
Managing Gitlab instance on Azure
Details about our Gitlab architecture and deployment process mainly based on Azure managed services with databases, cache and file storage.

{kind=link}

Over the last few years we have started a switch to Gitlab as the core of our Software Factory.
Our main objective was to ease the usage and the integration of all our tools by promoting self-service and encourage internal contributions between projects.
With more than 1000 applications developed worldwide that cover all Michelin businesses (B2C, B2E, B2B), Gitlab is continuously used by 1700 users and integrated with many external tools like Jira, Gitlab CI, Microsoft Teams, Jenkins, and Kubernetes.
Components of Gitlab architecture
Since Gitlab is the core of our DevOps toolchain, it can be an important point of failure in our development and release process. To mitigate this risk, one of our major requirements was to have our Gitlab instance in High Availability (HA).
Another important point for us was to minimise the number of components to ease the maintenance of the solution and achieved what we call Evergreen at Michelin: regular upgrades and reduced outages.
We can represent a very simplified architecture of gitlab with the schema below:
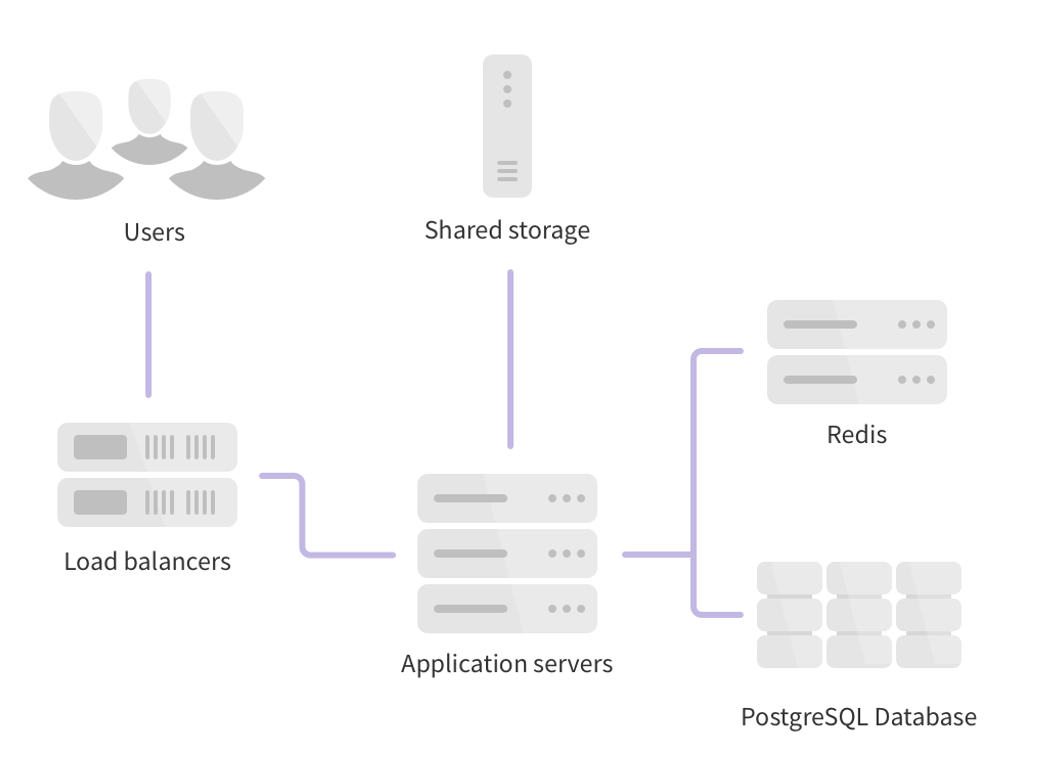
Azure Implementation
Our Gitlab instance is fully deployed on Azure through managed services and Virtual Machines.
The use of Azure made it possible to move from a central instance with all components on a single virtual machine (VM) to a horizontal architecture allowing us to implement high availability and be able to anticipate the scaling needs. Our implementation is quite aligned with Gitlab recommendations described in its reference architectures.
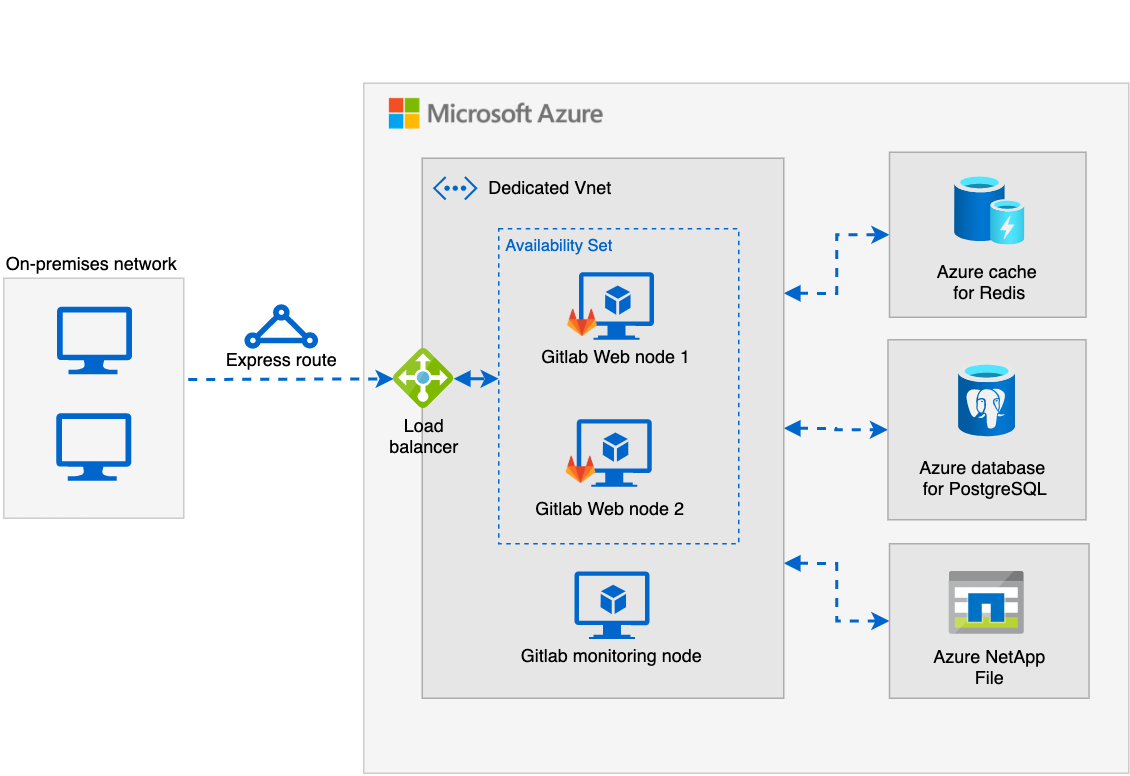
Let's now take a deeper look at the different components of this architecture.
Application Servers
We are using three virtual machines (2 Standard F8s_v2 and 1 Standard B2ms). The first two VMs are the same and used to host the Gitlab web UI (Puma ruby web server), the "Git server" (Giltab Shell, Workhorse, Gitaly) and the asynchronous task scheduler (Sidekiq). To increase the availability of these VMs we used an Availability Set to isolate VM resources from each other. Azure makes sure that the VMs in an Availability Set run across multiple physical servers, compute racks, storage units, and network switches to avoid hardware or software failure on both VMs at the same time.
The third VM takes care of the monitoring. It hosts all prometheus exporters for Azure managed services and exposes these metrics through a Grafana server. This help us a lot to monitor and troubleshoot issues on our instance.
Load Balancer
To expose our Gitlab service internally, we are using an internal "Azure Load balancer". For that, Azure provides two references the standard and the basic one. The standard allows us to support zone redundancy to avoid outage, https health probe based on the readiness endpoint exposed by Gitlab and have a SLA of 99,99%.
When multiple VMs are linked to an "Azure load balancer", the default distribution mode specifies that successive requests from the same client may be handled by any virtual machine behind. This distribution allows us to lose a node without outage and also distribute the load between two instances.
The load balancer exposes HTTPs and SSH to enable Git project manipulation with both protocols (Git over HTTPs or over SSH). The HTTPs protocol is also used for the Gitlab web UI.
Databases
Internally Gitlab uses two databases Postgres and Redis:
- Postgres to store all data non-related to Git files like users, rights, issues, projects, configurations ...
- Redis is mainly used for caching data and managing asynchronous tasks state.
For Postgres, we use the managed service "Azure database for PostgreSQL" which provide automatic geo-redundant backup storage in case of disaster and also auto growth storage. This allows us to reduce database maintenance tasks by not having to manage a Postgres HA cluster. But when we need to upgrade a major version of PostgreSQL (like v10 to v11) we need to perform this migration ourselves since in-place upgrades for major versions are not supported in Azure.
For Redis, we use a Premium instance of "Azure Cache for Redis" that provides native zone redundancy, Replication and failover.
Shared File Storage
Gitlab is performing a lot of input/output operations per second (IOPS) to manage all projects data and CI artifacts, and we don't want to manage ourselves a high available NFS cluster. For that, we use Azure NetApp Files service with 5 TB of storage on the premium tier based on Network File System (NFS) 4.1.
Currently, the two Gitlab web node automatically mounts the NFS share to manipulate the same files.
With this service, you can split the storage into multiple volumes, but the throughput of the NFS share is proportional to the size of the volume behind, so to have highest IOPS, we have only one volume with 5 TB of data.
The size of the NFS share is not the only factor to come into play in the IOPS calculation. The VM's bandwidth is also important and it depends on its flavor.

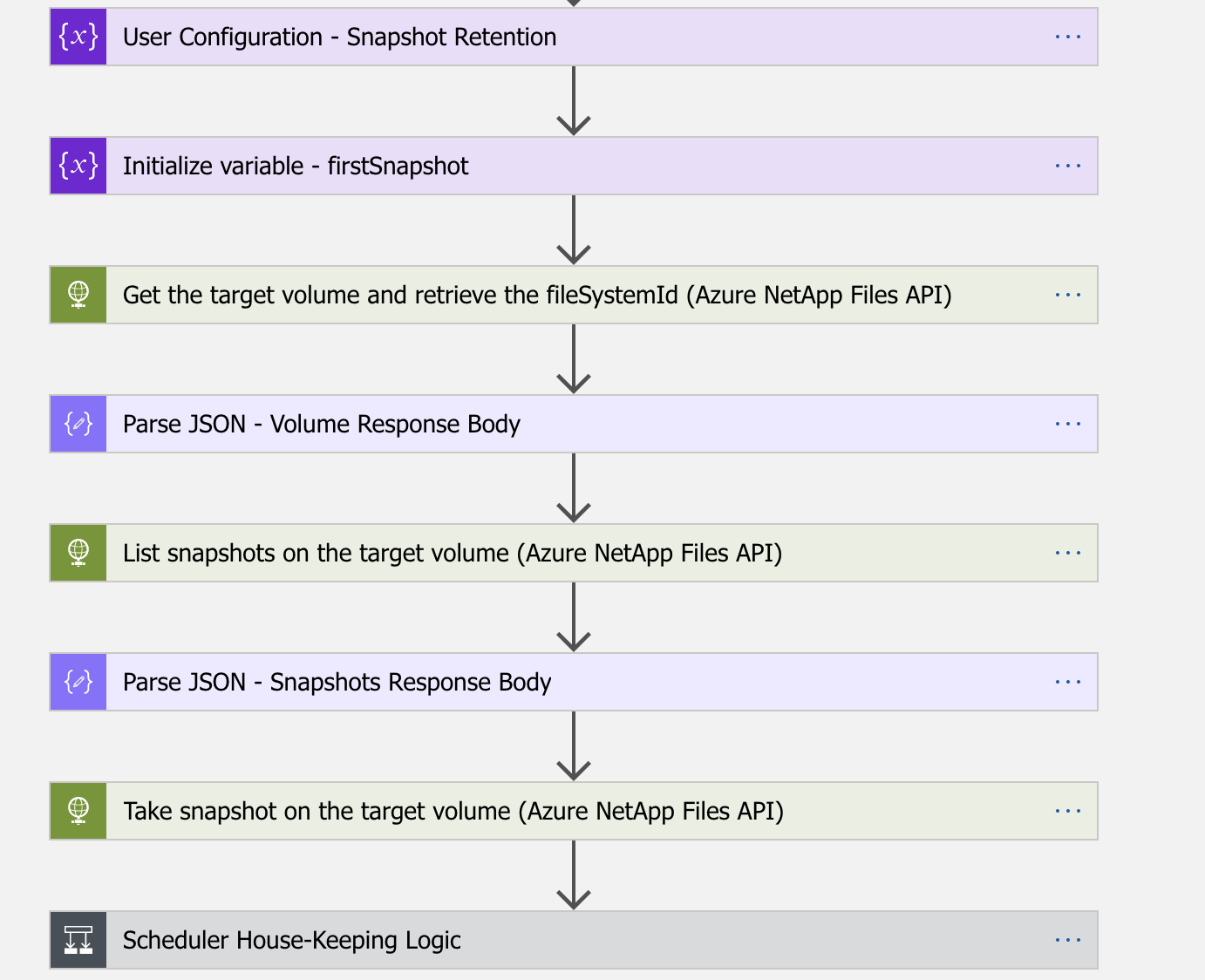
Using this managed service ease our maintenance on this component by providing simple snapshot functionality and on the fly storage increase.
Our Azure NetApp Files Snapshots are scheduled with an Azure "Logic app" every 12 hours with 30 days retention.
 kirkryan
kirkryan
Since NFS support is now deprecated by Gitlab we plan to move to Gitaly cluster that provides storage for Git repositories and also supports clustered configuration.
Disaster Recovery Plan
The use of Azure managed services allows us to simply move our infrastructure to another datacenter in case of a disaster in our main datacenter. We can achieved this through geo-replicated backups.
Today, our main Gitlab instance is on the same datacenter and backups are geo-replicated in another region. The implementation of an active Geo-distributed architecture for our Gitlab instance on several datacenters was not retained because Azure services ensure a short Recovery Time Objective (RTO) and a Recovery Point Objective (RPO) aligned with our needs for Gitlab in case of disaster.
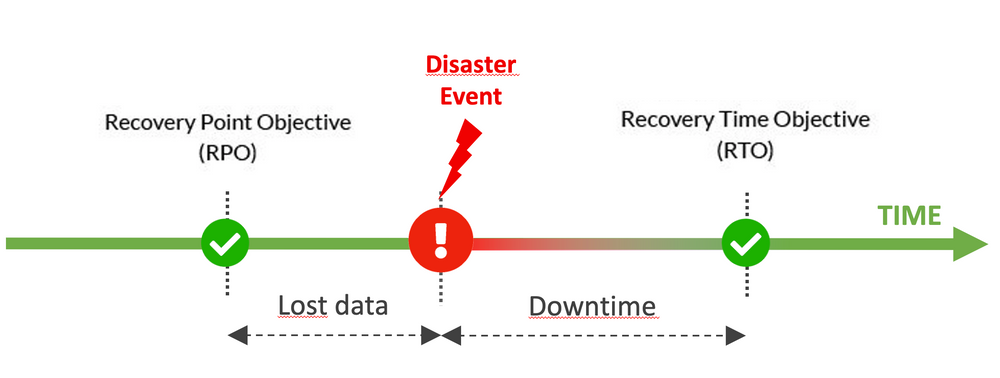
For example, the RPO for a Geo-restore from geo-replicated backups with "Azure database for Postgres" is less than 1 hour.
Git is a distributed version control system so even if we lost some data on the Gitlab server due to a disaster (like issues, comments, wiki), we can restore an important part of the source code lost between the RPO and the disaster event from local developers copies.
Deployment process
To manage all these components and deploy Gitlab upgrade easily, all the operational tasks are scripted with Ansible. For minor or patch releases, our upgrade process in now a one click operation.
Using managed services instead of deploying all Gitlab components in multiple VMs helps us a lot to decrease the maintenance tasks like OS upgrade and security patching, all these tasks are now performed by Microsoft.
Key figures

Conclusion
Gitlab is flexible enough to design its architecture according to our needs because. And the many common open source components on which Gitlab is built made it possible.
The usage of managed services from Azure is an important factor to drastically reduce our maintenance costs compared to the same thing on IAAS or hosted on premises. We acknowledge that it makes Gitlab upgrade a little bit more complex by forcing us to check the compatibility of all Azure service versions. Indeed, when using managed services, all scripts provided by Gitlab to perform upgrade (Chef cookbooks) no longer manage versions of external services but only the structure of the data they contain.