
Self Service BI Development - Value Generation or Chaos Management? - Part 2


End user development. Increased adoption of the Power Platform. Empowerment. Data literacy. Do-it-yourself reporting.
These are the terms I started off my previous blog post with, Part 1. The desire for these things has increased even more since I published my previous post. Data is becoming more valuable by the second, with both the emergence of AI and the rapid acceleration of citizen development. It is no longer necessary to have a computer engineering degree (or even to know how to code!) to make a customized dashboard highlighting key business metrics. Ability to spin up a proof of concept is at a business user's fingertips more easily than ever before.
During my last post, I focused on a specific use case as an example and a cautionary tale. This post, I want to highlight how we are crafting our approach in the region to make self-service development more value generation and less chaos management. I'll also provide my opinion on some of the opportunities and pitfalls present in our evolving technical landscape.
Our group has a large number of initiatives tied to moving our company forward with data, too many to fit in one blog post, but I plan to highlight three key areas we are working on with respect to self-service:
- Data foundation
- Personas
- Data governance
I'll then provide my personal commentary and opinion on our past, present, and future role in this data evolution journey the company is on together.
For transparency, the three items mentioned above will not fix all our issues and won't automatically make us successful. But these fundamental pieces must absolutely be done right to build upon toward success.
For reference in the remainder of the article, I'm the full-stack technical architect of a group called Business Intelligence and Analytics, a data organization which is a sub-department of our greater IT organization the Americas region. I'll be referring to this group as BI&A for the remainder of this blog.
Obligatory Mention of Artificial Intelligence
I can't have a post related to data without mentioning AI. It isn't the focus of this article, but I think it's important to highlight its place. I think it's a very powerful tool and our industry is just scratching the surface of understanding what it can do.
But I also think we're just scratching the surface in understanding what it can't do. And powerful tool doesn't mean magic wand. I firmly believe in focusing the conversation around any new need to: "what business problem are we trying to solve?"
To be clear, I think the three previous headings (personas, data foundation, and data governance) are the most important fundamental pieces of our self-service data approach - and I think people and their specific responsibilities are core to any of those pieces above. With those pieces in place, I see AI with huge potential as an enabler.
Without those foundational pieces in place, I see AI on top of this being one of two things:
1) Best case scenario - not very helpful, calling out missing pieces of information or lack of clarity required to perform an analysis
2) Worst case scenario - actively detrimental, making assumptions based on data that is not present or is low quality - misleading users and generating business decisions based on erroneous output.
Even the best process and tool cannot fix bad inputs. I've seen several similar memes circulating, and it sums up my thoughts well on responsible and irresponsible usage of AI.
I don't think AI helps in implementation of any of those items either, nor masks deficiencies in those areas. All three of these areas are very ambiguous; they need clear definitions, parameters and good data before taking action. Now, on to those previously mentioned important areas.
Data Foundation Ambitions
First, a bit of context. Our environment is set up with different levels of refinement and different parties responsible for each layer. Below is a high level diagram showing this:
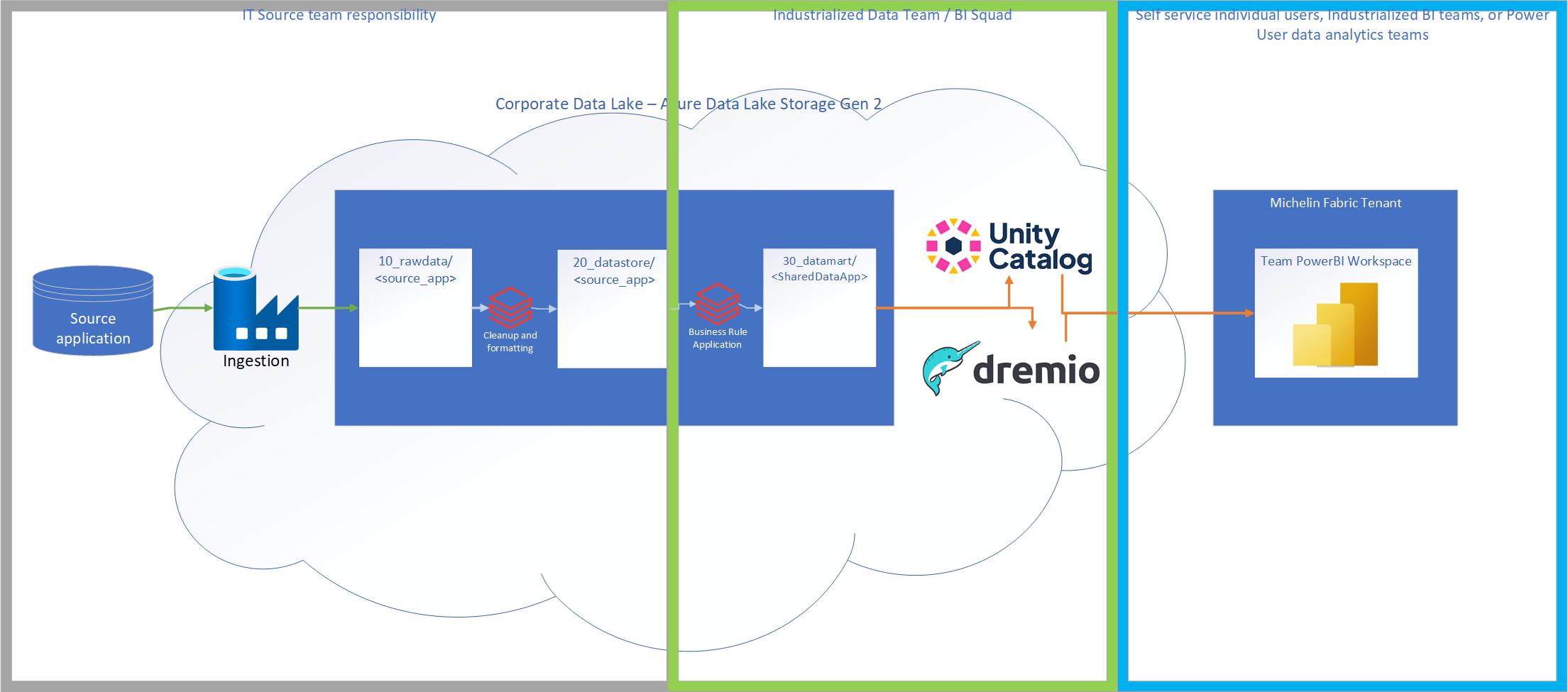
This flow is designed to illustrate that although self-service primarily operates in the blue box shown above, there are many steps that need to happen and underlying pieces that must be in place before that can occur.
The core ecosystem in the middle of all these tools is our Corporate Data Lake, which will be referred to as the CDL throughout this post. Data is brought in from the IT source application to the bronze layer (10_rawdata), cleaned by the IT source team between the bronze and silver (20_datastore) layers, then business rules are applied to create data in the gold (30_datamart) layer. After this step, data is exposed via some sort of access layer - the two primary ones in the company currently being Unity Catalog and Dremio. From there the data can be accessed for a variety of uses by multiple parties (i.e. AI solutions, Power BI reports, custom Streamlit application, etc.).
We recently conducted a workshop around building our data foundation in the region. The workshop focused primarily on the green box above; the gold layer and exposition layer afterwards. Most of the stakeholders present in the meeting were either business stakeholders interfacing directly with the business units aiming to make data-driven decisions or power-user citizen development teams assisting those groups. Most business groups work with data in some capacity (but all should! 😄); we started with a focus on North American marketing and sales for the purposes of this exercise. Here is a snapshot of the prework questions the attendees were provided for context on the parameters of the exercise:
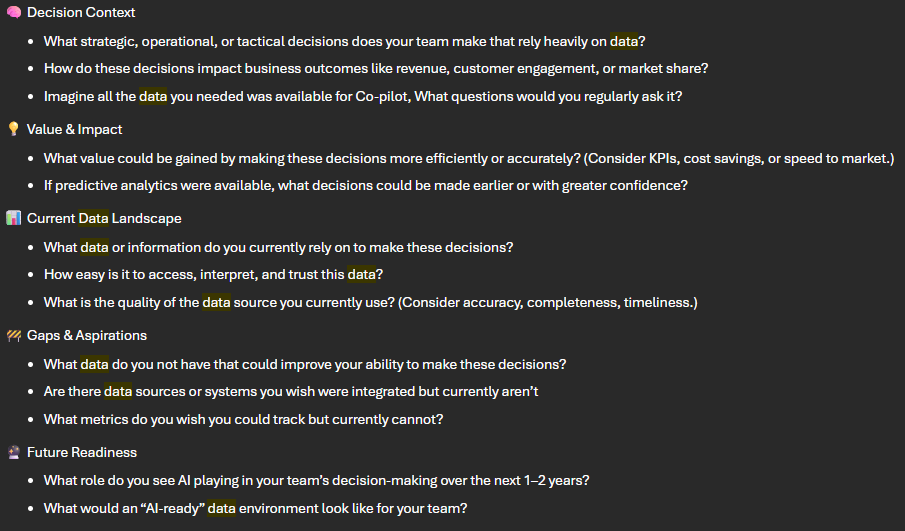
We're still working to synthesize all the input into both well-defined functional requirements and the actionable items. Some of the input wasn't surprising, but some was rather eye-opening. A few high level takeaways:
- Lack of transparency and documentation on where gold layer datasets are sourced from
- No data quality process checking nor process on this data
- Prioritization conflict and process bottleneck on modifications and additions in gold layer by analytics department such as BI&A
- Unclear dividing line in responsibilities between a data organization such as BI&A within the IT department and a self-service data analytics team in the business
- Heavy majority of needed data from 3rd parties requested by both marketing and sales stakeholders is not available within Michelin's data ecosystem for usage
- Very unclear and slow process for bringing in this data
In the past 5 years, our data group moved from a central data group performing all steps of the data lifecycle to a more distributed responsibility model, as you can see in the previously mentioned drawing. As a result, I expected 3rd party data to be a pain point; there is no clearly defined IT source system team for an application that doesn't even belong to the company. I was surprised at the volume of needed (and unavailable) data and criticality expressed by the workgroup. This will be a key area of focus during the planning phase.
Personas
Our approach, at a high level, focuses on identification of different personas with different needs - then guiding those personas towards different tools and a different level of curation of the data. The bulk of our approach focuses on an 80%-20% approach. We will focus the majority of our energy on creating a path for the 80%, operational consumers, which will be the average people integrating data tools and analysis into their day-to-day work.
The 20% will be very important as sometimes these power users and data scientists will help us challenge some boundaries and tools in our approach and pilot some new ideas. But they will not be the primary focus.
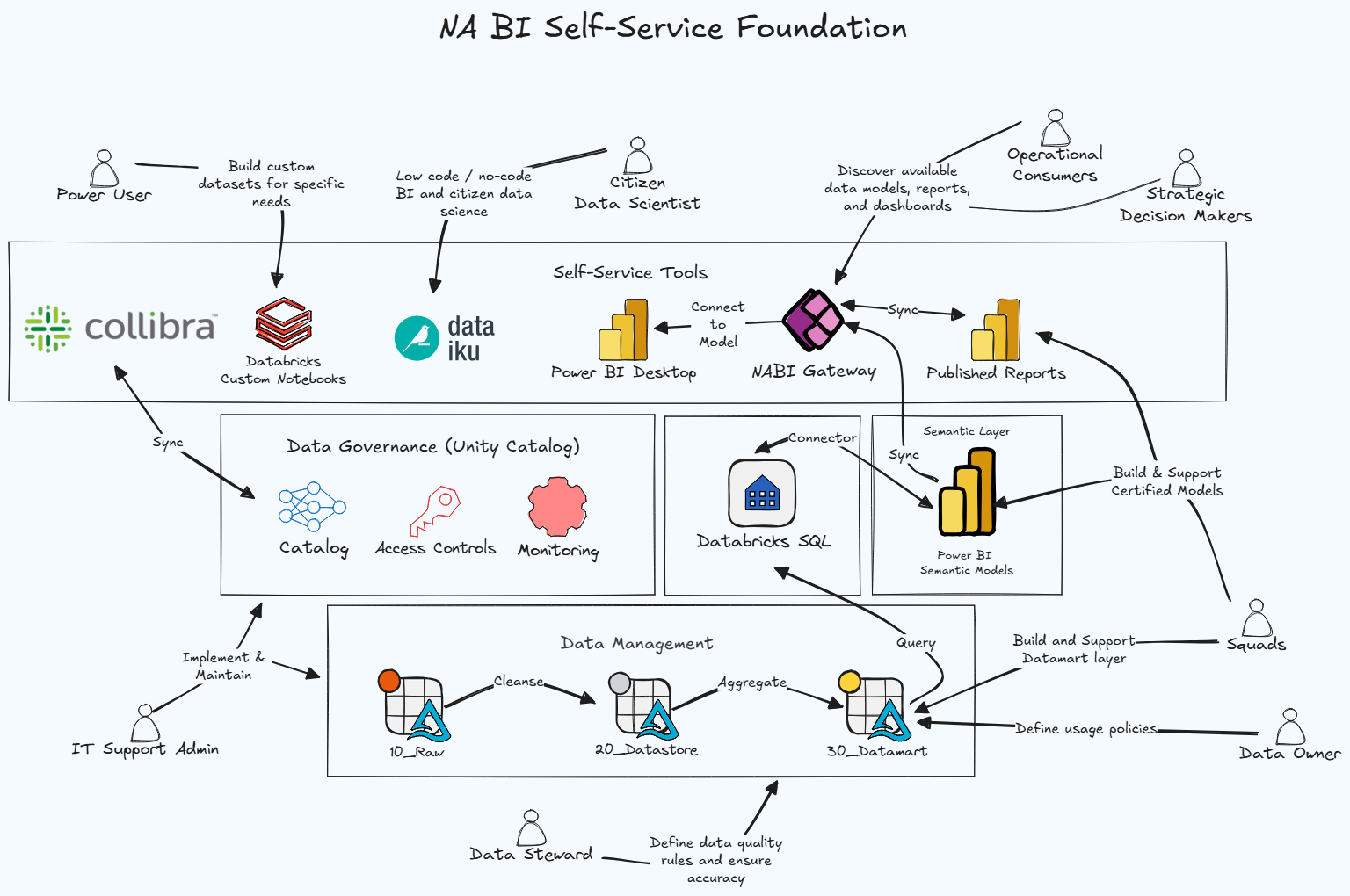
I do want to make two clarifications on the above drawing, as it is being used in this post for a broader audience than it was originally created for. First, squads more specifically refers to BI&A Data Product Squads. This self-service approach is for the North America region, but is being driven and facilitated by BI&A. With greater adoption and success, I'd imagine some of these groups, tools and integrations would change and adapt and the needs and community evolved.
Second, our global data cataloguing tool is Collibra, which is highlighted in the above drawing. I will provide more detail on its vital importance in the Data Governance section. The Power BI Gateway shown above has some overlap with Collibra, but is intended specifically for direct instruction, interactivity and integration with Power BI datasets that BI&A manages - covering many features not available at this time in Collibra, but not serving as the full underlying official documentation. Our ambition, working with the global team, is to have these features available to the users' satisfaction in Collibra. But in parallel to that, this will allow us to fill the gap based on direct user feedback.
There are other user personas as well, along with support personas in the diagram above. Our self-service technical team has compiled a list and description of these personas. Here is a more detailed look at the user personas:
.jpeg)
And here are the support personas:
.jpeg)
As you can see, all these above personas play a very different but critical role in ensuring we can unlock the maximum value from our data.
Data Governance
Our department director has regularly described this activity as "making sure to eat your vegetables." And I thought it was appropriate to share here, as I love the analogy.
It isn't the most glamorous, exciting activity. Everyone begrudgingly agrees it is important. But no one really wants to do it.

We have multiple teams across the company dedicated to working on this with far more expertise and insight than I have, so I won't pretend to be the expert here and will keep this high level. But from a people standpoint there are three key responsibilities all data products need:
- Data owner: An ultimately responsible and accountable party
- Data steward: A business subject matter expert. The primary contact point for how to understand, interpret, and derive insight from a specific data product.
- Data custodian: The technical administrator, responsible for providing access and supporting availability and usability of the data product.
Sounds simple, right? And on paper, it is. But the biggest challenge has been finding people that can perform these activities from a capacity standpoint, whether that is hiring another headcount or tacking this on to someone's existing job responsibilities. This challenge is magnified in a scenario I mentioned earlier - third party data. The second biggest challenge? Education and skilling. Sometimes an individual is brilliant working with a specific system, but not well versed on data practices, let alone how to educate others on best practices for using the data.
These parties are also responsible for updating the appropriate information in our global data catalog, Collibra. This provides a critical central repository for any of our users needing information about data sources, fields, descriptions, confidentiality and more. It is important, but like the other pieces, it requires time, upskilling and capacity.
How does this all tie together?
I mentioned earlier the global move to a distributed responsibility model. Historically, the BI&A department was in charge of all the data activities in the region. Bringing the data from the source system, cleaning that data, curating it into datasets and applying business rules, and creating the reports (or other analytics data products). This was handled similarly in other regions.
The benefit was a cohesive approach. The drawbacks? It was siloed and unscalable beyond a certain point. It also limits the product to the perspective and skillset of one team. It certainly isn't scalable to the ambitions of our data-driven company, where data is a key lever in each individual's day-to-day job.
Now for my opinion. I like the global approach. I mention this up front because I know I have very smart coworkers who disagree with me, which is a perfectly valid opinion. I have healthy debate around this topic with them on a regular basis, and I will continue to do so. Sure, there are and will continue to be growing pains. And I think there will need to be some tweaks here and there when gaps surface (i.e. how do we identify and upskill responsible parties for 3rd party data?). But I think we must have ultimate responsibility to those closest to the product; IT source teams should own and manage access to data in their application, and teams should be empowered to build data and analytics products themselves tailored specifically to their needs.
So if I think the approach is good, what is the problem? And why do we have rogue solutions like I detailed in my previous blog post? First and foremost - change is hard and will naturally take some time.
The next part will be more challenging to fix. It centers around three things.
- Education and upskilling
- Just ceding responsibility to another group and holding them accountable isn't enough. Both IT source teams and business teams looking to build self-service reports often have little understanding nor experience around data products. And that's to be expected! Why would they? I work with many teams that don't even know where to start with questions to ask. There needs to be a clear set of competencies and skills needed for these teams, and more comprehensive guidance on how to get there. We have an amazing communication and competency development manager in the region that has made great strides pushing us in that area. We just need to continue pushing in this direction, educating and evangelizing. Full adoption and results will just take some time.
- Capacity and prioritization
- I can't speak from personal experience for those working in business units. But I have worked on multiple IT teams before, and it seems there is always another hot button initiative the team must integrate with their core work. I'm not diminishing the importance of these; the challenge becomes when it is too much, and which one goes by the wayside. A way around this is hiring additional resources with the desired skillsets - but this requires additional funding that must be justified.
- Control, guidance, and empowerment
- I think this part could change fluidly, and could be more of an art than a science. Organizations like BI&A need to continually transition from being doers to enablers and subject matter experts. I think this takes the form of communities of practice, education, and frameworks. We need to move away from doing both the data sourcing and the reporting + analytics. That said, I think it's important to provide guidance and tools to these groups. But then people like me need to resist the urge to dictate how it should be done - even if it isn't the way I would have personally done it. Overly prescriptive approaches and mandates will undoubtedly result in more shadow IT solutions.
Wrap Up and Next Steps
To summarize, the focus really sits on three foundational pieces at a high level: a technical base, people and process.
We must continue to build the technical framework based on constant communication and feedback with the business; the workshop was a great start.
We've identified personas we need to cater to and their place in this initiative. That's great, but now we need to find ways to appropriately involve them so they can start generating value.
We're educating on the critical data roles for each data product; we need to continue doing so and building out that network so all data products have responsible parties and a robust process around it.
All these things are important, but none of them generate value by themselves. And that's why the most important part is engagement. Real value from this comes from actual usage by those that know the systems. Those that know the data. Those that make the decisions these should be influencing, and tying all three of those more closely together.
We plan to start up communities of practice for data engineering. We plan to educate and build out the data steward network in the region. Our department is teaching an increasing number of Tech Ed sessions for various business departments. We aim to build a community of excellence around analytics and reporting. Our Power BI training portfolio is expanding.
And we need to take feedback, adapt, and be willing to fail and try something else. Some things inevitably won't work and won't have adoption. That's okay. Because we may have different roles to play, but need to keep in mind that our goal is the same - being a data driven company from top to bottom, and empowering everyone to do their jobs more efficiently with the best and most reliable information possible.