
Measuring Kafka uptime
Discover how Michelin teams measure Kafka uptime.

{kind=link}
Introduction
Michelin's transformation to Event Driven Architecture relies on Apache Kafka (and its ecosystem) as Streaming Platform and Processing solution. Internally we have been spawning couple of clusters to support either pure application use cases or wider Information System data flows.
Apache Kafka is well known for the built-in resiliency and low latency, the purpose of this post is to explain how Michelin teams compute Service Level indicators.
Disclaimer: The post will be limited to the Kafka cluster itself. Indicators on components like Kafka Connect or the Schema Registry will be covered in a near future ;-)
Before moving forward, is crucial to properly define how to measure when we consider a Kafka Cluster is "not delivering the service".
What's a Kafka Cluster downtime
A downtime is a duration in minutes when the service is not delivered (thanks captain obvious). Since Kafka is a streaming platform, it would make sense to consider it as unavailable as soon as:
- A producer can't write data anymore
- A consumer can't read data anymore
If we go back to how Kafka works.
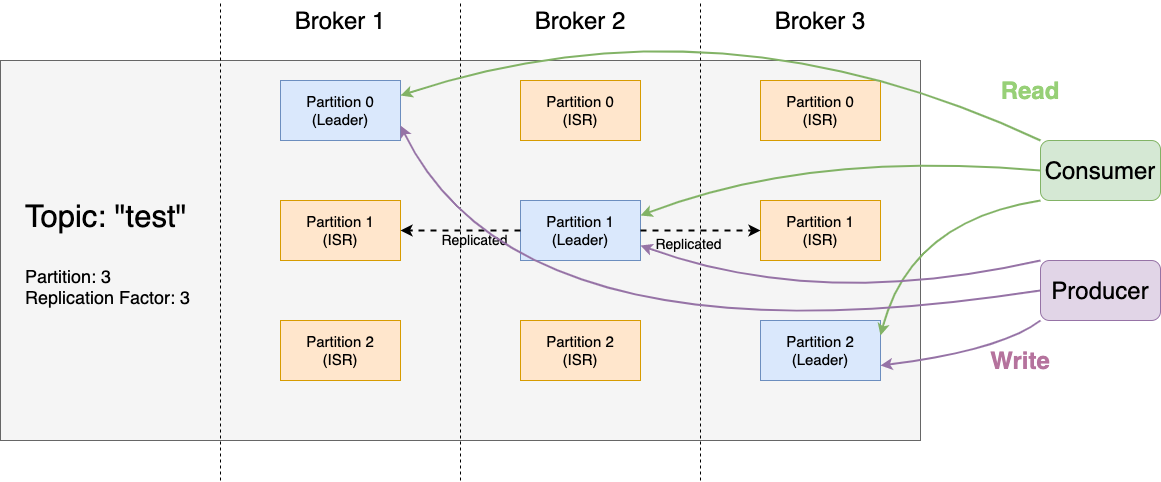
A topic is composed by partitions and partition are replicated (ie. duplicated). Among these partitions one is designated as leader. The partition leader is the one receiving both producers (writing) and consumers (reading) requests. The other replicas are here for durability purpose, we call that list the in-sync replicas (aka. isr)
So basically a producer can write data or a consumer can read if they have access to the leader for a partition of a given topic.
Kafka exposes a JMX metric to monitor that:
kafka.controller:type=KafkaController,name=OfflinePartitionsCount
Number of partitions that don’t have an active leader and are hence not writable or readable. Alert if value is greater than 0.
https://docs.confluent.io/current/kafka/monitoring.html
Whenever a Kafka broker (ie. the computer node hosting the partitions) is stopped or crash, the cluster detects it and re-elect, almost instantaneously, new partition leader among the in-sync replicas.
Enforcing Durability
At Michelin, durability is a Kafka property we want to enforce for our projects.
As explained above a topic's partition is replicated n times, this permits to loose one or more replicas and still have a copy of the data . At the topic level, we can define a minimum required number of in-sync replicas (ie. copy of the data synchronized) via the property min.isr.
On the producer side, we can configure the acknowledge (aka. ack) strategy when a message is pushed to the cluster:
ack=0"fire and forget" the producer doesn't even want to know if the message reached the cluster (used to optimize throughput and latency)ack=1it's the default configuration, the producer wants to be sure the partition leader received the message, but without any replication guarantee (if the node hosting the partition leader crash before the replication finished, the message will be lost).ack=allthe producer will receive a confirmation when the partition leader received the message plus the message has been replicated to fulfil the topicmin.isrrequirement.
To limit the risk of message loss, the topics should define a min.isr and the producer defines an ack=all and retry infinite. Whenever the min.isr couldn't be satisfied, the producer wouldn't acknowledge the message thus be blocked in its data writing. (For french people, we recommend the Apache Kafka: Patterns/Anti-Patterns video or the slides).
Back to our "unavailability " definition, within a context where you want to enforce durability, a producer can't write if the min.isr constraint can't be satisfied.
Again Kafka exposes a JMX metric to monitor that:
kafka.server:type=ReplicaManager,name=UnderMinIsrPartitionCount
Number of partitions whose in-sync replicas count is less than minIsr.
https://docs.confluent.io/current/kafka/monitoring.html
The magic formula
Given the durability constraint we want to enforce and based on the 2 above metrics we can define the downtime as follow
downtime = (OfflinePartitionsCount > 0) OR (UnderMinIsrPartitionCount > 0)
Usually a Service Level is computed on a period, here for the demo sake we will use 30 days.
ServiceLevel = nbMinutes(downtime) / (30 * 24 * 60)
Caveats
Bad topics configuration impact the cluster Service Level
Depending on your workflow of topic creation, the Service Level we propose can be significantly impacted despite providing a good service:
- A topic is created with a
replication-factor=1, that means as soon as you stop the broker hosting a partition leader of this topic, it will generate offline partitions thus trigger a downtime. - A topic is created with
replication-factor=3, min.isr=3, whenever you stop a broker themin.isrcondition can't be fullfill triggering a under min isr alert and a downtime
These examples show 2 anti-patterns of topic configuration, but they are commons failures in teams lacking of Kafka knowledge or guidance.
At Michelin, part of the topic creation are delegated to the project teams and we consider that good topic configuration is the starting point of a proper resiliency. We accept this caveat and use it as maturity sensor to detect the teams we have to coach. In a nutshell, the cluster service level depends on the Kafka skills of both dev and ops people.
Using cluster metrics does not provide an "application" Service Level
At the end of the day, the business user using an application relying on Kafka does not care about the cluster health, he/she's executing an end-to-end process (producer-cluster-consumer). You can provide the best Kafka cluster ever, if the link between producer/consumers and the cluster is bad, the overall "Kafka" experience is bad.
Moving to an "application" Service Level definition
In complement of measuring the internal cluster values, it can make sense to have an end-to-end monitoring. The easiest way to do that is by having a producer/consumer (can be simple kafka-console-(producer|consumer) shell scheduled).
Place them strategically in your network. Now, if for some reason a producer can't write because the network is having lags and the retry mechanism can't compensate, you basically have a downtime of the Kafka service.
Note: You can also use this strategy to measure the latency of your pipeline (difference between the timestamp of data reception and data production). In some case, a latency too high can also be considered as a downtime.
Usually, IT department are silo-ed, and each team tries to improve locally its service. At Michelin, we believe that solutions should be addressed in a systemic manner involving all the actors to improve the end-to-end experience. So yes, maybe the Kafka Service Level will be bad because the network is bad, but at the end is everybody responsibility to deliver the best solution for the user.