
Migrate Applications from Kafka On-Premise to Confluent Cloud


Michelin introduced Kafka back in 2018 with some on-premises clusters.
In my previous article, I shared how Kafka helped Michelin to learn distributed architectures as well as the complexities and difficulties we faced when managing these Kafka clusters.
In this article I would like to explain how we migrated all our data, producers, consumers and Kafka stream applications from our on-premise cluster to Confluent cloud, a solution hosted in Microsfot Azure and managed by Confluent.
Why did we do this choice
If you have already managed a cluster Kafka, you already know that it is not a simple story. At Michelin, our strategy is to have a corporate Kafka cluster to manage most of our use cases. Most because we have some specifities being an industrial company. For instance, we implemented specific Kafka clusters in our plants and in our sensitive data center.
To manage a cluster, it requires:
- Several datacenters with a low latency and possibly with as "reliable" as possible network.
- We need to have skills as even if the Kafka platform is very stable and robust, when it has a severe issue, a high level of competency is required to do the right diagnostic.
- We deploy regularly new producers, consumer, streams … and we must carefully manage our capacity planning. The fear of the “File System Full” error.
And to be honest at Michelin, that's not where we excel. It mainly explains why we decided to leverage as much as possible managed services and Kafka is a perfect candidate. At the end, we were also looking for a better level of service and to reduce run cost significatly.
From several years, we are working with the support of Confluent to manage our central cluster. One of our cloud provider being Microsoft Azure, it was therefore natural to subscribe to Confluent Cloud Plateform in Azure.
The Challenge we face
As I mentioned earlier, we had several Kafka clusters and we decided to migrate the 2 following one:
- The Central Kafka cluster already licenses by Confluent
- The main Kafka cluster of the factory, not licenses by Confluent
To a single Kafka subscription Confluent cloud
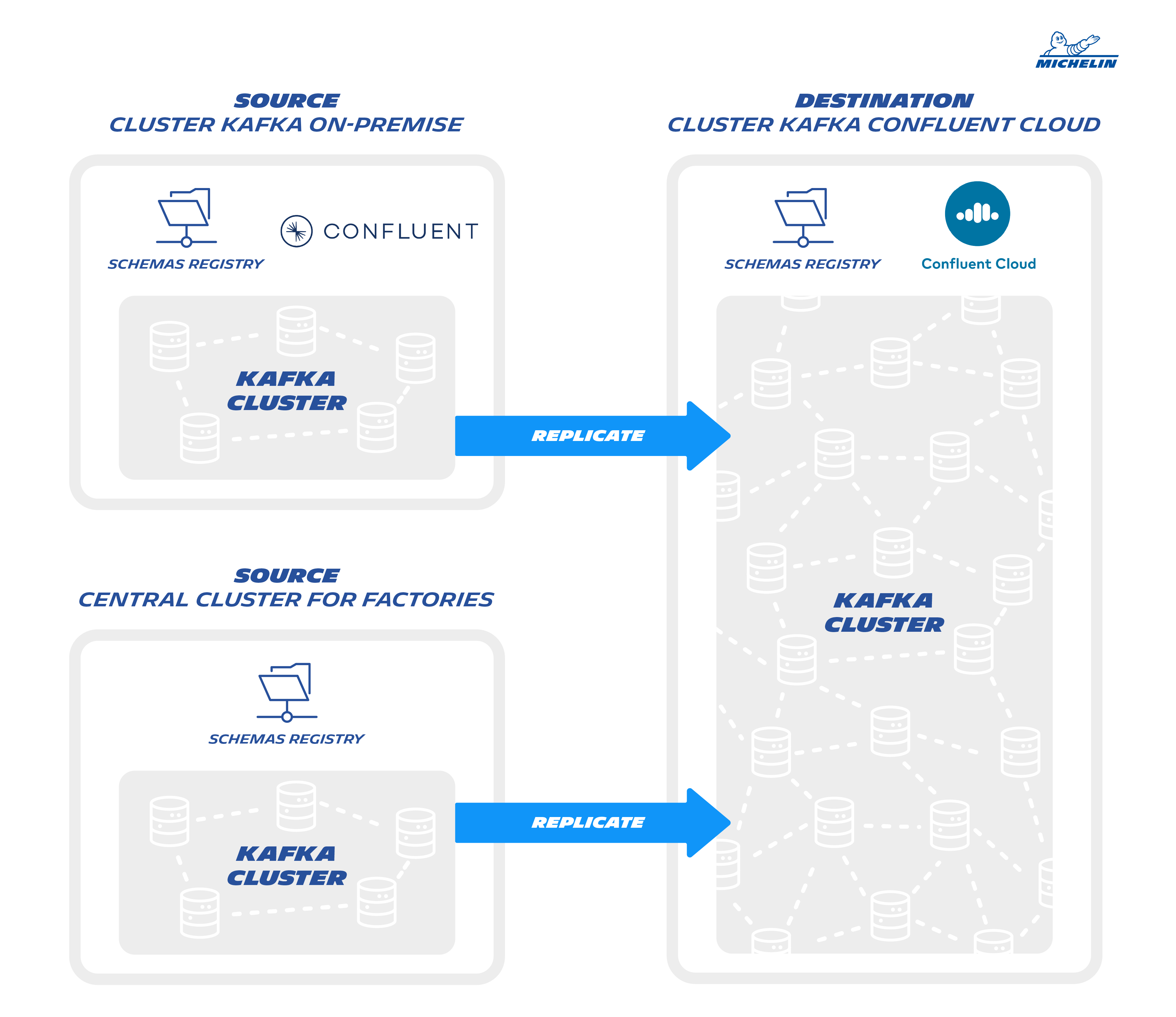
The existing configuration of the central cluster: (the biggest one)
- 5 zookeepers
- 15 brokers hosted on 3 datacenters (3 racks)
- More than 1500 topics and 5TB of data.
- More than 150 connectors
- More than 25 teams on 3 continents.
- One Xlarge Kafka stream product with 100+ Kafka stream micro services
Our requirements for this migration were high though quite common:
- No data loss, no data duplication
- Limited outage for the applications
- Coordinate 25 teams on several continents
- The case of the Xlarge Kafka stream product
First Step ... convince teams
Before starting anything, we had to explain and even convince more than twenty teams to make this migration. We felt that technically, there was little impact, for 70% of our products. The only impact on the code was to modify the properties of the cluster connection chain. We then first worked with the dev teams to identify and confirm the technical impacts.
The most complicated part, as expected, was to coordinate the 25 teams and to put in products' backlogs this technical migration with a high priority so the migration is as quick as possible.
But as in many companies, technicals evolutions are often challenged to the benefit of business evolutions which are considered to have a higher added value. After many discussions, we were finally ready to address the subject...
How to migrate our data?
We envisioned three technical ways to migrate our data from the source cluster to the target one, based on Connectors:
- Mirror Maker 2 (MM2)
- Migrate data Byte to Byte
- Doesn’t migrate the schemas (so the schemas versions should be the same between the source and the destination)

- Replicator
- Only to migrate data from cluster supported by Confluent source and target (only the case for data of the central cluster)
- Migrate Schemas
- Offset not preserved in the topic/partition (possibility to minimize the problem using ConsumerTimestampsInterceptor, consumer side)
- Cluster Linking
- In preview mode only (as of March 2021)
- Offset preserved
- Works only at the destination side (security constraint violated Michelin side)
For the data migration of our central cluster, supported by Confluent, we decided to use the connect replicator. But for other clusters, it was not possible. We were not authorized to use replicator, we should use the MM2 with his constraint on schemas.
So, we implement these two solutions for data migration depending on the context.
As we said above, Mirror Maker doesn’t manage schemas: the version of the schemas in the source cluster should be the same than in the target. The connector doesn’t manage the replication of the schemas during the migration of the data, when the data are replicated the version of schemas is not translated, like it is done with the connect replicator. How to deal with that!.
We can already imagine, in the future, we will need to replicate data between our several clusters and the only way to do that with Kafka cluster not under Confluent licenses is with MM2.
How to manage the migration of several schema registries into one single schema registry?!
The constraints we had:
- We have to migrate two schemas registries in one registry in the cloud and we have to keep the same version of schemas.
- We have to anticipate the fact, that in the future, we will have to replicate data from clusters under licenses and some not under licenses.
- The schema registry should be accessible from our cloud provider and from On-premises
- No RBAC in the Cloud schemas registry, the project which have access to schemas has access to all the schemas.
We need a centralize schemas registry to have one source of true for the version of our schemas.
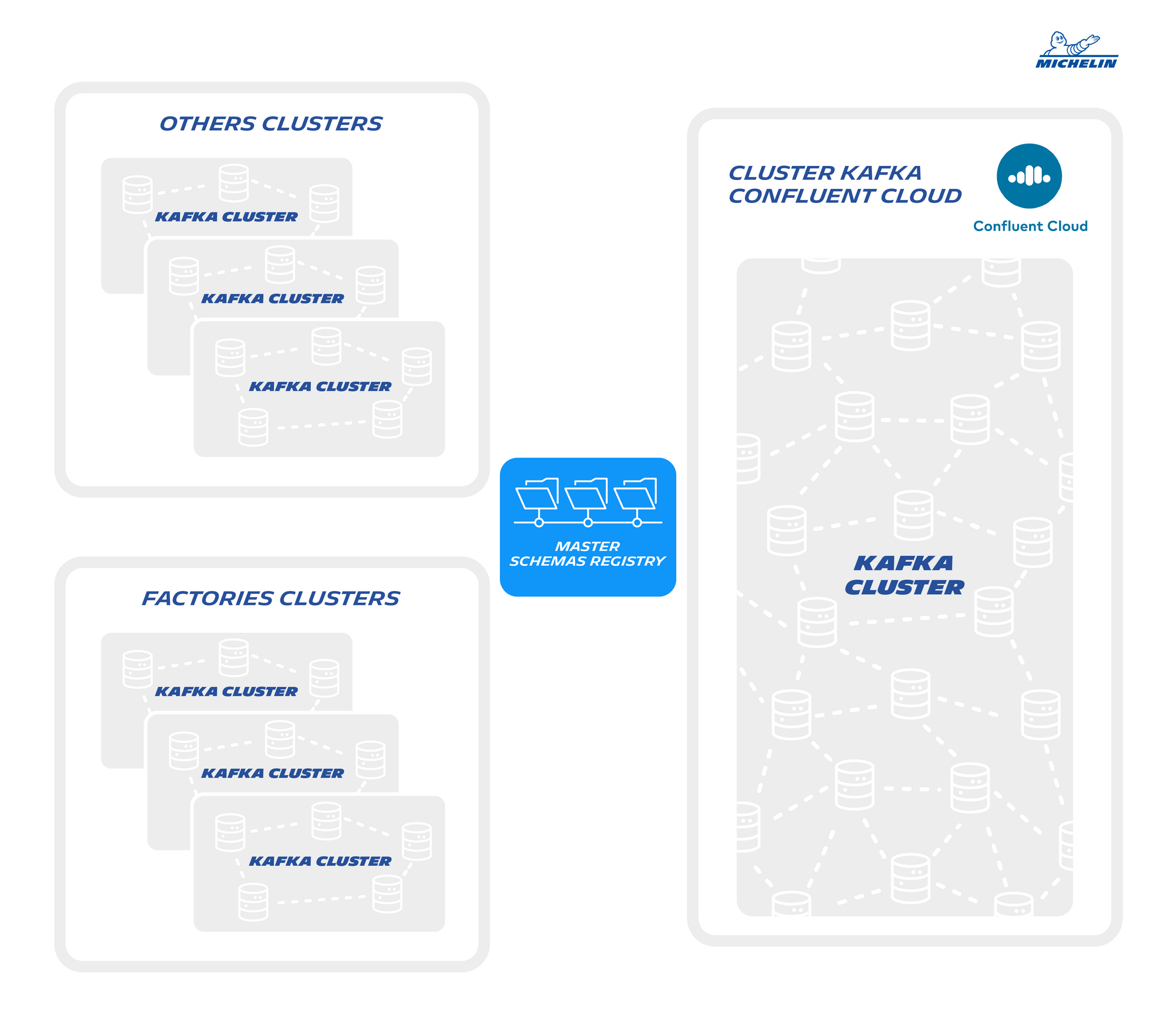
We imagined several scenarios:
- Should we make a master registry and have replica on each cluster? But how to guarantee the correct replication of the schemas?
- Can the Cloud registry be our master registry? But we are creating a strong coupling bridge, and we must guarantee the accessibility of this registry schemas on all our network points, (On-premises and Factories).
We choose the second option. The registry schema is not critical to produce a message. It's needed only when publishing messages and starting applications!
With this last decision we were ready to migrate
- One Schema registry
- Replication with replicator for existing cluster under licenses and with mirror Maker for the others
- And we will start the replications of all the schemas with existing cluster not under licenses.
The only constraint not yet managed is about the RBAC and the segregation of access to the schema registry.
Let me introduce few words of the component NS4KFK
Globally teams working with Kafka need to manage their resources themselves:
- Kafka topics
- Avro schemas
- Kafka Connectors
The teams should be autonomous, but Kafka doesn’t provide a way to isolate teams: when you have access to manage resources, you can manage all resources, not only yours.
Michelin has developed a deployment model for the different Kafka resources following the best practices of Kubernetes. Let’s follow the link it was really Key for us to deploy it, and our migration was the right opportunity to introduce it
https://github.com/michelin/ns4kafka

We profit of the migration to Confluent cloud to introduce the tool, I will not enter deeper in detail, let’s read the documentation, but it was mandatory for us to implement this tool to give autonomy to the projects, to secure our future deployment with Kafka., it was adopted by more than 20 projects for the migration!
From now, we know more or less how we will be able to migrate data from one cluster to another.
Next Step ...
In which order we have to migrate our products
During our analysis, we decided and tried to group the products by use cases:
- Producer/Consumer only: project which are only consumer or producer
- more Referential data in our context
- Business Processes: projects involved in end 2 end process flow several producers/consumers
- more Transactional data in our context
- Applications Kafka Streams
But some of projects are included in several groups, we have build a matrix and a table of constraints to define the order we have to respect to migrate.
We have authorized only the replication in one way (from old Cluster Kafka, to the new one), to avoid the spaghetti dish.
For the use cases: “producer/consumer”.
- The producers have to replicate first their data, to allow the migration of their consumers. The producer continues to publish in the existing cluster until the end of the migration of all the consumers to the new source of data.
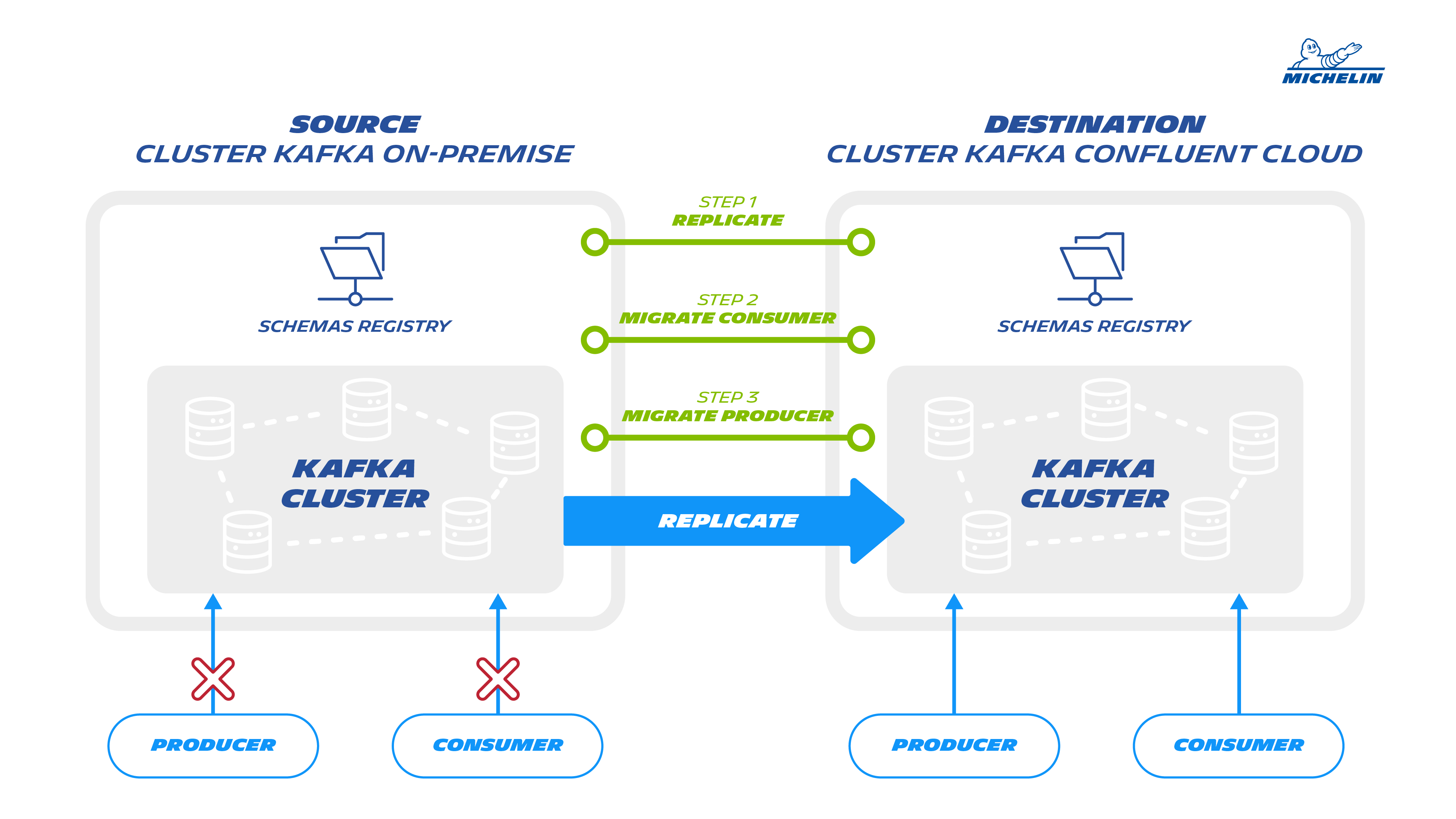
This model has been applied for referential data and transactional data.
For referential data, in our context, no matter to reload the data twice, so the synchronization between consumer and producer was “easy”.
For Transactional data, it introduces some coordination between consumer and producer, to stop the production of data, during the migration of the consumer.
From now, let me explain how we have migrated our most challenging use case....
Migrate a Xlarge application Kafka stream
As I mentioned earlier, the keys constraints of the migration was the downtime and the duplicate data.
For Producer/consumer use cases, no problem, it was manageable easily.
For a Xlarge project kafka Stream, it was more tricky.
- Topics (974)
- Connects (245)
- Streams (183)
One of the team's key challenges was to ensure that data was not duplicated.
This Kafka stream product is fed upstream by products which cannot guarantee us exactly Once, we have sequences which therefore run "normal" duplicates.
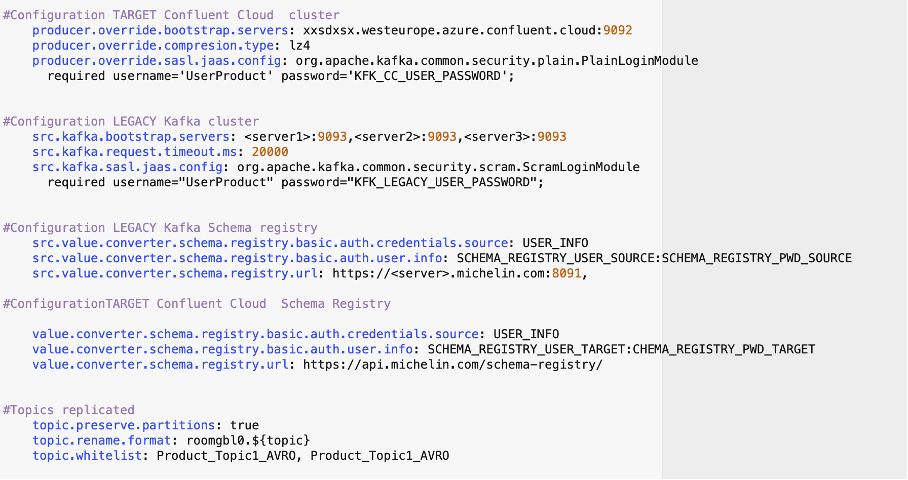
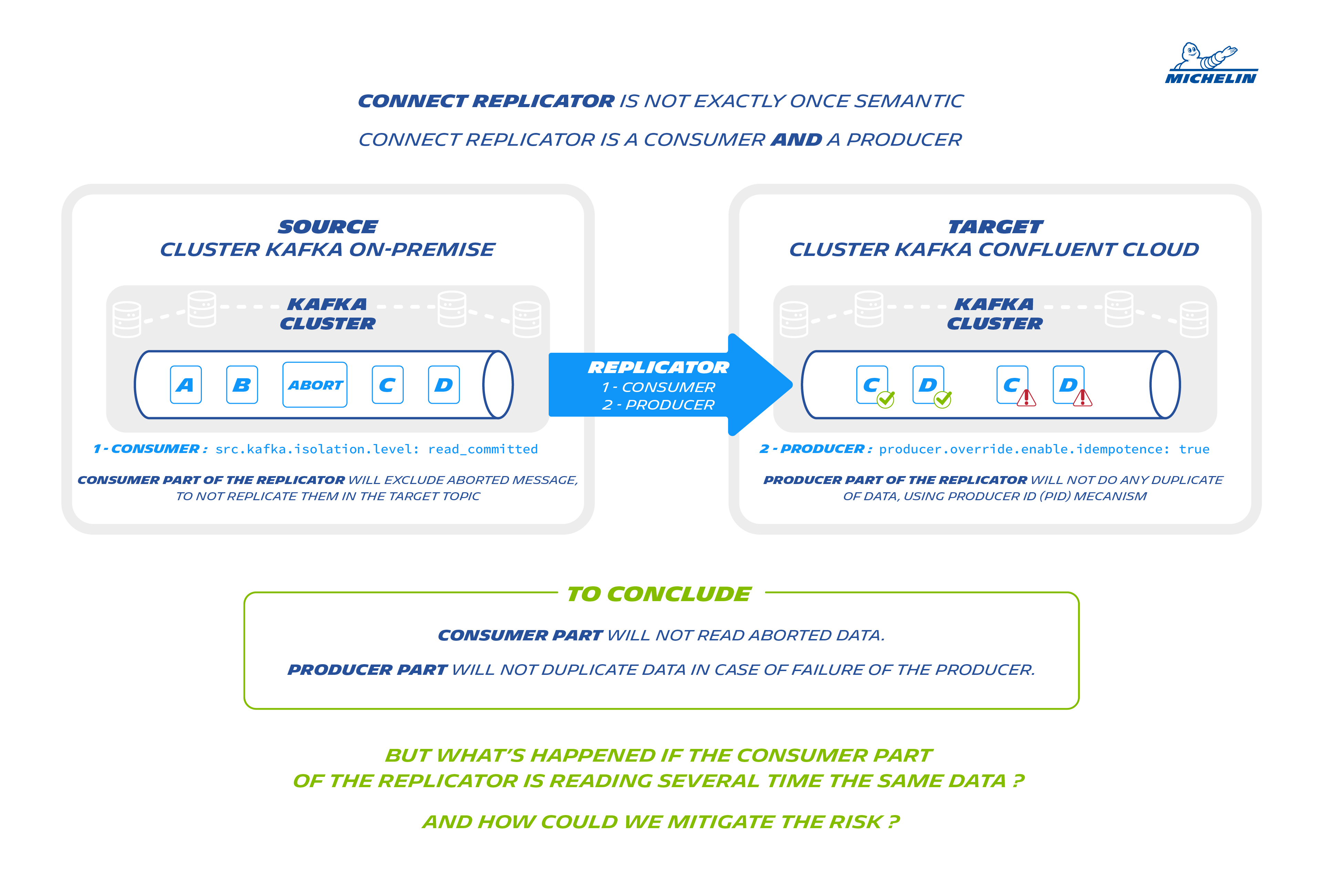
During data replication we should not generate duplicates, except with the connect replicator we have no transactional guarantee. Connect sources are not ExactlyOnceSemantic and replicator is a connect source. As described in the schema below, we have to setup the right properties.
Replicator connector is a Consumer and a producer:
1- Consumer part of the replicator will exclude aborted message, to not replicate them in the target topic:
src.kafka.isolation.level: read_committed
2- Producer part of the replicator, will not do any duplicate of data , using producer ID (PID) mecanism:
producer.override.enable.idempotence: true
But it's not enough
What's happened if the consumer part of the replicator is reading several time the same data ? and how could we mitigate the risk ?
To minimize the risk of technical duplicates during replication, it is necessary to ensure that there is no rebalance on the connect side.
Rebalance can occur due to network latency, and we have bad latency sometimes, the team has decided to reduce the size of the TCP buffers as much as possible during the replication, They have carefully monitored all cases of rebalance detected during the replications. in order to reduce to zero, the cases of technical duplication. (screenshot of our grafana dashboard).
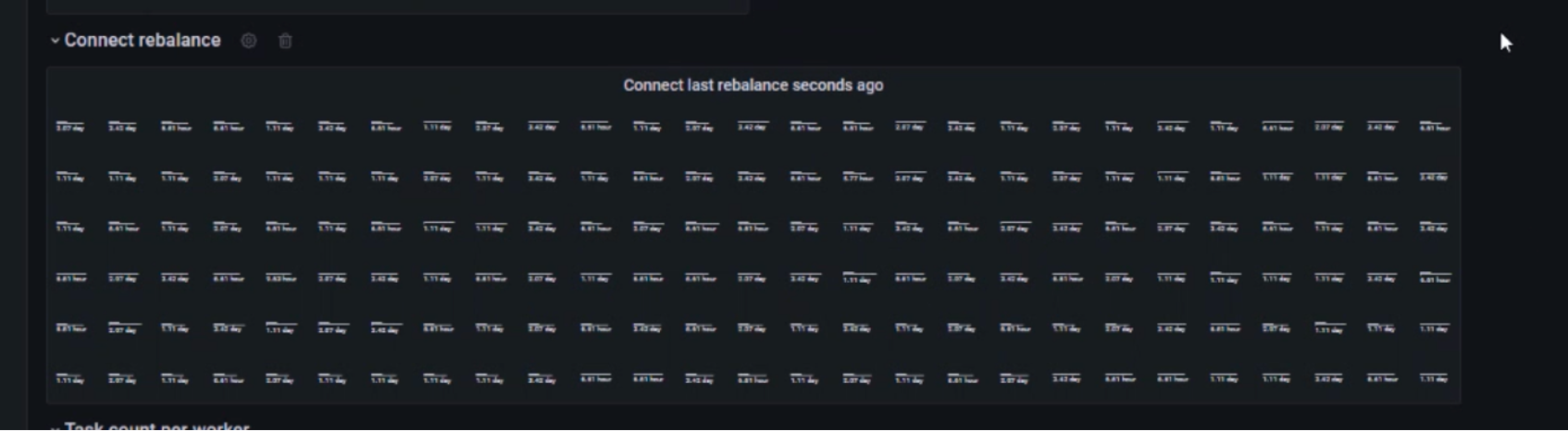
With this tunning and the monitoring , the team have guaranteed integrity of the data.
The strategy to migrate the application is described below:
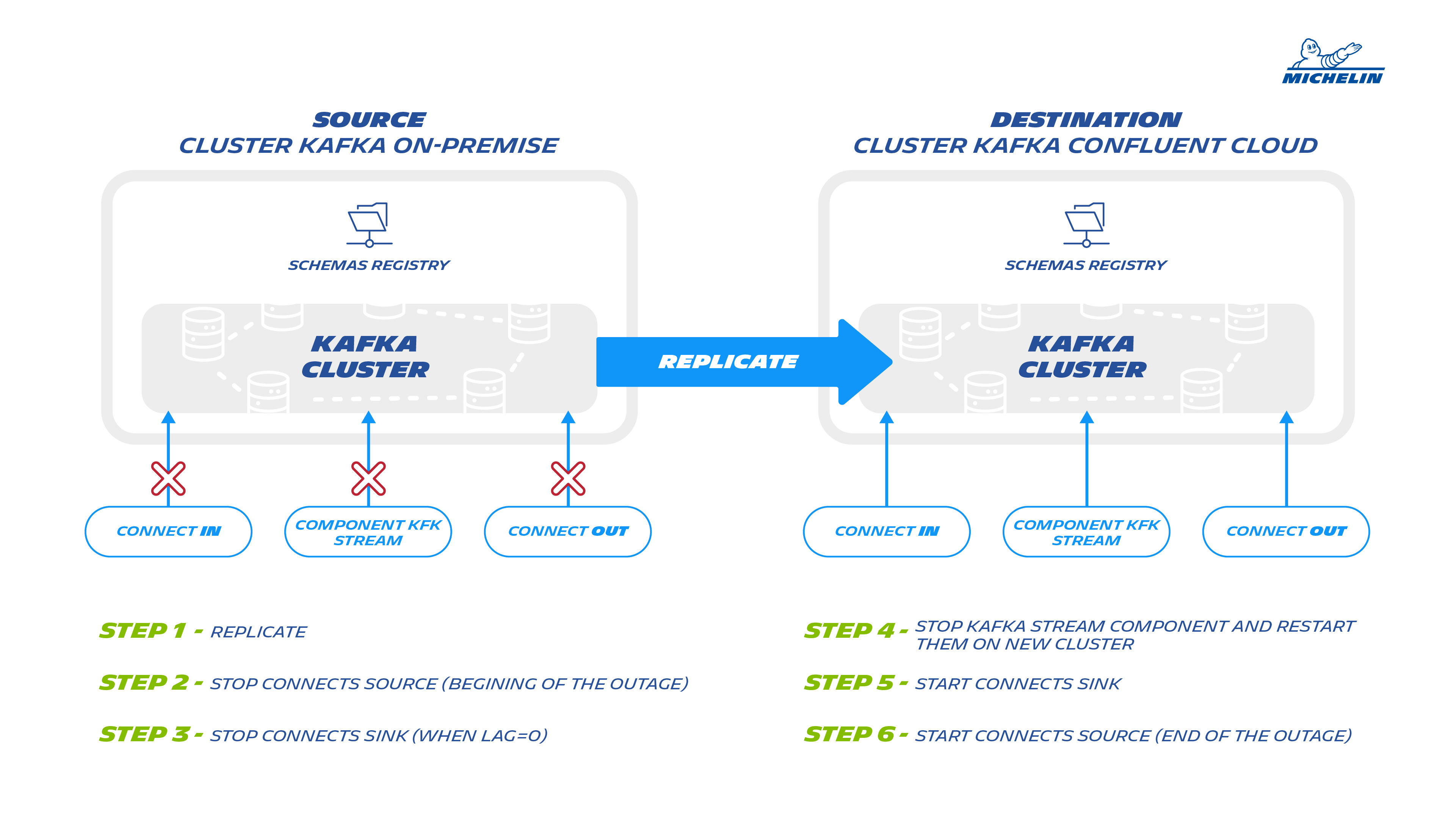
In less of 2 hours of downtime, the team has succeed the migration, but with a huge work of preparation.
I hope this article was interesting for you
The key points:
- The migration is not easy as we can imagine.
- The strategy for the schema registry, should be studied in advance and could impact the strategy you have internally between yours several clusters.
- The coordination of team for the migration is Key.
From the beginning of the migration on Confluent Cloud, we have no major incident detected (several months).
- We don’t have anymore to follow “carefully” the sizing to regularly increase the number of disks.
- We don’t have to carefully follow the number of partitions of zookeeper to increase the number of brokers, adding machines, to keep a good level of performance.
- And the must:
"We will not have to manage the removal of zookeeper in the next version"