
How to become a Data Driven Company in 10 simple steps

When your core business is selling tyre
1. Build A Data Custodian Network and a Data Catalogue 🕸️
The first step in becoming Data Driven is to identify the experts in the data within your company. Those would generally be people within your IT organisation that have a good understanding of the data but also of the system that stores it and the way it flows within the different systems. They also have a good understanding of the specificity of the business generating or using this data and can connect the dot with the owners of the data.
You should identify the different functional areas or domains that drive your organization. At that point creating an enterprise model can make sense but you need to be careful that different concept names can have a different significance in different contexts.
Those people in their respective functional areas form your Data Custodian Network. Note that this will be a new responsibility added to people with a very busy schedule, and you might want to get their manager aligned. It's a good idea at this point to appoint a person to manage this network and give him/her the role of Data Architect.
The first task for your network is to catalogue its data. Start with a simple tool for this task: Excel is an excellent choice. It's quite likely that you have one or multiple systems in your organization that already provide BI capabilities, this is where you should focus first when documenting your data instead of tirelessly trying to document all the system producing data.
Keep it simple when documenting your data and start with the physical model and its table, column description and key sources of lineage.
2. Build using PaaS capabilities 🛠️
You need to go fast and get your first use case rapidly, from data ingestion to its visualization. This speed will come by leveraging a Platform as a Service (PaaS) offering from a cloud provider. It's likely that your company has already picked one cloud provider which may be Microsoft Azure, Amazon AWS or Google GCP. Go with the existing cloud provider even if it may not be your favorite choice and pick the data combo offered by that provider.
A typical data pipeline will have to orchestrate, process, store and visualize data. And the typical data combo will look different based on your cloud provider.
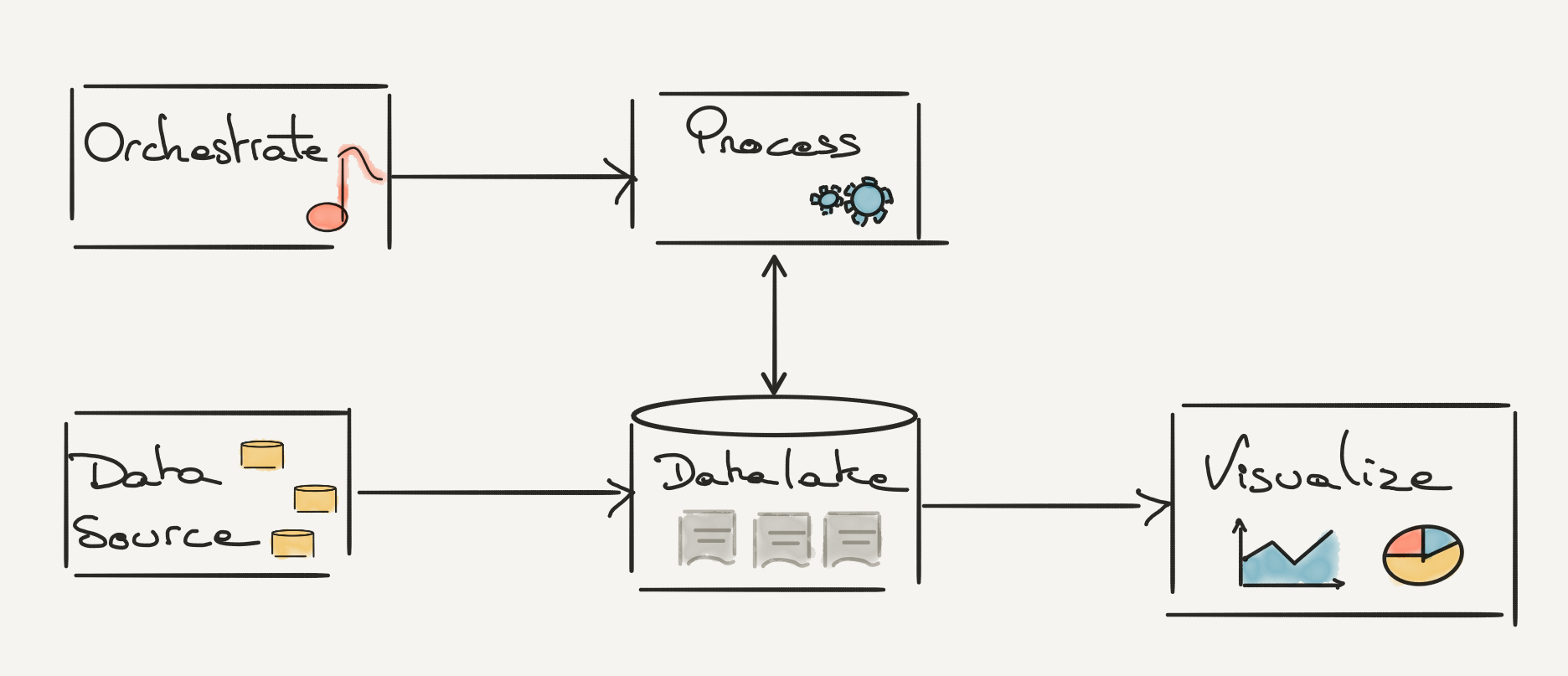
| Microsoft Azure | AWS | Google GCP | |
|---|---|---|---|
| Orchestrate | Data Factory | AWS Glue | Cloud Composer |
| Store | Azure Data Lake Store | Amazon S3 / Amazon Redshift | Cloud Storage |
| Process | Databricks / Synapse | Databricks / Elastic MapReduce | BigQuery / Dataproc |
| Visualise | Power Bi | Amazon QuickSight | Looker Studio |
You might have some constraints that prevent you from accessing a cloud infrastructure such as security, privacy or data locality. In this situation you will need to build your own internal PaaS capabilities that would rely on some foundation that provides distributed storage and distributed computing through Kubernetes.
The On-Premise combo could look like:
| On Premise | |
|---|---|
| Orchestrate | Dagster / Airflow |
| Store | S3 Object Store |
| Process | Spark / ReDash |
| Visualise | Apache Superset / Streamlit |
3. Set up a Team and Organization 🍕
You need people! Start with a small team that have cross skill competency: a good cloud understanding and some data engineering knowledge.
The team will look like:
• 3 or 4 very technical people with broad skills rather than deep skills and those people should be more oriented devops than your typical data engineer
• A product owner that will steer the vision and great ability to communicate
• An architect which share the vision but can also be hands on
Having an architect early on is important. During the construction of the platform it's quite likely that you will have to take some shortcuts and do things not in the way usually done in the company. The architect will be able to protect the team and its decision from your detractors (and you will get some) while ensuring things are still coherent and secure.
In those early days you will need to get transparent with top management with what you are building and get their backing. Depending on your organization and its size you might even look for your CTO support and may have to present your vision very clearly in an elevator speech style (jump in the next step to hear more).
You have your small team and should start getting your first use case to run on the architecture you have picked. This use case should not be too critical as it may take more time than anticipated and as you learn you will have to test and try different patterns. What is important is the 'wow' effect, so make sure you invest significantly in the visualization of your result. In this use case you need to make sure you use all the important parts of a typical BI product: load data, transform it, expose it and visualize it.
4. Market your product 📣
You need people! Start with a small team that has cross skills competency: a good cloud understanding and some data engineering knowledge.
You have your initial team, and you have your first project running and probably already delivering some value. Now it's time to advertise your vision of the platform.
You have to invest in creating presentation support for your data platform. When I say invest, I mean it, you will probably spend hours and hours creating your material but it will be worth it since you will be running your presentation between 10 to 100 times.
What do you talk about? Many things, here are some subject you might want to touch on:
• Always start with an executive summary, if you had only one slide what would you say?
• Describe the problems you are solving
• Introduce the context and how does your solution fit with the existing ecosystem
• Walk over the architecture
• Explain the shift you are making with existing solution
• Suggest an organization supporting the solution
• Create a metaphor where you compare the platform to known concept
You should also keep in mind what you want from your audience, which might be support, to move projects to your solution, to be reassured or to become promoter…
It's quite likely that there are already a lot of existing BI and Analytics solutions. It is time to convince people your new data-lake-thing is a good idea and to start investing in your new solution.
Go and present to all parts of your organization: management, upper management, technical team, business, infrastructure, security, project team.
5. Create A Platform 🌇
You are about to create a platform that will become the foundation of the Data Driven initiative for your organization. It's time to think big.
Architecture
Your architecture needs to support the platform approach. As you will be co-hosting many products you need to provide some strong isolation guarantee:
• Only one product can write in a given directory of your data lake
• Provide process isolation where each product as its own isolated compute
• Provide data pipeline isolation where a given product cannot impact directly another one
Take time to document your different patterns for data ingestion, processing, and exposition so the different teams building on the platform get a clear understanding of the architecture they should adopt.
Onboarding
You have your first use case up and running and with all your marketing effort you should see a new use case knocking at your door.
Deal with those first few new use cases like if you start seeing hundreds of them because this might be what you will be facing in a few years from now. In those early days it's important that you capture in a centralized way the requirement and solution of each new product you are onboarding. Make this phase as lightweight as possible: onboarding a new project should not take more than 30mn to 1hr.
Some of the minimal things you want to capture for each new product include:
• What is it doing, what is the value proposition?
• Who are the technical and business contacts?
• How is it done? what is the architecture, what are the integration points, how is the data surfaced?
We call this the Work Initiation Document (WID) and we capture them in Markdown which is source controlled with a website created automatically using static site generators.
Organization
The team you have set up for your initial project in the 3rd step should now become your platform team and should only focus on building the platform, not other actual data products. When you scale from 1 to 10 to 100 projects running in your platform you need to make sure you don't have to scale this core team accordingly and if you do it should only be a factor of 2 or 3.
We call the team working on building products within the platform a feature team or a Stream-aligned team if we follow the Team Topology principle. They are responsible for all the steps in building their product autonomously from data ingestion, transformation and its restitution through BI report for example. It’s the Platform Team responsibility to make sure Stream-aligned teams are autonomous which include supporting or deploying new versions of their product. You have the opportunity to adopt the "You build it, you run it" approach that was proposed by Amazon back in 2006.
6. Automate ⚙️
When we set up the initial team in the 3rd step, we insisted on having people with devops skills. This is important as you will need to automate as much as possible when onboarding new data products.
When you onboarded your third project it was ok to create the empty shell (a pipeline, the right folder structure, and its right management...) all manually.
This won't work however when you are at your thirties product if it takes a week for a person to create all the required components and link them together, especially when 2 or 3 new products come knocking at your doors every week.
All of the cloud platforms provide API to support automation and with tools like Terraform you should be able to rapidly provision all new resources you need, so it takes only a few hours for a Data Product to be created in your platform.
It's key to reduce as much as possible the different interactions or validations needed when onboarding a new Data Product. You shouldn't need an architect approval, a stamp for security or to acquire additional budget. You may however keep your Data Custodian in the loop.
You will also need to build some self-service capabilities. It's not good if every time a new member gets added in a team to open a ticket to your Platform Team. All the interactions with your platform should be done through API or via a specific portal.
7. Deal with Security, Infrastructure and Data Privacy 🕵️
You are building the next generation' data platform, you are not looking at storing newspaper articles but data relevant for your company. In the tons of information you will be storing there will be some sensitive information. This can be financial information with some non-public information which can lead to insider trading if misused. This might also be some personal information that may fall under the GDPR legislation which can lead to heavy fines if not handled properly.
Your platform on those topics needs to be bulletproof and to have all the required security built in to handle sensitive and personal data. You may think of a zero trust approach here: you accept that your users are human and may make mistakes.
You need to work with your Security, Infrastructure and Data Privacy department to understand their needs and propose technical solutions to answer them using their vocabulary.
We sometimes see those external departments as generating constraints outside our control and negatively impacting our ambition. We shouldn't. Instead, we need to work all together as one team on those important topics. You may sometimes need to go back and understand the why when facing impossible requirements. If your security is imposing retina based authentication they may simply be asking you to prove that a user is human, a constraint you can answer differently.
Some of the measures you may consider implementing:
• Segregate access to the most sensitive data
• Create a process for accessing this data and audit it
• Create reporting capability on data access
• Limit access right for platform administrator
• Limit human access to production using CI/CD
When creating those different processes, audit and report use your own data platform to build those and feel what it's like to be a consumer of your platform.
As you progress in your discussion and obtain some pattern validation from security for example, you need to trace those. Tracing decisions with a hand shake or an email is not enough, you need to build a system to trace those and we've seen the Architecture Decision Record to work well.
8. Reuse Existing Data Exchange 🪢
Unless you are a start-up and only have a few years of history you should have a variety of existing data exchanges across your different systems. You need to leverage them.
You may have an existing pattern for exchanging data through files across systems. You need to tap on it and provide a pattern where you can capture all this data which may look like a Y shape flow.
You probably also have some existing BI and Analytics systems that have been patiently built over the years and feeding some Data Warehouse. You also need to tap on it which might mean creating a regular data extraction. You should also consider using some Change Data Capture (CDC) tools to automatically read the database transaction logs from your source system to feed your data platform.
You may also discover that people in your company are sharing data using Excel files through some share drive. Accept it, and tap on it by providing a connector to those drives and provide a blueprint to capture all this data.
Let's be honest, feeding your data platform using files, data extract or change data capture doesn't feel very modern and even creates some dependency on the systems you were aiming to replace in the first step. Some people will hate you for taking such horrible shortcuts, later you may even hate yourself for doing this, but this is a necessity to go fast and provide value for your company.
All of this is an evolutionary architecture, you should already be working on your next move and build an event driven architecture.
9. Become Event Driven 🏎️
Traditional data platform has generally been based on some batch processing such as a long process running on a daily basis transforming your datastore into datamart.
We have to realize two things:
• The true nature of data is rarely batched but instead flow over time from your transactional system
• Batching is an irreversible operation, once the data has entered a batch it has lost forever its real time property.
Only a few data analytics use cases will ever have to be truly real time and the complexity of maintaining real time data through an entire data pipeline might not make it worth it. You should however allow the data to enter your platform in real time when it is presented to you in real time.
The path to become event driven can be done in a gradual way in two steps: to adopt a choreography approach before adopting real time patterns.
From Orchestration to Choreography
An example of orchestration in batch processing can be a task starting every day of the week at 7am, to ensure the 5am batch it depends on has completed, and producing reports so your users can access them first thing in the morning.
In the choreography approach we chain the different batches. We can for example listen for new files arriving in a file system and trigger the launch of a batch that would process it which will in turn trigger the refresh of all the dependent reports.
Real Time Data
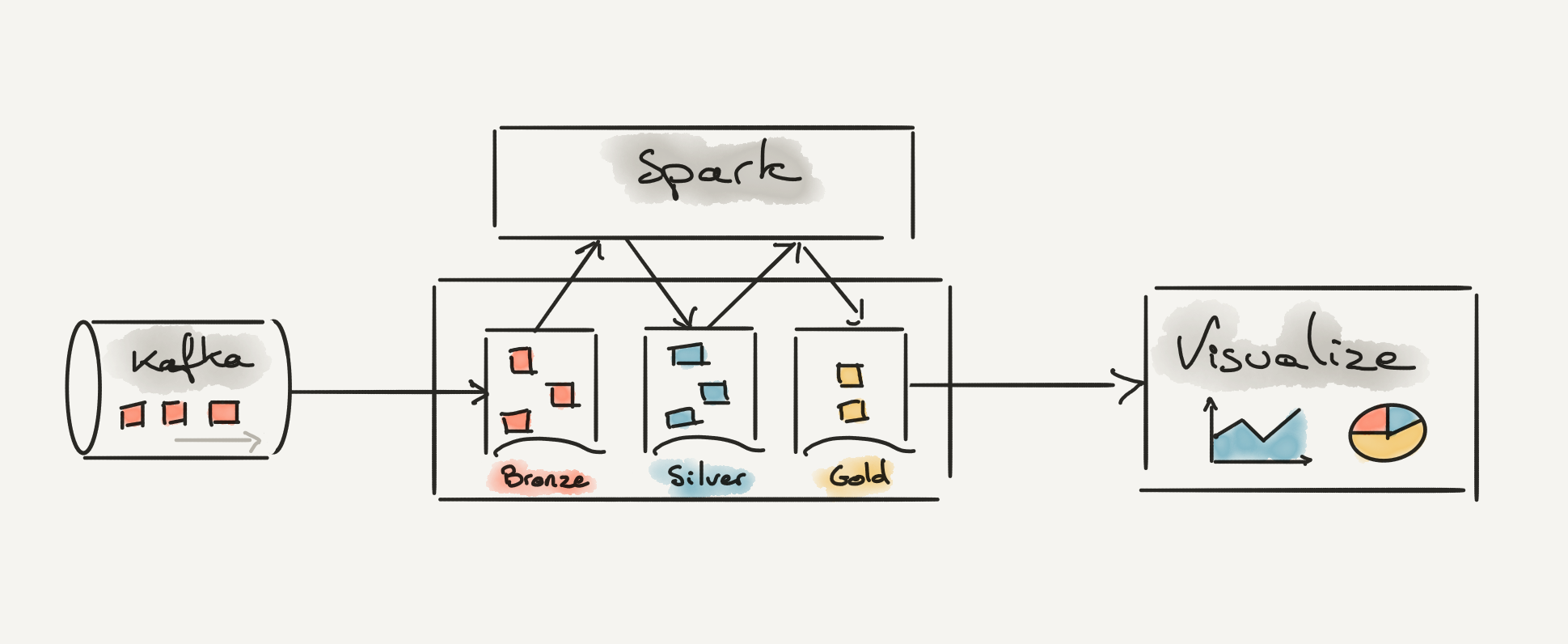
Modern architecture promotes decoupling our system and communication between them through API or asynchronous messaging. The event driven architecture offered by messaging technology such as Kafka is perfectly suited to update your data platform in real time.
It is common to use Spark within a data ecosystem and with Spark Stream you have everything you need to consume Kafka Topics in real time. Consuming events is one side of the problem, we also need to update our data lake in real time.
Some great innovation came to us in the last few years with new file formats like Delta, Iceberg and Hudi. Those new files have some unique features that allow to update a dataset incrementally without having to rewrite the entire file. Even better, those file formats such as Delta have some Change Data Capture built-in which means we can listen on the file for new updates and trigger further processing.
With the combination of Spark Stream, incremental file construction and built-in Change Data Capture we are able to recreate the traditional Bronze/Silver/Gold data refinement pattern we see traditionally but all in real time.
10. Build a community 🥇
We hope your data platform will become successful rapidly. You have a small team managing the core platform dealing with potentially hundred different products running within it. You probably don't have the capacity to double the size of this core team every time you double the number of products so, how can you deal with all those different products looking for help to troubleshoot their issue?
The answer is through the community you should build alongside your platform. You should seek for a virtuous cycle where more users using your platform generate more users to support each other.
To assist this community, use all the tools you have available:
• Dedicated group in your favorite company messaging app
• Regular Community of Practice meetup
• Communication through newsletters
• Collaborative knowledge base
More importantly: hire a community manager, a person that would be dedicated full time from animating and organizing this community.
Before we go 👋
This article is a summary of our journey at Michelin when building our Data Platform which is internally called the Corporate Data Lake. Our journey began five years ago, and since then, we have faced our fair share of difficult moments, as well as moments of joy and success to celebrate.
Would I have done things differently today? Probably, so stay tuned for the second part of this article covering the lessons learned. (coming soon :-))