
“The metamorphose” of our Information System by Implementing a distributed event streaming platform
In this article, I want to share Michelin's experience on its first implementations of Kafka and distributed architectures, which is part of the early stages of implementing our EDA architectures. Our firsts experiences we had on a distributed platform.

{kind=link}

We have two ambitions at Michelin for our Information System:
#BeEvergreen: continuously modernize our information system
#BeDataDriven: Support Real-Time Analytics use cases,
The architecture style that clearly help to support these two ambitions is the Event Driven Architecture and we have chosen to introduce the Kafka technology (and its ecosystem) to enable this architecture model shift.
In 2018, we started several initiatives to use Kafka. One of them was in the Supply Chain domain. Our first usecase was in the MDM (Master Data Management) area with our worldwide referential for Products/Services and Parties (Customers, Suppliers …).
This system is publishing events in real time, products and parties, and we have two kinds of subscribers.
Front end systems (ie exposed to our customer) such as Order management. They require to be updated as soon as events are published,
Back end systems such as the Deployment Resources Planning (in charge of defining how the items we are producing should be deployed in our inventory warehouses). This kind of systems usually consume these events in what we could call “Batch” mode. That is to say, they don’t need to be updated right away.
With the MDM integration layer, we didn’t have the right capabilities to cover this use cases, we had different tools and problems with these existing layers, we seen the opportunity to:
- Drastically reduce the diversity of integration technologies
- Implement a back-pressure mechanism: avoid overloading MDM when a publisher massively sends messages
- Increase autonomy of teams on MDM data consumption, to let each consumer define how to consume and at which frequency
- Give capabilities to consumer to re-consume data
- Enter in the streaming world and help reducing the time to create customers
We decide to adress these requirements with Kafka.
The Challenge is taken! Let’s Implement a cluster Kafka!
First Step: The Hosting
We have decided to install our cluster in our On Premise datacenters. This choice could be perceived as awkward, but we made it to ease the integration with our consumers as most of them are hosted On Premise.
The second main decisions we made was to deploy our cluster on dedicated VM and not in containers. Why? Because, we were not mature yet on container platforms in 2018 and Kafka requires persistence storage which is still tricky to manage in Kubernetes clusters. As a matter of fact, hosting Kafka in Kubernetes for instance is a difficult task and you’ll found many articles to detail why it’s. Confluent, the main software vendor behind Kafka, experienced lots of difficulties when they created their managed services in the cloud.
Second Step: The Configuration of the Cluster: A distributed platform, with high availability:
To choose the right technical architecture to implement a Kafka cluster, we must answer an important question: Which capabilities are we looking at?
- scalability
- durability
- Latency
- Throughput
As you know, you can’t have all of them at the same time (architecture is always a tradeoff at the end), and if you’re not convinced, you can refer to the famous CAP theorem.
So, which one to choose in our context? We opted for durability as we wanted to ease the initialization of our systems for our MDM data (product and parties). In that specific context, it was very important to us to not loose data. Scalability & throughput were not really an issue (we were not about to publish millions of updates per second). When it comes to latency, even if we wanted to get rid of the batch approach we use to have for decades, we could tolerate some delays between the event publication and its consumption.
We decided to implement a cluster with a replication factor set to 3 and we created a stretch cluster on our 3 datacenters with 5 virtual machines:
- Data Center 1: 2 VMs
- Data Center 2: 2VMs
- Data Center 3: 1 VM
Why 3 datacenters?
- 2 datacenters, to be able to support the loss of one datacenter.
- 3 datacenters, There is no backup with Kafka, to cover this risk we decide to deploy our cluster on 3 datacenter. Backuping Kafka does not make sense mainly because Kafka flush its memory on regular basis which makes the hot consistent backup almost impossible. If you’re losing a broker node, you better not restore it but create a new one and rely on the replication mechanism provided by Kafka and wait for its completion. This stategy may be difficult to sustain over time as the bigger your cluster is, the longer the replication will take.
To ensure the availability of the data we have a mechanism of replication. Our cluster is implemented a replication factor set to 3 on all our topics. And One copy by datacenter.
The cluster was composed of:
- 4 Kafka brokers
- 5 Zookeepers
Zookeeper replicates whole data configuration to all the quorum servers. The minimum number of servers required to run the Zookeeper is called quorum.
This number is also the minimum number of servers required to store a client’s data before telling the client it is safely stored.
Quorum size should be calculated by the rule Quorum= (N + 1) / 2
N is the number of Zookeepers
So, with 5 zookeepers, we are able to support 2 failures (1Maintenance server and 1 crash)
Kafka is an ecosystem and thus it’s not limited to the broker & zookeeper components. We are also using the schema registry (to manage the schema of the events & messages we store in Kafka) and Kafka connect (which ease to connect the information system with the Kafka broker). These two components added 2 VMs each.
The schema below represents an overview of the Kafka Cluster implemented
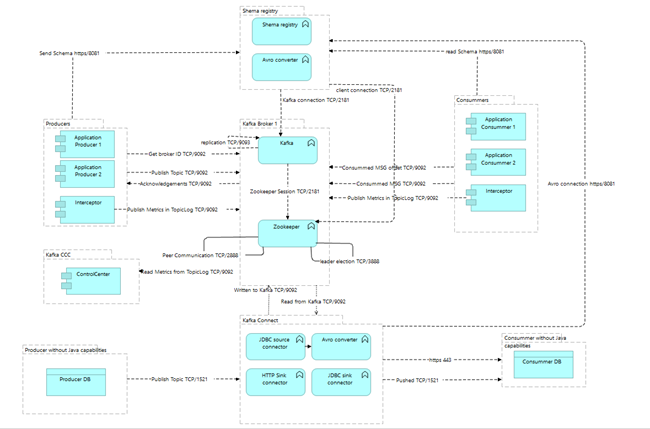
For resilience and High availability:
Our architecture is designed to support the loss of one data center or the maintenance of 2 VMs (crash+ release for example). This was achieved with a series of decisions as explained below
- We decided to have 3 replications of our data (parameter replication.factor)
- We accepted a loss of one copy of data, a crash of One VM (min.ISR at 2) if we lose a second broker, the cluster will stay in readOnly mode, waiting the restart of at least one broker.
- We have one copy of data per data center: the parameter « rack_awarness » allow us to configure our cluster to have one copy by Rack of VM. The VM of a same data center are group in the same rack.
Configuration of our server.properties (Config file of the broker)
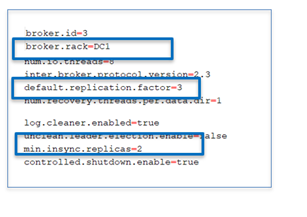
We also required some specific infrastructure configurations at VMware level. Here we must highlight that these configurations are not always feasible in a highly mutualized VMWare environment. Kafka is designed to support failures and does not rely on the hypervisor to ensure resiliency. This is a big change as we used to rely on VMware hypervisor to deal with failures.
- We required to disable the DRS (Distributed Resource Scheduler). It is a VMWARE mechanism to rebalance the VM on the ESX servers to optimize the usage of the resources at the ESX level. To ensure the High availability of our cluster, the VMs in a datacenter should not be hosted on a same ESX server. But this requirement is not standard at Michelin, so we ended up to setup no affinity between our VMs.
- As Kafka is working in memory, we required to not have overallocation (ie no Ballooning) to be sure to have the full capacity of memory allocated available for our VMs. But once again it does not comply with the Michelin standard Vmware implementation.
- To allocate the maximum of Memory to the cluster, we setup the swapiness parameter to 1, to avoid the swap. With this setup the cluster is using all the memory allocated before swapping, so we have a higher level of performance

- We expect “guaranteed IO” for zookeeper, but with the existing VMWARE version in Michelin, it was not feasible.
- We required some SSD disk, but it was compatible with the standard VMware implementation at Michelin. We got VMDK Disks which are 30 times slower.
This first technical infrastructure was a tradeoff between the expected requirement given by Confluent and the constraint given by the Michelin Infrastructure teams. A lesson learned here is that the Kafka technology is a big paradigm shift not only for developers but also for infrastructure. The way we used to deal with failures (heavily relying on solutions like VMware) is clearly challenged.
From powerpoint to the reality! One day in PreProd:
We find our producers down on a Monday morning. After analysis with the network team, we discovered that a network latency between two datacenters caused issues in cascade from the cluster to the producers of data. During this latency issue:
- Due to a bad timeout setup on Kafka, our cluster lost the connection with some of its member.
- To secure its data, the cluster wanted to write its data quickly on disks.
- Due to the poor performance of our disks, the cluster spent time to perform its I/Os and the cluster hang the production of data.
- Due to a bad retry setup in our producers, they failed explaining why we found them down in the morning.
We implemented lot’s of mechanisms to secure the availability of our system without understanding all the cases for failure and all the behavior of the system.
And now in detailed:
First thing, we must live with this network latencies! (fallacy #2 here: https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing)
Here are couple of symptoms we experienced during this Latency issue.
Symptom of the latency between cluster nodes:
we can discover this kind of “INFO” messages, in the logs of the broker. Message: “Intermittent ISR shrink and expand” within seconds

When a member of the cluster is seen as lost, the cluster reassign the leader <partitions of the lost node to the others. That’s a normal process. But when it is done to frequently, it is not normal and it is a symptom of a network latency.
These issues that usually occur when Kafka brokers and Zookeeper nodes are deployed across multiple data centers or availability zones. By choice we have a cluster stretched on 3 datacenters. So there is latency between them, and we have to live with. We made sure these latencies were acceptable for a Kafka cluster, but there is some setup we have to know and we have to setup correctly
connection.timeout and session.timeout have to be adapted to this latencies.
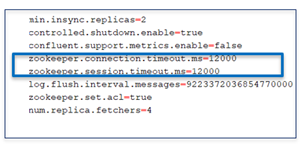
Symptom of I/O waiting: we could find these messages in our log indicating the fsync operation (to flush the zookeeper memory on disk) could take up to 45 sL
In that case, there is no magic: we had to switch our disks to SSD disks (as recommended by Confluent but we had to face a major issue to convince it was a necessary change)
Symptom of the latency between the cluster and the application:
Message “Rebalance”:

In the controler.Log, we can find this Warn info link to the rebalance:
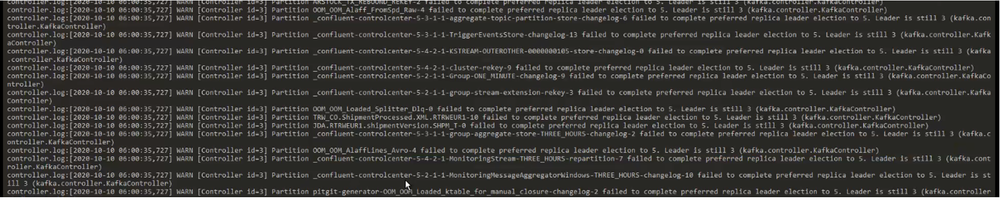
It is not enough to think only on the resiliency of the cluster. We have to setup properly our Consumer/producer applications to deal with failures. And that is a major lesson learned: Kafka by itself is resilient but it is not the silver bullet to all our issues.
The easiest solution to achieve resiliency on those apps is to send some status updates over the network saying that we’re still alive and evict each other based on some sort of timeouts. So, if a consumer didn’t contact Kafka in time then let’s assume it is dead, otherwise it is still up and running and it’s a valid member of its consumer group. This is called heartbeat and it can be setup using these parameters:
- startHeartbeatThreadIfNeeded
- request.timeout.ms
- delivery.timeout.ms
We have to tweak these parameters at the application level to setup the number of retries and the duration upper than the network latency we can measure.
Network latency are very frequent, we must live with and make sure they do not affect either the broker or the applications using it.
Lessons learn !
From Reliability to Resiliency:
We must think differently. We have to design our application by anticipating the potential Infrastructure failures: network latency, unviability of a broker, ….
From the application to our infrastructure: we must have a systemic approach and understand how Kafka is working to setup properly our infrastructure and our applications.
The Next steps
The technology is working well. And once we learned about these setup parameters and why / how we should use them, Kafka is hiding most of network failures. And there are many.
Since these early learning days, several new use cases appeared as Kafka grown quite popular at Michelin. We will soon increase the size of our cluster to support these new workloads. We have already planned to upgrade our cluster with 2 new brokers by rack.
And we are also waiting for the next major release of Kafka which could help get rid of the zookeeper component. Removing zookeeper will help us to simplify our infrastructure and it’s always to remove complexity.
We often discover new indicators to follow and new ways to optimize our configuration, it is very exciting. And that’s only the beginning given that we have more and more use cases for streaming with Kafka Streams. And the use of streams will definitively help us to move to the next maturity level in our Kafka adoption journey.
Stay tuned as I will share our discoveries regularly . And if you want to get involved, we’re hiring.