
Exponential Information Systems for a Data-Driven World
We live in times of accelerating changes fueled with “exponential technologies”. “Exponential Information Systems” is all about constant adaptation for the information system. This article details it and show how it can contribute to a data-driven backbone towards a data driven company.

{kind=link}
1. Introduction
We live in times of accelerating changes that are fueled with “exponential technologies”. Exponential technologies are characterized by the exponential growth of the associated capacity, such as Moore’s Law. Singularity University proposes many instances of such technologies: Artificial Intelligence, digital biology, networks, or robotics. Adapting to the continuous flow of changes made possible by these technologies causes a true challenge to organizations, because of the increased rate of change and because the focus needs to shift from “inside-to-outside” to “outside-to-inside”. Salim Ismael’s best-seller, “Exponential Organizations”, describes how enterprises must transform their organizations to adapt to this new “exponential world”. Very simply put, an exponential organization (ExO) must be structured for change, it must accelerate its decision cycle, which leads to distributed and autonomous teams, and it must change its “edges” to be as porous and welcoming to outside innovation and information as possible.
I coined the term “Exponential Information Systems” (ExIS) a few years ago when I realized that the need for constant adaptation to outside-originated changes applied to information systems as well. Over the past decades I have noticed, with many other fellow IS managers or experts, two paradigm shifts. The first one is that we no longer design systems with decades of productive life. Each complex system requires piece-by-piece constant renewal. The second shift is that the skills needed to run information systems must to be renewed constantly. Being an expert means to learn fast, much more that knowing a lot (though, obviously, the two are related). There is a double link between ExO and ExIS. On the one hand, the same ideas and organizational principles are at work, such as modular architecture or open interfaces. On the other hand, an ExO needs an “exponential information system” as the backbone of its continuous digital transformation. In the world of exponential technologies, digital transformation is an ongoing journey that is never completed. Leveraging the constant flow of technology and data into new business opportunities requires IS to perform as an “operational backbone”, to quote the great book, « Designed for Digital : How to Architect Your Business for Sustained Success », from Jeanne W. Ross, Cynthia M. Beath, and Martin Mocker.
The flow of change that ExIS need to adapt to, and to benefit from, is data driven. It is a combination of data – companies need to manage an ever-growing amount of data, both internal and external – and data processing technologies, namely artificial intelligence, and machine learning. There are other challenges that Exponential Systems must address, as we shall later see, but the adaptation to a data-driven world is the most important one. Artificial Intelligence and Machine Learning are continuously evolving. On the one hand, these technologies are already providing tremendous value to the companies that have deployed them today. On the other hand, there is a lot of hype around, and many of the promises are more anticipation than reality. AI is not a topic for tomorrow, the value is there, but it is definitely a learning journey. Exponential information systems must provide the necessary data flows, the software environments that make it possible to try and integrate any new cognitive service, or machine learning library, with the minimal effort. The world of “Exponential Organizations”, as pointed out by Salim Ismael, is full of experimentation and learning iterations. We are talking here about “real world” experimentations – in production - with customer feedback, not closed-world lab experiments. This precisely requires a new generation of “exponential” information systems.
This post is organized as follows. Section 2 describes the concept of “exponential information systems”. I give a short overview of the architecture principles that contribute to design a system with a high rate of change. There are no silver bullets here, principles such as modularity, loose-coupling or event-driven architecture have been around for a long time. But there is more to ExIS than architecture, there are also technology stacks, resource usage patterns and ways of working, which contribute to adaptability. Software engineering culture and mindset also play a critical role, such as, for instance, the use of, and the contribution to, open source software. Section 3 focuses on the data-driven ambition of exponential organizations. One of the major goals of the ExIS is to deliver a data-driven backbone, which we present here as a “data infrastructure”. We explain how to move gradually though the learning curve of generating value from data. Exponential organizations grow value through continuous iterations and learning, with the co-development of data flows and processing algorithms. They have graduated from “advanced analytics” applied to data stores, to the design of reactive intelligent systems based on event flows. The last section talks in more depth about the design of systems of systems. System of systems (SoS) is one of the preferred ways of leveraging the rich toolbox of AI intelligent methods and algorithms.
2. Exponential Information Systems
« Exponential Information Systems » is a systemic translation of the organization principles, that Salim Ismael designed for companies, to information systems. These systemic principles are quite general – they relate to architecture, information flows and outside interfaces - and could be linked to complex system science. Here is a short summary of the six more important traits.
- ExIS must be organized for constant change. The first tool is modular architecture, which means here to develop a service-oriented architecture with a focus on independent, modular services. Microservices have precisely evolved as a solution to this requirement. The global system architecture must also accommodate the fact that, like for any other living system, the rate of change is not uniform. Multi-modal architecture is a way to organize modules into regions that change at different speed, and to adapt both the technology and the way of working to this required speed.
- ExIS are critical tools to support the customer-centricityambition of 21st century companies. Being customer-centric demands an “outside-in” organization of information flows. It also requires the constant adaptation to the environment (previous point) because in the digital age, customer’s needs tend to evolve faster than the company’s internal organization. When companies evolve from “command and control” to “recognition and response”, to borrow from Langdon Morris, Information Systems must adapt to a distributed network of autonomous teams.
- The world of technology is evolving too fast for companies to master all that they need on their own. Exponential organizations, especially as far as their ExIS is concerned, need to leverage outside expertise and innovation. Their outside-in organization does not only apply to customer information, it applies to technologies and skills. ExIS need to leverage outside communities, from open source solutions to open communities with skilled experts, to stay up to date with their technology capabilities.
- We live in a VUCAworld, so the adaptation to the environment implies to be flexible and agile. Opportunities arise and disappear, ExIS need to scale up and to scale down. Therefore, ExIS need to leverage elastic resources, such as cloud computing. This is what Salim Ismael calls “on-demand” resources. The use of external on-demand resources is necessary both for fast growth and for dynamic adjustment to the environment (elasticity).
- Kevin Kelly told us more than two decades ago that “intelligent systems are grown, not designed”. Exponential Information Systems are the result of constant adaptation to their environment, not the fruit of a careful and grand design. This is what Nassim Taleb calls antifragile: when systems react and learn from the variability and uncertainty of the outside world. ExIS are reactive and adaptive systems, they grow stronger and more efficient as a reaction to the stress caused by outside event flows.
- Innovation in our VUCA digital world requires to experiment and to iterate. This mandate for ExO translates into information systems that make it possible to experiment with the current flow of production. The most famous example in the digital world is the concept of A/B testing, but the requirement for fast innovation goes much further. Innovation methods have moved from the research lab to production systems, which is a new requirement for exponential information systems.
To build an exponential information system requires foremost a culture and a mindset change. The most important transformation is to raise the awareness of what is happening outside, and to import ideas, skills and technologies as much as possible. The use and practice of open source gives a perfect illustration. Leveraging open source software is the obvious consequence of the laws of our digital world. Open source solutions are of great value because they are “grown, not designed”, by a community. The nature of open source (the access to code) means that thousands of eyeballs contribute to the testing, the improvement, the refactoring of the code footprint. Open source solutions are interesting not only because of what they deliver but also because of the way they are built, though iterative adaptation. This is where the culture and the mindset aspects come into play. The best way to use open source is to participate, to be active. It does not always mean to contribute; it can simply mean to be an active participant of the user community. There is a learning curve; what matters is that being active helps to “learn by doing” the best practices of software, such as CICD or DevOps. To adopt an open source solution is to subscribe to a constant flow of evolutions, to strive for automated upgrades and delivery. The same could be said for APIs (Application Programming Interfaces). The best way to design your API is to heavily use successful APIs written by other programmers. We have been using open source software at Michelin for more than a decade and I strongly encourage our Michelin colleagues to participate and contribute to the relevant communities. Our ambition, along our journey towards an exponential information system, is to propose some of our own tools and solutions back to the open source world. The fuel for ExO success is talent, this is also true for ExIS. Attracting and retaining the best talents is also related to the openness and the capacity of a company to develop a rich synergy with the most exciting software communities. Promoting an open source strategy, as we do at Michelin, is not simply a matter of dollars-and-sense, it is a question of strategic ambition. In world that changes constantly, code is back. The world of black boxes and integration by design is too slow for the VUCA constraints. We see the return of scripting, integration as code, functional languages, and high-level-of-abstraction programing. At Michelin, we see open source as the only way to create the culture of software craftsmanship and code peer-reviews that is necessary to deliver the exponential information systems ambition.
The following illustration is taken from a keynote talk that I gave a CSDM in 2018. It represents a summary of what makes the architecture of ExIS a fascinating topic. Here is a short introduction to some of the topics that I brush here.
- Multi-modal architecture is the evolution of the famous (and infamous) bi-modal IT architecture. It follows principles found in the biology of living cells – that may also be found in organizational theory, such as with BetaCodex. Modules are organized with a center and a border, so that the outside part is better suited to change than the center. API-centricity, as postulated by Jeff Bezos, is a critical tenant of modular and change-ready architecture.
- Event-driven architecture is a key component for building a reactive system, which is the ambition of ExIS. We will explore this aspect in the next two sections.
- Monitoring and automation are the necessary ingredients to design efficient and cost-effective ExIS. Smart monitoring requires a jump to higher abstraction level. I talk about “serverless thinking” because, although serverlessis not a panacea that works for all kind of computing loads, it is a great way to think about systems (and, when relevant, it is a great way to build elastic and reactive systems).
- Resilience is critical in the digital world. Resilience in a VUCA world requires lean thinking to introduce true systemic de-coupling and to avoid “catastrophes” (overload avalanches). Capacity planning in a VUCA world is a combination of “Black Swan” thinking and “Chaos Engineering” practice.
- Living in a world that is hard to forecast does not mean that one cannot be smart about it. AIOps (Artificial Intelligence for IT operations) is where the “smart” in “smart monitoring” comes from. The same concepts of “digital twin”, “predictive maintenance”, “adaptative balancing” of Digital Manufacturing applies to ExIS. This implies that ExIS are “reflexive” and know about themselves: a dynamic and complete inventory (IS for IS) is part of an effective ExIS.
- ExIS are large-scale resilient distributed systems. Thus, they operate in the application field of the CAP theorem that says that consistency does not coexist with high-availability and tolerance to network partition. This implies that many of the services that are implemented through distributed flow computing – for instance using Kafka – must operate under the eventual consistency paradigm.
- Complexity and resilience do not necessarily mix. Nature has shown that evolutionary designs are layered and that complex systems (think of our cortex) co-exist with simpler ones (think of our reflexes). Designing intelligent complex systems that deliver safety and resilience can benefit from biomimicry and copy some of the redundant designs that we see in nature.

3. Data-Driven World
The “data-driven ambition” of exponential organizations, as told in Salim Ismael’s book, is to derive as much value as possible from data, in a world where the amount of available data grows constantly, and where the technologies for data processing improve exponentially. The following is a simplified view of a “data-driven value chain”. The first three steps (in blue) are the necessary preliminary steps to define, collect and make data available: the foundations that ExIS must deliver. Data is first used to help the company work better and more efficiently. Following the ACATECH maturity model, one can say that data first helps to see the situation better (thanks the exponential growth of sensors and thanks to data visualization), then to understand the processes better (thanks to data analytics techniques). From understanding the present, analytics can help to foresee the immediate future, to help employees make better decisions. As data science tools become more powerful, they evolve from forecasting to decision-aid tools for adapting the processes to the environment. Once an adaptive loop is properly mastered, it can be automated to become one of the “reflexes” of the adaptive company. These five steps (represented with the first two green arrows) correspond to the usage of data for the good of the company. The next two links of the value chain occur when the company has become so good at extracting value from its data that it can sell it to a third party. The “Data Services” maturity level happens when a company sells its data-driven expertise to its customers, as a service, with the possible help of a platform. When a company delivers a data service, it knows how the value is derived from the data. The “Data product” is another case where the data, or any byproduct of the data obtained through intelligent processing, is made available or sold to a customer, for their own use. When a company delivers a data product, it does not necessarily know how the consumer will use this product. Note that nothing prevents a company from selling data products as soon as the data is available. Representing this step as the last link of the value chain reflects the observed practice : companies that are good at creating data products usually have mastered the learning curve and became experts at deriving value for their own benefits – following the principle that the best digital services are developed by companies “that eat their own dogfood”.

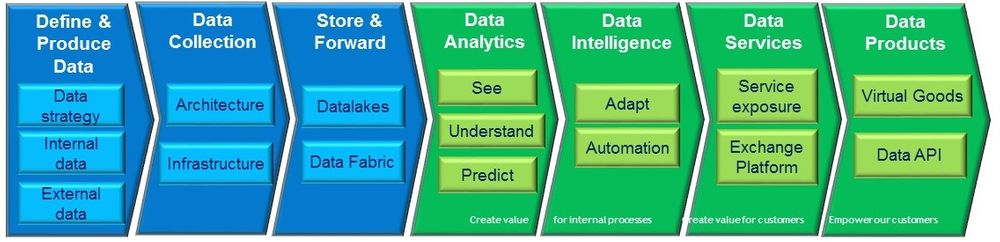
The previous value chain implicitly represents a learning journey for the data-driven company. Moving through each level requires both an increased awareness about how valuable the data is (the data strategy becomes more and more sophisticated along the value chain) and an increased sophistication with the use of data analytics tools. “See” and “Understand” are the domains of traditional busines intelligence, “Predict” and “Adapt” make heavier use of data science and machine learning, and “Automation” can leverage the complete toolbox of AI techniques. The other implicit journey is the evolution from a traditional view of extracting insights from data at rest (what is called “cold data analytics”) to the world of reactive systems (“hot analytics”). These two approaches should not be opposed but joined, which is the basis of the lambda architecture. Cold analytics can afford to spend more processing time, this is where the more sophisticated approaches of data science can be used. On the other hand, cold analytics always operate on past data, where hot analytics can work on the present. As a consequence, hot analytics makes the enterprise more reactive and resilient. When a completely unforeseen situation occurs, such as the COVID crisis, hot analytics are much more relevant than anything based on patterns extracted from past data. Moving towards a reactive systems ambition is also the root of true customer centricity. The last-century generation of batch-processing systems have created delays between the moment a customer event is received (from an inquiry or an order to a claim) and the time when the company reacts.
There is a third dimension in the data-driven learning journey : how to grow reinforcing loops. The report from NATF on Artificial Intelligence and Machine Learning shows that the best-in-class data-driven companies do not mine insights from their past data, they build learning loops with the constant acquisition of new data, with a positive reinforcement cycle : more data yields better services that generate even more relevant data, etc. What really matters in the data-driven revolution is to create loops that encompass the whole enterprise : to leverage usage data to improve product R&D, to cross demand-management data with supply chain data, to link customer service data such as claims to the factory data produced by digital manufacturing. Therefore, the first requirement of exponential systems is to “break the data siloes” and make sure that data flows circulate freely between the different functions in the company. As noticed by Eric Schaeffer and David Sovie in their book “Reinventing the product”, this requires to work hard on common data models that support sharing information with unified semantics.
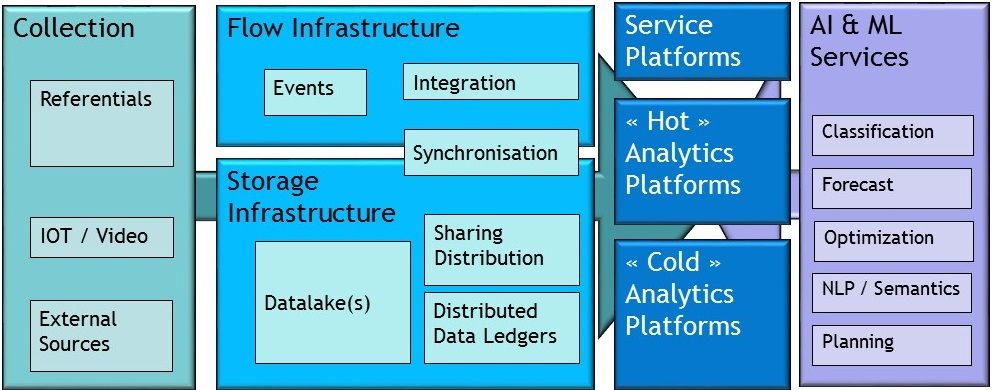
The main contribution of ExIS to the data-driven ambition is the “data infrastructure” that is the third step in the value chain represented above. Because of the “hot” and “cold” ambitions, it is labeled “store and forward”. The figure below gives more detail about the data infrastructure for the exponential information system. The “collection” and “infrastructure” boxes represent the foundations that IS must deliver to the exponential organization. The rest of the figure represents the data consumption platforms that create value as represented in the “green links” of the data value creation chain. The “exponential requirements” presented in the previous section apply to the data platforms as well (open interfaces, modular architecture, etc.), but I want to underscore the role of elasticity. Having access to elastic and massive amount of processing capability is critical because it sets the speed at which the company can learn from its data. This is the direct consequence of what we said about the need for iterative experiments, and the goal of building reinforcing data flows. The time taken to build and deliver one learning step depends on the processing power that is made available to the team. This could be illustrated in many ways : having access to the proper farm of GPUs to run Tensorflow, or leveraging cloud elasticity to run complex data queries – something that Snowflakedoes very well.
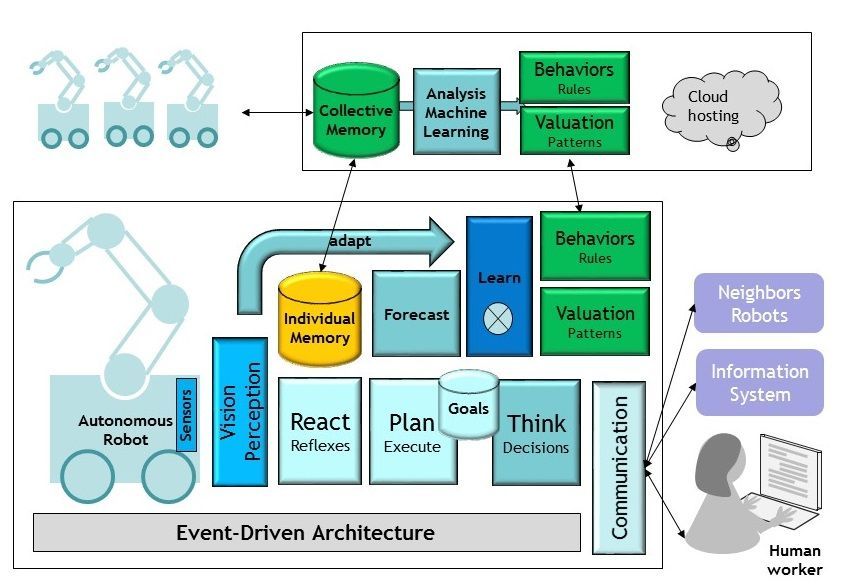
4. Systems of Intelligent Systems
I recently had the pleasure to be interviewed in the “Rise of the Data Cloud” podcast where I talked about data-driven challenges and data architecture for AI. I also talked about Systems of Systems, because I believe that this is the best way to bring the capabilities of AI algorithms into many companies. Artificial Intelligence is a rich and complex box with different tools. As explained in “Architects of Intelligence”, many of the most advanced “intelligent systems” use hybrid combinations of many tools. This may be done at the algorithmic level, using “meta-heuristics” to combine different techniques, or it may be done at the system level, using different modules which are based on different forms of AI. The “System of system” approach is a great way to tackle some of the difficulties of “emergent programming” (that is, algorithms that are “grown” from data and work as “back boxes”). A system of system approach enables the combination of high-performance low-control modules with simpler forms of AI that may be verified or certified. In the podcast, I imagine a smart robot that aids to open and close doors in your home. It is clear that most of us would like some form of certification about the operation safety before letting the robot operate in their homes in the presence of young children. A system of system design supports the combination of advanced scene recognition using the best convolutive neural networks have to offer and lower-level safety checks based on symbolic AI and certifiable logic. We find here a precise example of layered-architecture biomimicry (where the advanced functions are under the supervision of simpler, more reliable modules) presented in the previous section.
I will now illustrate the principle of Systems of Intelligent Systems, and how it fits the idea of leveraging multiple forms of AI, with the example of an autonomous robot. I assume that the robot works in a production line, together with operators and other different robots, but that is has many similar instances working on other production lines, in the same factory or other factories. Thus, in the same way that Tesla cars can learn “collectively” by sharing their data, our autonomous robot is part of a larger group for which data can be pooled. As explained by Michio Kaku, our smart robot must combine two forms of learning: individual learning and “species” learning. The first form of machine learning is performed at the individual robot level, based on the flow of training experiences that the robot is subjected to. The second form of learning represents the knowledge that can be produced by other similar robots and shared with our individual robot. The figure below is a crude representation of a possible modular architecture for the robot (bottom part) and the group of robots (the “species”, top part). The bottom part illustrates the need and opportunity for many kinds of “smart sub-systems” for the robot. As pointed out by Yann Lecun, “Prediction is the essence of intelligence”. This robot implements a classical Decide-Goals-Plan-Execute strategy that is fed with the “situational intelligence” of the robot, which is produced by its own learning (the constant synchronization and enrichment, between the observation and the prediction, that produces a model of the world). This is another great idea brilliantly explained by Michio Kaku: we build our working model of the world by constantly comparing what we experience with what we expect, which is why we value surprises and humor so much. The picture also describes the combination of individual and collective intelligence (in a way that is very similar to our own amygdala, were our brain reconciles our cortex – the result of our individual learning – and emotions, which are “stored procedures” produced by Darwinian evolution). The proposed architecture assumes that, following the biomimicry principle, our robot also contains a “reflex” module which is hopefully certifiable and is there to ensure everyone’s safety. Although this is only a very simplified representation, this architecture is good illustration of what a system of intelligent systems could look like. It is easy to point out that different forms of AI are better suited for the various modules represented here. Neural networks are the obvious choice for perception, they would also be a great candidate for the main learning module. Evolutionary techniques are, on the other hand, well suited to derive collective intelligence from the “species” data (that would be hosted in a cloud in this picture). The prediction module could a be good candidate for hybrid approaches mixing different data science algorithms. The planning and execution modules are good places to use more traditional GOFAI. As told earlier, the reflex module is a good place to apply CEP (complex event processing) plugged directly onto the event flow, to ensure proven response time as well as safe behavior.
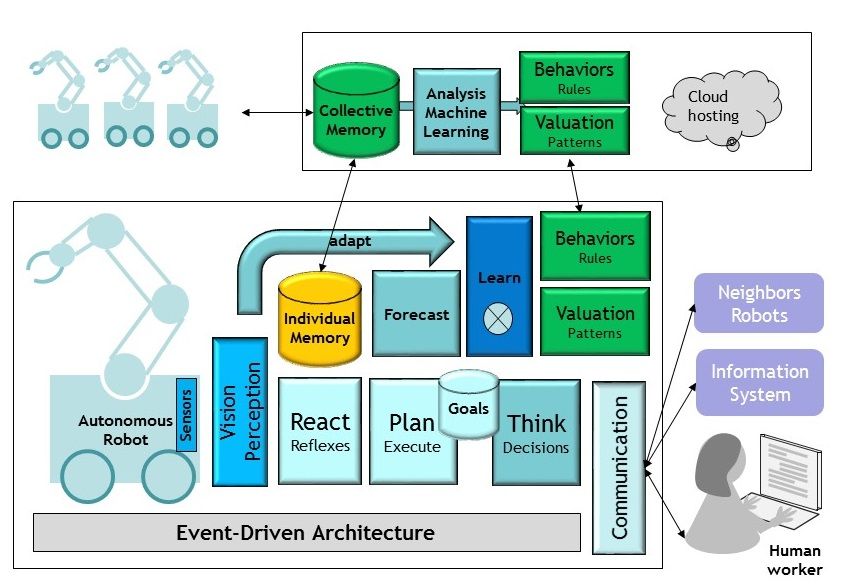
Thinking about « Systems of Intelligent Systems” has some interesting implications for the design of exponential information systems. First, ExIS are meant to be the hosts of such systems. This justifies our recommendation for event-driven architecture, as well as the data infrastructure that was presented in Section 3. Making sure that your information systems is ready to integrate components that will look like this autonomous robot is a great way to meet many of the exponential information systems requirement. As we integrate more and more “advanced modules” whose code is grown from data, the “level of abstraction” of our system engineering raises. We will continue to write code for decades, but the objects that our code produces and manipulates will grow in complexity and will show an increasing form of autonomy and adaptability. Second, it is also quite interesting to think of an ExIS as an instance of a “System of Intelligent Systems”. When we speak about AIOps, our end goal is to make the information system behaves like the autonomous robot represented in the picture above. Perception and Reaction are the two obvious functions that we implement today (i.e., smart monitoring and adaptative automation), but prediction is the obvious next step (for predictive maintenance). The endgame of the ACATECH maturity model is to design systems that continuously adapts and co-evolve with their environment. If this ambition applies to exponential information systems, it is likely that they will be built as “systems of intelligent systems”.
5. Conclusion
I will end this post with three ideas that resonate with the creation of a Michelin IT blog, which I am delighted, and proud, to welcome.
- There has never been a better time to be a software engineer. This is the consequence of the world digital transformation: as Mark Andreesen said, “Software is eating the world”. For all companies, including Michelin, more are more of the value-creating activities are produced with the assistance, or thanks to, software solutions. As Jensen Huang added, “AI is eating software”: writing and building software is changing dramatically in this data-driven world. This makes our job as software engineers even more exciting and challenging. Many of our future software components will be “grown, not designed”.
- There has never been a better time to be a system engineer. The challenges of the exponential organizations place a lot of requests on information systems. The good news is that there are ways to meet these requirements, through excellent system design and engineering. These are two sides of the same coin, with the digital and VUCA world, “code is back” and “system thinking is mandatory”.
- We live an exciting time from a technology viewpoint, this is the moment to be as open as possible and to learn from each other. This is one of the reasons for opening a Michelin IT blog. It is meant as a platform for continuous learning, to share ideas and a passion for building the next generation of software systems.