
The Michelin Guide: an unexpected event driven use case

{kind=link}

tl;dr content publication is a challenge for an institution like the Michelin guide. Event streaming between SaaS solutions using Kafka hosted in Confluent cloud was a solution for us to move from a 2 days delay publication to near real time. Although it was not easy especially from an observability & troubleshooting standpoint the investment was definitely worth it.
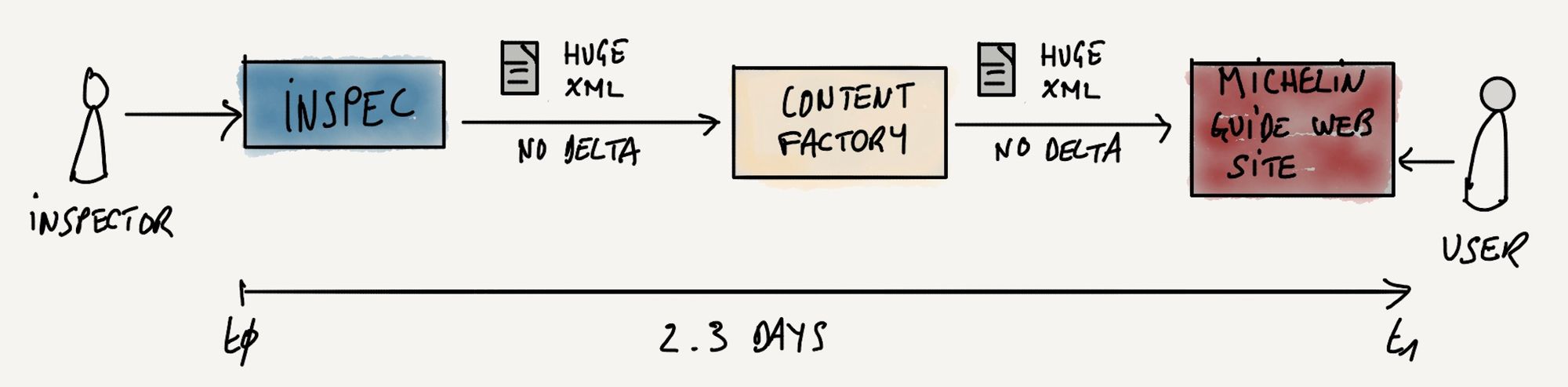
The Michelin guide also called the Red guide has been around for more than 120 years and recognized across the globe as a trusted source to find good restaurants. As a matter of fact the guide is as known as our tires if not more. And its user base is quite different from our traditional one: food lovers that may not have a car. Since the beginning, the guide was published as a book so all the IT systems we used were designed for a paper publication. Taking two days to propagate changes, whether it's a new restaurant added to the guide or a new distinction (the famous Michelin stars), was acceptable back in the day.
Then the digitization of the world began and it was difficult to handle. We introduced a while back a web site to complement the book. It is fair to say our 2 days pipelines did not fit well in this picture. The introduction of mobile apps made the problem even bigger.
So we decided to revisit our pipelines to make them real time compatible. Our first decision was to move from a Content Management System (CMS) optimized for print to a more digital one. We picked SiteCore Content Hub as it proposes a pretty neat digital experience for end users, ie the teams that manage the content of the guide. It clearly helped them in their day to day activities such as adding a picture for restaurant or translating the description into one of the 17 languages offered by the guide.
Beyond the fancy UI, Content Hub also has outbound notifications and APIs that make it quite relevant for what we wanted to do. We setup in Content Hub outbound notifications to call an API exposed by our Google Apigee api manager.
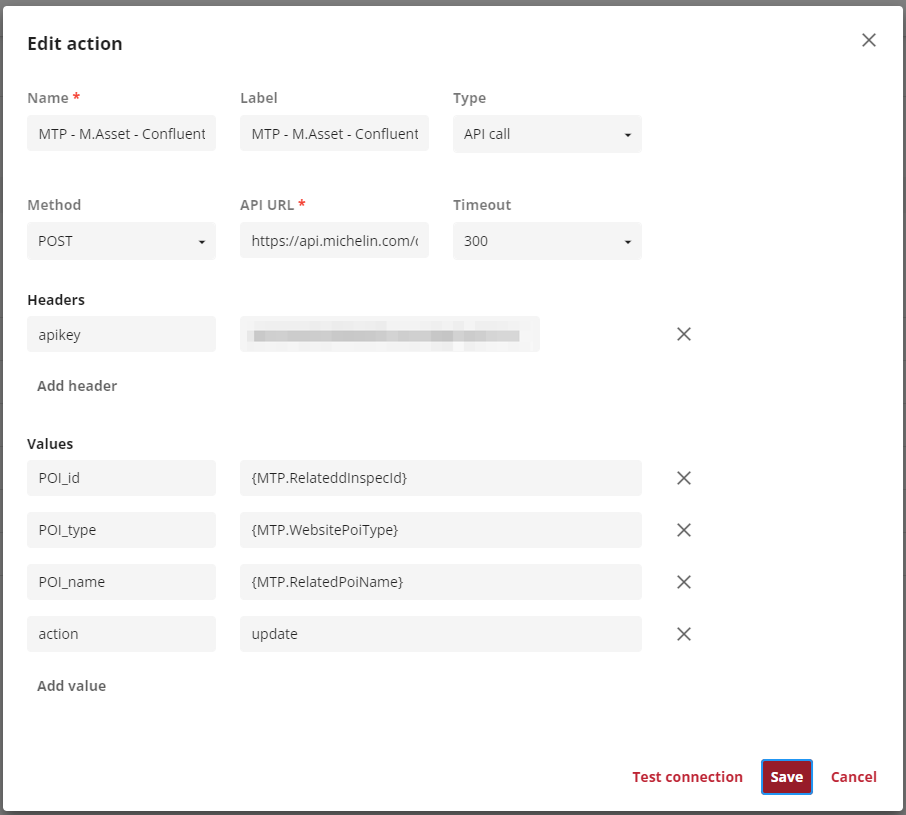
This API is in fact a gateway to a Dell Boomi flow that takes the input payload (ie a change done in ContentHub) and pushes it into a Kafka topic. Dell Boomi does have a connector that makes it easy.
The second choice we had to make was to get the data out of the system used by the Michelin guide inspectors. Inspectors are like test drivers for food. They go eat in restaurants anonymously and evaluate what they see and taste. We provide them a tool based on the Salesforce platform to keep track of their visit and support the collective process to give distinctions or remove them. How to push out these data in real time? There are couples of alternatives in Salesforce to do this.
You can develop a trigger logic in Apex so when a data is changed you can call an external API. There are some natives limitations in Salesforce though especially the number of triggers that can run in parallel in the background. We could think that this limit is high but it's not as described here. One of them is critical for us: the maximum number of Apex classes scheduled concurrently. 100 is not much as in our case, during the Michelin Stars Revelation events we massively update our data for the new millesime.
Salesforce proposes two others methods that helps dealing with this limit: Change Data Capture & Platform events. The first allows you to push changes on standard objects (like the Account) outside while the second do the same but support custom objects. In our case, the CDC approach was suited because we only wanted to push changes on standard objects.
Salesforce CDC groups changes on entities into a json payload. The format is quite simple but suffer from some design flaws. For instance, it contains all attributes including null values which forces you to identify the real changes.
{
"Id": "0010Q00001VmpEsQAJ",
"ReplayId": "23474350",
"ChangeEventHeader": {
"entityName": "Account",
"recordIds": [
"0010Q00001VmpEsQAJ"
],
"changeType": "CREATE",
"changedFields": [],
"changeOrigin": "com/salesforce/api/rest/53.0",
"transactionKey": "00014cf3-2571-7f92-f7e9-d650d3b1ba1a",
"sequenceNumber": 1,
"commitTimestamp": 1650860860000,
"commitUser": "0050Q000005mnMOQAY",
"commitNumber": 622822413154
},
"Name": "API Mapping Change Test Dev",
"LastName": null,
"FirstName": null,
"Salutation": null,
"MiddleName": null,
...
We decided to consume those change events from a managed Kafka connect Connector designed for Salesforce CDC. This connector pools the CDC API and extracts the change events payload to push them into kafka topics. Here we're talking only about configuration not development.
{
"name": "GKC-SalesForce_Cdc_Account_Change",
"config": {
"connector.class": "SalesforceCdcSource",
"name": "GKC-SalesForce_Cdc_Account_Change",
"kafka.topic": "gkc.accounts_changes",
"salesforce.instance": "https://ourinstance.salesforce.com/",
"salesforce.username": "theuser@weareusing.com",
"salesforce.cdc.name": "AccountChangeEvent",
"salesforce.initial.start": "all",
"output.data.format": "JSON",
"convert.changed.fields": "true",
"tasks.max": "1"
}
Let's step back a second here. We have a flow of changes coming from the system used by our inspectors. We also have a flow of changes from the system we use to manage the editorial content of the guide. These two flows getting in a Kafka topic. See where I am heading ;)
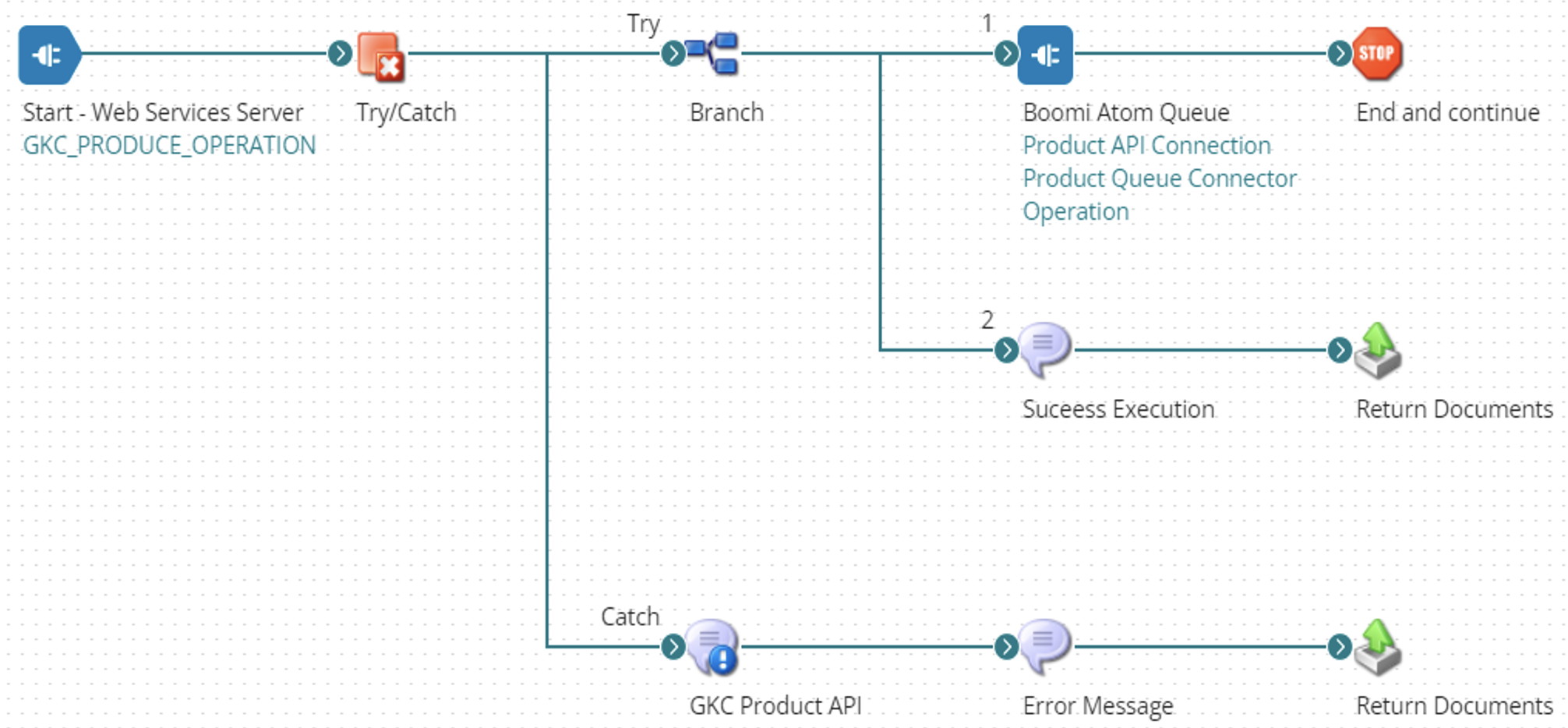
You have it: why not implementing a streaming app to combine these flows into a continuous stream of events that could be consumed by whoever needs it. For this we chose Kafka Streams and hosted this app into our Kubernetes cluster on Microsoft Azure. The final architecture looks like this:
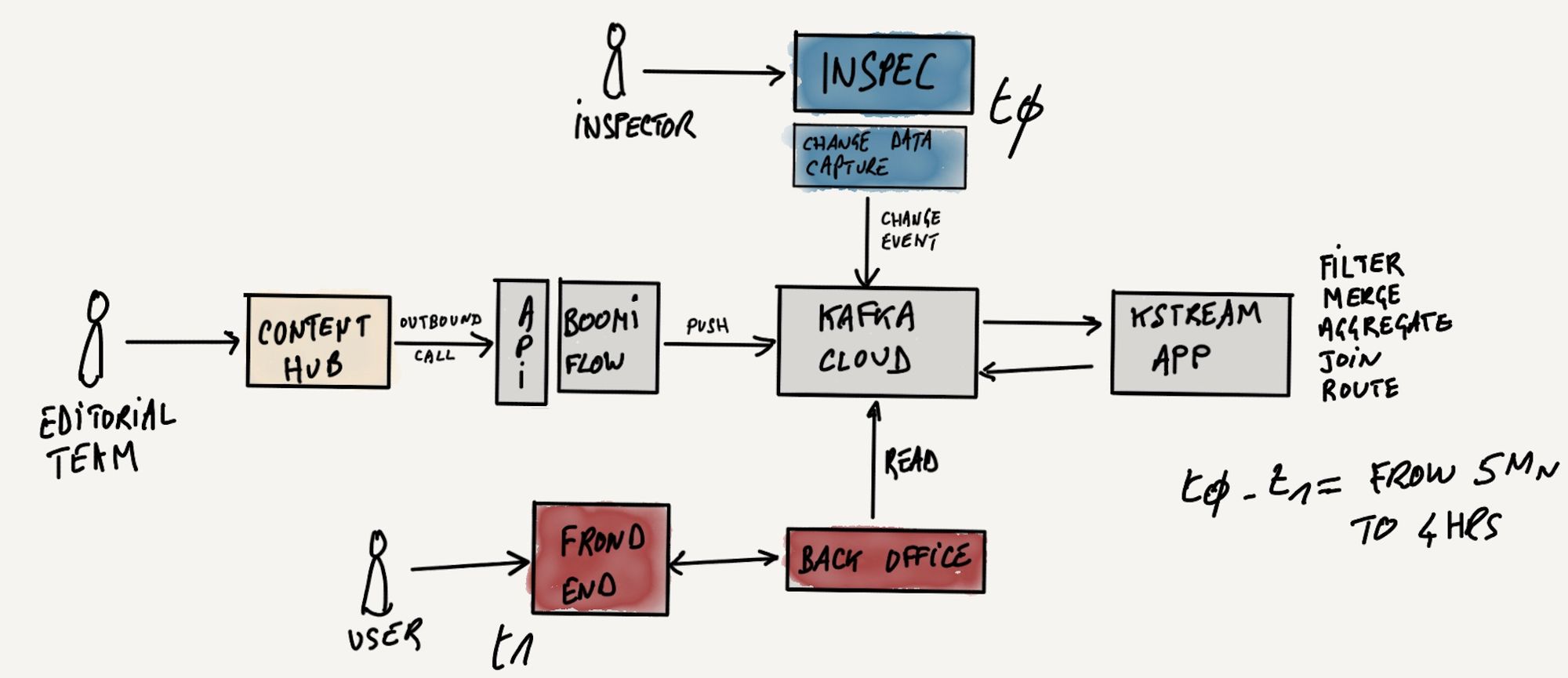
It's in the KStream app that we put all the logic we needed. For instance, we make sure that we do not propagate a restaurant that do not have images and translations. We also have constraints to support both real time changes and scheduled ones. For the Michelin Star Revelations event (called MSR internally), we have to hold the changes (who gets his first star for instance) until the press announcement is done.
Let's have a look at the code. First, we join ContentHub data pertaining to translations and pictures using the restaurant ID:
KTable<String, String> assetProductChanges =
assetChanges.leftJoin(productChanges, new AssetProductValueJoiner(), Materialized.<String, String, KeyValueStore<Bytes, byte[]>>as(STORE_ASSET_PRODUCT_JOINED)
.withKeySerde(Serdes.String()).withValueSerde(Serdes.String()));
Then we stream records from Salesforce connector and rekey them based on our ID. The rekeyed records are then filtered to discard update events that are not triggered by users to avoid duplicate merged records.
builder.stream(TOPIC_ACCOUNT_CHANGES, Consumed.with(Serdes.String(), Serdes.String()))
.flatMap(new AccountChangeEventKeyValueMapper()).filter(new ChangeEventPredicate())
.to(TOPIC_ACCOUNT_CHANGES_REKEYED, Produced.with(Serdes.String(), Serdes.String()));
KTable<String, String> accountChanges = builder
.stream(TOPIC_ACCOUNT_CHANGES_REKEYED, Consumed.with(Serdes.String(), Serdes.String()))
.groupByKey(Grouped.with(Serdes.String(), Serdes.String()))
.aggregate(() -> null, new RestaurantChangeEventAggregator(), Materialized.<String, String, KeyValueStore<Bytes, byte[]>>as(STORE_RESTAURANT_STATE_AGGREGATE)
.withKeySerde(Serdes.String()).withValueSerde(Serdes.String()))
.toStream(new AccountChangeSitecoreKeyValueMapper())
.toTable(Materialized.<String, String, KeyValueStore<Bytes, byte[]>>as(RESTAURANT_STATE_STORE)
.withKeySerde(Serdes.String()).withValueSerde(Serdes.String()));
We then force a left join to make sure we have at least one picture and the correct translation for each restaurant. This part is critical but can generate some confusion for non tech people. Why is my restaurant not being published? Because not all the required properties are available. We also filter inactive restaurants.
KTable<String, Restaurant> salesforceSitecoreMerged = accountChanges.leftJoin(assetProductChanges, new SalesforceSitecoreValueJoiner(),
Materialized.<String, Restaurant, KeyValueStore<Bytes, byte[]>>as(STORE_RESTAURANT_ASSET_JOINED)
.withKeySerde(Serdes.String()).withValueSerde(restaurantSerde));
salesforceSitecoreMerged.toStream().to(TOPIC_RESTAURANTS, Produced.with(Serdes.String(), restaurantSerde));
/* Streaming merged restaurant data and filtering out only active restaurant records */
KStream<String, Restaurant> activeRestaurants = builder
.stream(TOPIC_RESTAURANTS, Consumed.with(Serdes.String(), restaurantSerde))
.filter((poiId, restaurant) -> {
if (restaurant == null)
return false;
return restaurant.getStatus().toString().equalsIgnoreCase("active");
});
Finally, we route messages to different environments. We do have a testing environment (called interim) used to make sure what we display is correct for instance. All events are propagated first to this environment. Once they are ready, we push to our production environment. For the MSR event, we do have a specific topic we push to and release on the d day.
activeRestaurants.filter((poiId, restaurant) -> (restaurant.getToDisplayNextMillesime() || restaurant.getMSRUnderway()))
.to(TOPIC_RESTAURANT_INTERIM, Produced.with(Serdes.String(), restaurantSerde));
Map<String, KStream<String, Restaurant>> branchesToPublish = activeRestaurants
.split(Named.as(PUBLICATION_PREFIX))
.branch((poiId, restaurant) -> (!restaurant.getMSRUnderway() && restaurant.getToDisplayOnProduction()), Branched.as(IMMEDIATE_RELEASE))
.branch((poiId, restaurant) -> restaurant.getMSRUnderway(), Branched.as(MSR)).noDefaultBranch();
/* Routing messages for MSR to the MSR topic */
branchesToPublish.get(PUBLICATION_PREFIX + MSR).to(TOPIC_RESTAURANT_MSR,
Produced.with(Serdes.String(), restaurantSerde));
/* Routing messages to the immediate_release topic */
branchesToPublish.get(PUBLICATION_PREFIX + IMMEDIATE_RELEASE).to(TOPIC_RESTAURANT_IMMEDIATE_RELEASE,
Produced.with(Serdes.String(), restaurantSerde));
Now we can plug our front end apps (web site or mobile) on these topics. We decide here how we want to consume them. We always have a listener on the immediate release topic and we switch to the MSR one to massively update our front ends on the d day.
Well, it works
If we look back on the last 10 months after we deployed this pipeline, it's a success. Not only changes are propagated very quickly for day to day updates but the operations are way more sustainable for the teams. Because it took up to 2-3 days with the previous pipeline, we were limited in the number of MSR events we could do per year. Basically 25 / year.
Now with the new pipeline, we'll end up with 42 MSR in 2022 helping the Michelin Guide to be more visible as MSR generates lots of visibility on social networks. It was made possible because a MSR is now couple of hours with the new pipeline. This solution basically doubled the number of MSR events we could handle in a year.
From Theory to Reality
It seems easy right? That is the power of story telling. It was not, believe me! We faced numerous issues that I am going to share with you.
The first problem we ran into was the initial data bulk load: it generated contentions not in the Kafka ecosystem designed to handle massive number of events but in the CMS ContentHub. We do manage 16k restaurants with many translations and pictures (more than 200k). Even if we loaded these data into smaller batches, it generates massive number of outbound notifications from ContentHub ending up in some cases in deadlocks. We had to clean the environments and reduce batch sizes. Since this initial stage, we haven't faced that problem again as the number of daily changes has been way below this limit.
The second one was trickier. Configuring change data capture in Salesforce or the Kafka connector was not hard as shown above. Monitoring this flow and fixing it when it broke was. The user account we used to connect Salesforce CDC API expired and we did not notice it. Yes I know, booooo! The Kafka connector failed and started to log error payloads. Because we are hosted on Confluent Cloud enabling alerting was not possible and we did not have the Kafka connect error payloads available in our Splunk platform yet. When we discovered updates were not propagated anymore on the web site (like anyone), we saw that the connector was failing. I won't tell how long it took to you, I am not proud of it ;)
The initial error we got was explicit: user unauthorized. Once we spotted it, we fixed it by changing the password. The system resumed but did not exhibit the expected behavior. While we were fixing the problem, the changes in Salesforce did not stop. So they accumulated in the Salesforce internal Kafka. When the connector resumed, it was trying to read from the last committed offset but the pooled payload exceeded the maximum buffer size authorized by the connector. The connector was failing to read it but Salesforce considered it consumed and counted them into the daily limit of outbound events. The Kafka ecosystem is known for its resilience and connectors are built to keep trying. It generated a snowball effect in our case. Each time (ie every 30s by default) the connector was trying to consume the 24k change events adding 24k to the 550k daily limit. It did not take long before we reached this limit: 11 minutes in fact. Once you reach this daily limit and even if Salesforce is quite flexible on it, at some point we had a different error: number of platform events per day reached! please try tomorrow.
And the connector did try the next day and reached the same limit in the same 11 mn making the next day useless too. And the story went on until we found the solution. Our connector complies to the CometD protocol: it consumes the change payloads and aggregate them into a single payload. This payload size is limited by the max buffer size parameter. So increasing the buffer size fixed the problem but it took us some time to understand that the daily event limit was reached because of this behavior.
EMP Connector buffers the batch of events received using the CometD library. The buffer size is set in BayeuxParameters.java, in maxBufferSize(). Ensure that the buffer size is large enough to hold all event messages in the batch. The buffer size needed depends on the publishing rate and the event message size. At a minimum, set the buffer size to 10 MB, and adjust it higher if needed.
We also decided to reduce the delay between 2 retries in the connector configuration just in case ;)
Last but not least, the biggest challenge was to observe this end to end pipeline and give confidence to the Michelin guide team on its data quality. As you understood, before being able to display anything on the public web site or on the app, the data is coming from 2 main source systems (Salesforce and ContentHub) and goes into a set of topics using a set of Kstream apps. At the end, we want to be able to tell people: "ok, for the French Michelin Star Revelation, we have 4000 restaurants, 300 changed distinctions, 40 were removed from the selection and 20 added". And these numbers must be consistent across all systems including our topics which is a bit awkward if you ask me (a topic is not a table after all). For this, we pushed everything into a snowflake warehouse including the events we streamed in our topics. We aggregated all of that into a PowerBI dashboard to provide a synthetic view for our end users.

What's next
The previous pipeline was so manual and taking so long that the data problems were fixed during the two days process. Now, when a mistake is made in the source systems (Salesforce or Content Hub), the change is visible very quickly on the fronts. We'll have to enforce some quality rules in those upstream systems.
We already know as well that some of the data attached to restaurants are difficult to track like the opening hours for instance. Our systems should not be the source of truth for these kind of properties. So we need to add in this pipeline external data sources to increase our data quality and ultimately the user experience. This change is happening as we speak and I will show in a future post how being hosted in the cloud over Internet makes thing easier.
Last but not least, a huge change is also planned that will somewhat revolutionize the Michelin guide. For the last 100 years, the guide has been a closed selection. This to ensure only "good" restaurants makes it to the selection. It also has a major drawback at the same time: the impossibility for the guide to create a connection with its users as we do not let them provide comments or identify new restaurants. This will change in the coming months and we'll see how this pipeline will accomodate it.
I hope you enjoyed this article. Congratulations to the team who made it happen: @Jacobo Iglesia-Fernandez, @Melanie Lelaure, @Stephane Tantot, @Marjan, @Adwait Shinganwade, @Utkarsh Srivastava and @Marie Pairaud