data
spec:
storageClassName: nfs-premium
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
Drupal implementation on Kubernetes
Drupal is working on top of 3 tiers: Web Server + PHP-FPM + Database. We decided to use NGINX as a Web Server and PostgreSQL as a database server.
Here below is the architecture:
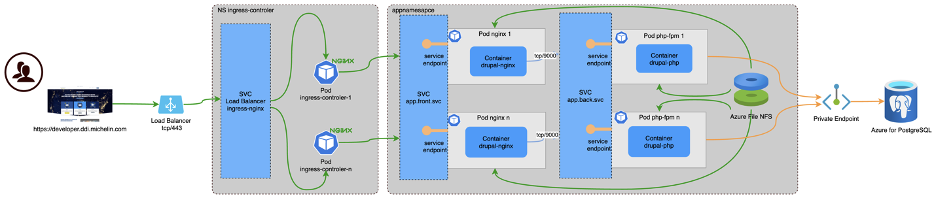
As said before, our goal was to be able to be elastic. To achieve this, we created 2 pods in K8S:
- One for NGINX
- One for PHP-FPM
We can then scale each tier independently and consume fewer resources. For instance, in our performance tests, we saw that PHP-FPM was consuming much more resources than NGINX so we adapted the allocated ressource for NGINX accordingly.
HPA & PDB stands for … HA & Elasticity
Kubernetes is coming with a way to manage elasticity, called HPA HAP is responsible for scalling containers running as pods horizontally in the Kubernetes Cluster. It increases or decreases the number of replicas for a given application based on the following metrics threasholds, values that you define, see below yaml.
HPA, since Kubernetes 1.6 (or 1.2 Alpha) is supporting multiple metrics, that allows you to scale your application pods on specific/custom metrics. It means you can manage the elasticity of your app quite deeply. For more information HPA, have a look here.
We put HPA capability on both pods, NGINX and PHP-FPM.
The HPA (Horizontal Pod Autoscaler) is implemented like this:
---
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: drupal-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: app-drupal-php
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
- type: Resource
resource:
name: memory
target:
type: Utilization # or use ‘AverageValue’ if you want to use specific limit.
averageUtilization: 80 # if ‘AverageValue’ used above, here averageValue: xxMi
---
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: drupal-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: app-drupal-nginx
minReplicas: 2
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
We also want to achieve High Availability and as our Kubernetes cluster is continuously updated with new features, sometimes nodes of the cluster are rebooted. Our objective is to ensure that our application is still up and running regardless those reboots. To manage this part, we activated the PDB (Pod Disruption Budget)
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: drupal-minavailable
spec:
minAvailable: 1
selector:
matchLabels:
app: app-drupal-nginx
---
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: drupal-minavailable
spec:
minAvailable: 1
selector:
matchLabels:
app: app-drupal-php
Let’s see about service and the way we manage the exposition of Drupal
First, we need to define our Ingress and associated implementation.
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: drupal-ingress
namespace: appnamespace
annotations:
kubernetes.io/ingress.class: "public"
nginx.ingress.kubernetes.io/configuration-snippet: |
## Some security stuff
more_set_headers "Content-Security-Policy: script-src 'self'";
more_set_headers "X-Frame-Options: SAMEORIGIN";
more_set_headers "X-Content-Type-Options: nosniff";
more_set_headers "Referrer-Policy: strict-origin-when-cross-origin";
more_set_headers "Permissions-Policy: geolocation=(), microphone=(), camera=()";
more_set_headers "Server: 'I have no name!'";
more_set_headers "X-Drupal-Cache: 'Hosted with love'";
more_set_headers "X-Drupal-Cache-Contexts: 'by Michelin K8S'";
more_clear_headers "X-Drupal-Cache-Max-Age";
more_clear_headers "X-Drupal-Cache-Tags";
more_clear_headers "X-Drupal-Dynamic-Cache";
more_clear_headers "X-Generator";
spec:
rules:
- host: app.mydomain.michelin.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: drupal-nginx-service
port:
number: 8443
tls:
- hosts:
- app.mydomain.michelin.com
secretName: app-drupal-certificates
and expose the 2 pods services
---
apiVersion: v1
kind: Service
metadata:
name: drupal-nginx-service
namespace: appnamespace
spec:
selector:
app: app-drupal-nginx
ports:
- port: 8443
targetPort: 8443
name: https
---
apiVersion: v1
kind: Service
metadata:
name: drupal-php-service
namespace: appnamespace
spec:
selector:
app: app-drupal-php
ports:
- port: 9000
targetPort: 9000
name: php-fpm
You maybe ask yourself “why are they using NGINX while they have already an NGINX for ingress?” That’s a good question. Actually, the static content is not served by the php-fpm container and using static content is not yet supported on our Kubernetes Ingress controllers. As we are hurried by opening the service, we didn’t go further yet. The point is still opened, and we are working on it. As soon as the implementation will be done, we will update this post, stay tuned!
Deployment
Let’s have a look at the Deployment directive. As a reminder, the goal is to have 2 pods: 1 for NGINX & 1 for PHP-FPM and, scale them independently.
Some security first, we are not able to run any containers with a UID < 10 000 on our cluster. This is something to take into account when you create your images, all content served must be set with the right uid/gid.
---
kind: Deployment
metadata:
name: app-drupal-php
namespace: appnamespace
[…]
spec:
securityContext:
runAsUser: 10240
runAsGroup: 10240
# Must be the same than RunAsGroup
fsGroup: 10240
# to prevent issues when the pod crash and data are sensible to a specific chmod. By default it will be the gid specified for ‘fsGroup’.
# if you change the value fsGroup, the mecanism (Kube magic happens!!) will overwrite ownership access mode.
fsGroupChangePolicy: "OnRootMismatch"
[…]Some details about the volume we created to persist data which is created inside Drupal. This is what we describe a bit earlier in this post.
[…]
volumes:
- name: drupal-data
persistentVolumeClaim:
claimName: drupal-data
- name: drupal-settings
secret:
secretName: settingsphp
[…]
volumeMounts:
- mountPath: /var/www/html/web/sites/default/files
name: drupal-data
- mountPath: /var/www/html/private
name: drupal-data
subPath: private
- mountPath: /var/www/html/web/sites/default
name: drupal-settings
[…]
There are two different folders to persist. For ‘private’ as we are using the same pvc for the two containers, to ensure the content is not browsable, using ‘subPath’ directive ensure all content is going in this folder. You have also to put this in the NGINX app.conf (configMap).
Server {
[…]
location ~ ^/sites/.*/private/ {
return 403;
}
[…]To serve the static content, the same paths must be mount on the NGINX pod as describe below
- mountPath: /var/www/html/web/sites/default/files
name: drupal-data
- mountPath: /var/www/html/private
name: drupal-data
subPath: private Note here that I’m also using private as a subPath.
Backup the PVC content, yes indeed!
Okay, static content is fine and persisted. Wait, what about backup it?
Let’s see how it is in Azure first.
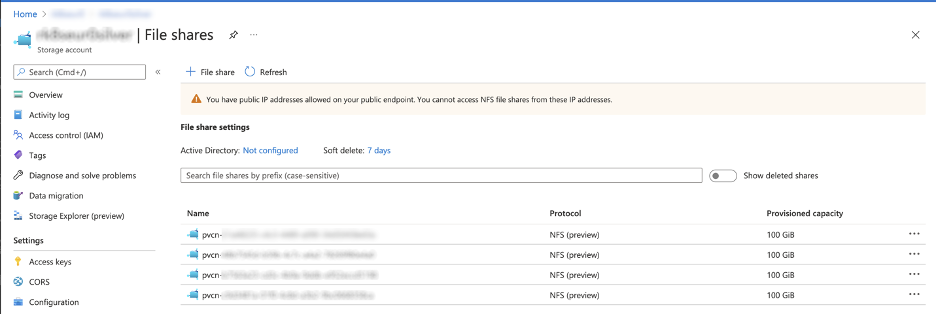

The availability of the data is managed by Azure thanks to “Replication: ZRS”. However, this is not preventing data corruption (i.e. applying new configuration, the wrong one, …). Important point, backup of the PVC content has to be done at the same time than the Database.
As of today epoch#1622526725 there is no way to backup such storage in Azure. We decided to use Kubernetes Cronjob feature.
---
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: app-pvc-backup
namespace: appnamespace
spec:
schedule: "0 1 * * 0" # @At 01:00 each Sunday, each week, each year.
successfulJobsHistoryLimit: 3 # how many completed jobs should be kept
failedJobsHistoryLimit: 1 # how many failed jobs should be kept
concurrencyPolicy: Forbid # to avoid concurrent execution
# The amount of time that Kubernetes can miss and still start a job.
# If Kubernetes missed too many job starts (100)
# then Kubernetes logs an error and doesn’t start any future jobs.
startingDeadlineSeconds: 300 # if a job hasn't started in this many seconds, skip
jobTemplate:
spec:
parallelism: 1 # How many pods will be instantiated at once.
completions: 1 # How many containers of the job are instantiated one after the other (sequentially) inside the pod.
backoffLimit: 3 # Maximum pod restarts in case of failure
activeDeadlineSeconds: 1800 # Limit the time for which a Job can continue to run
template:
spec:
restartPolicy: Never # If you want to restart - use OnFailure
terminationGracePeriodSeconds: 30
volumes:
- name: drupal-backup-cronjob
configMap:
name: drupal-backup-cronjob
defaultMode: 0777
- name: drupal-data
persistentVolumeClaim:
claimName: drupal-data
- name: drupal-settings
secret:
secretName: settingsphp
containers:
- name: app-pvc-backup
image: docker.registry.michelin/app/drupal-php:3.1
args:
- /bin/sh
- -c
- /scripts/backup.sh
resources:
requests:
cpu: '25m'
memory: '25Mi'
limits:
cpu: '50m'
memory: '64Mi'
volumeMounts:
- mountPath: /var/www/html/web/sites/default/files
name: drupal-data
- mountPath: /var/www/html/private
name: drupal-data
subPath: private #Avoid to have the content of the folder available to everyone.
- mountPath: /scripts/backup.sh
name: drupal-backup-cronjob
subPath: backup.sh
- mountPath: /var/www/html/web/sites/default
name: drupal-settingsWe are loading a script (thanks to a configMap) which is ran once a week to backup files and doing BDD backup, cf schedule directive at the beginning of the script.
Drupal performance tests, is it elastic?
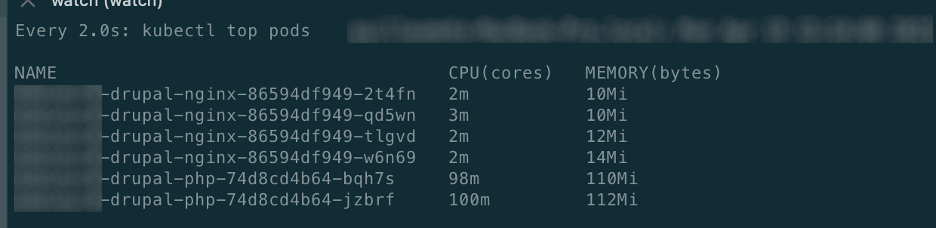
Now that HPA is in place, let’s have a look about how it is going when we load 250 users. We made a test scenario from simply browsing the web site to consuming our APIs. What is important is to have a common scenario linked to the nominal user’s behavior.
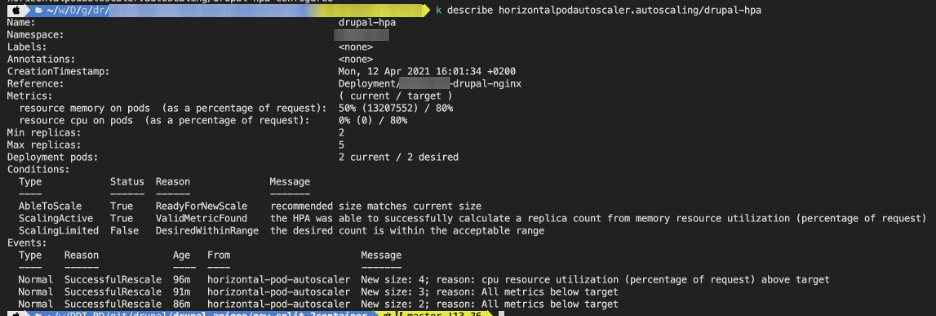
During load tests, see below
After load tests, see below
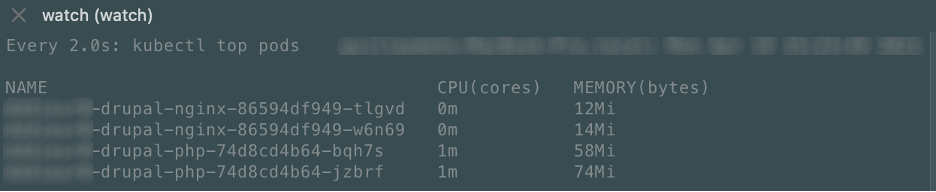
As you can see, it is scaling well and the results in term of performances were good too. Through these tests, we can say that Nginx pod is quite efficient when it comes to resource consumption (request / limit) and scale faster than the PHP pod. It's not a breaking news per say but we have proofs now ;)
Our journey is not complete though as we are still working on some performance tweaks like getting Docker images lighter.
Conclusion
You might have heard the term “Kubernetes is going to solve all the infrastructure pain for your organization”. There, there is some truth to that, and we are glad to use it and ease elasticity and high availability. But Kubernetes is not to be used for stateful data. If you make a step 3 years back from now, we can see the huge improvement in this area. However, it’s still an issue
… and you are not so far from getting data loss or corruption. Sometime, manual intervention is needed to … erase the state. So, do you have to use Kubernetes for stateful application? The question can be answer with “risk vs impact”. That clearly depends on the application you want to run on top of Kubernetes. Just ensure all stateful data are replicated in case of failure.
Running stateful application on Kubernetes is not only about your app. This is a question of the entire cluster workload and its management (cluster upgrade and security is much harder) or specific stateful workload isolation.
Takeway - stay tuned
We have some stuff in the pipe to have an even better solution:
- Replace our PVC by Ceph – Rook
- Get smaller content images for NGINX and PHP-FPM
- Review the way we manage the static content and implement a light CDN.
- This will impact the usage of NGINX at the end.
I would like to warmly thanks Mickaël Di-Monte and Mathieu Mallet for their help!