
Ordering guarantee when using Qlik Replicate and Apache Kafka
Streaming a database looks simple with Change Data Capture and Kafka. This post will explain the pitfalls and solutions when dealing with events ordering.

{kind=link}

Disclaimer: The following post will focus on Oracle as data source and Kafka as target.
TL;DR:
- Switching from a "state-oriented" (database paradigm) to "event-oriented" (Kafka) comes with a lot of subtiles details
- Qlik Replicate captures table record changes in a technical order and propagation order is configurable.
- Kafka can’t guarantee global (cross-topic) ordering
- Qlik Replicate changes metadata can be used in Kafka Streams permits to rebuild the source technical order
- You should evaluate the feasibility to build a "ready-to-be-streamed" object before Kafka.
Why should I care about ordering in a first place?
In a traditional world, the application handle a business object and at some point wants to persist it. To do so, we open a transaction to spread this business object into multiple tables. To full fill the database 3-Normal Form, the SQL statements are ordered to respect the foreign keys integrity and if for any reason something goes wrong we rollback everything. Inside the database, these mechanisms are mature and well known by every one.
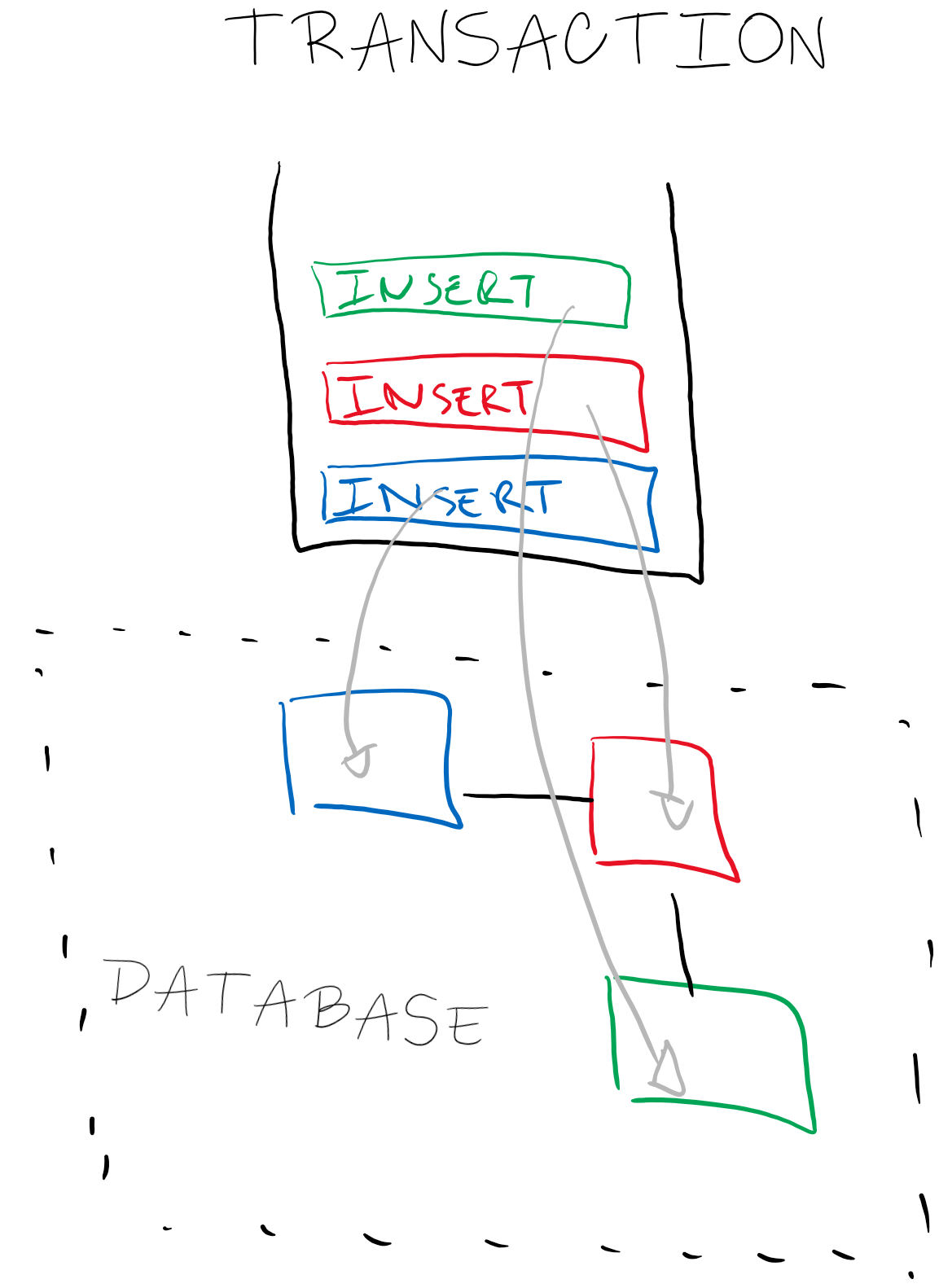
In the post "Legacy integration, a story of modernisation" we have been using Qlik Replicate as Change Data Capture tool and Kafka (plus its ecosystem) to transform the database as a streaming data source. Among others, one of our biggest challenges has been do reproduce a "simple" join data coming from different tables. Sounds crazy, right?

Given a parent (Author)-child (Post) table relation with a classic foreign key, how can we guarantee:
- an INSERT event will always be processed before an UPDATE.
- an event from the Parent(Author) table will processed before an event from the Child (Post) table.
- events from both tables are coherent from a temporal viewpoint when the join will is performed.
Before diving into the technical options, let's define what "ordering" means.
What do we call ordering?
Ordering means putting items into a particular order.
It’s important to understand 2 aspects: Sequential and Chronological.
Assuming we receive a list pair of timestamp and a letter: (T0, A), (T1, B), (T2, C). There are different orders possible:
- By timestamp: (T0, 1), (T1, 3), (T2, 2).
- By letter : (T0-A), (T2-B), (T1-C)
Both orders are valid and are context dependent.
Back to how Qlik Replicate works
From a very high-level (an opinionated) perspective, Qlik Replicate is a replication tool which
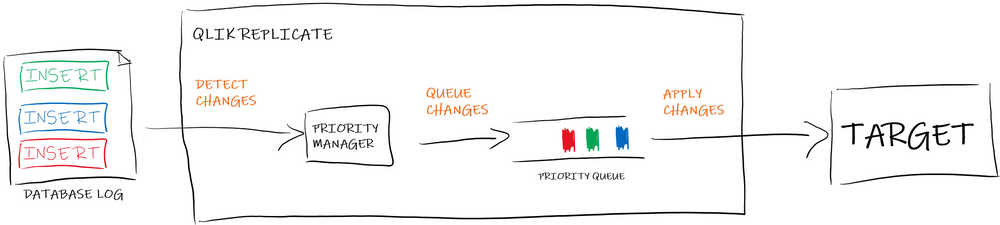
1- Detects changes
It will read sequentially the Oracle (redo/archive) logs to capture changes. These files are logs, ie. append only, immutable list of items. The database actions are ordered by appearance on these logs.
2- Queue changes
Once detected, the event is placed into a queue waiting to be pushed to the final target. Qlik Replicate permits to configure a priority per table. This priority will define in which order the events will be stack into the queue thus the order they will be pushed to the target.
3- Apply changes
At this point, it’s important to keep in mind that each target is different (file vs Kafka vs DB) Qlik Replicate simply push the data onto the target and log failures. The target can still reject data (Eg. because the changes sequence violates integrity constraints) but it would be a manual task to re-process it.
Ordering metadata
Qlik Replicate unit of work is the table record change. For each change, we will find metadata with the following information:
{
..."headers": {
"operation": "INSERT",
"changeSequence": "20200422211145000000000000000000093",
"timestamp": "2020-04-22T21:11:45.000",
"streamPosition": "00000000.0011c2b7.00000001.0004.01.0000:5.58278.16",
"transactionId": "00000000000000000000000000100007",
"changeMask": "07",
"columnMask": "07",
"transactionEventCounter": 3,
"transactionLastEvent": true
}...
}
changeSequence: A monotonically increasing change sequence that is common to all change tables of a task.timestamp: The original change UTC timestamp.transactionId: The ID of the transaction that the change record belongs to.
How can I order Qlik Replicate changes ?
Chronological order
Assuming we have the following transaction
BEGIN
INSERT INTO TABLE_A ...
INSERT INTO TABLE_B ...
INSERT INTO TABLE_C ...
COMMIT
Because you can configure the table processing priority, if TABLE_C has a highest priority, it will be process before the 2 others.
If you look for a chronological order, you must use the changeSequence information. Sorting in a natural order (ie. the smaller the number is, the older the record is) the sequence will re-generate the source changes order.
Note: This changeSequence number is specific to a Qlik Replicate task, which means you can’t “consume” data coming from multiple tasks and rely on this sequence number to rebuild an a global changes sequence.
For a cross-task ordering, you will have to complete your ordering with transactions information.
Transaction identification
Transaction identification is great but implies to collect all the records involved on the CDC destination (ie. Kafka in our context)
- Group the events by
transactionIdto have the events per transaction - Sort the events by
transactionEventCounter - Consider the transaction has finished when you have
"transactionLastEvent": true
Note: One could be tempted to use the timestamp to order the transactions records. We do not recommend to use this information since it’s an approximation (and truncated to the milliseconds), is likely probable you fail to rebuild the changes sequence.
Qlik Replicate and Kafka ordering
Kafka and ordering
Kafka is made to be distributed and scalable hence the data received will be split into pieces which can be distributed over the network (into partition), individually store and processed in parallel. As such, Kafka choose local consistency (by partition) rather than a global cluster wide consistency.
When Kafka receive a message, it will be sent to a partition base on the message key. Kafka ensures the records order per partition (ie. message by key) ). As a consumer, subscribing to all the partitions of a topic, there is no guarantee you will read the message in the same order the producer send it.
It’s important to keep in mind, ordering will be a trade-off.
Global ordering
As explained, Kafka ensures the ordering per partition so if you want to consumes in the exact same order that Kafka received the data that means all the messages has to be in one topic with one single partition.
It’s important to keep in mind that this configuration is simply skipping the partitioning feature of Kafka, as such it will sacrifice performance and scalability.
Remember you can configure the table priority in you replication task. Updating the priorities will introduce a difference between the order of changes captured by Qlik Replicate and the one forwarded to Kafka. If Qlik Replicate detects an event on AUTHOR then POST but you configured a higher priority on POST, then the first message Kafka will receive will be the one coming from POST.
Changes ordering per record id
By configuring Qlik Replicate to send 1 table per topic and partition by primary key, you will be able to consume the ordered changes sequence of a record without any particular processing.
If your use-case is to consume the table records in a totally independent manner (ie. no SQL-joins) then this configuration is the easiest and scalable one.
In a real world, it is likely you want to consume data coming from several tables, for instance, to resolve a foreign key. How to order changes coming from multiple tables/topics will be covered in the next section, however for simple scenarios there is a "hack".
For some use cases, it could make sense to use the same target primary key for several tables. This option is similar the "global ordering" solution about only for a subset of tables of a task. Qlik Replicate permits to override the target primary key (which is use as Kafka partitioning key) and destination topics.
Given a AUTHOR table with an id primary key and a POST table with an author_id foreign key. We could configure both tables to be pushed to the same Kafka topic TOPIC_AUTHOR_AND_POST, use the id key as partition key for the AUTHOR change events and use author_id for the POST changes. We end up with a single topic with events coming from 2 tables and use the same partitioning key.
Note: Having different tables in the same topic implies having different Kafka message structure into the same topic... This configuration brings a lot of side effects when the messages are processed .
Changes ordering cross tables/topics
The more common use case is a task capturing changes from multiple tables and sending each table into a dedicated topic (partitioned by primary key). In that scenario, ordering a set of changes across topics with require processing and state management.
When you subscribe to multiple topic/partitions, you can use a Kafka stream to store locally a group of related events (like a transaction for instance). Since the changes are captured in a single Qlik Replicate task, you can rely on the changeSequenceNumber to sort the event and use the transactionId, transactionEventCounter and transactionLastEvent to identify the beginning and the end of transaction. Once the sequence ordered you can do whatever you like
- use a more meaningful key to store records coming from different sources into a partition (thus take advantage of Kafka partition ordering property)
- Build a new object (ie. a data structure representing a transaction) which contains an ordered list of changes
- Build a business oriented object based on database events.
Wait a second, why do I need ordering in the first place?
Let's take a step back on our issue: if you remember all this ordering issue has been triggered by an attempt to basically reproduce a SQL-join (data consolidation) in a streaming platform with distributed data.
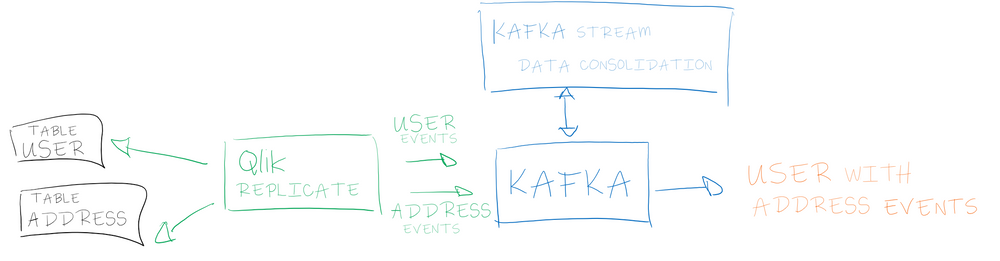
It's very likely that the initial transaction you want to rebuild already represent a logical business object simply exploded to match the database paradigm (tables and foreign keys).
Wouldn't be easier to propagate an already-consolidated object rather than unitary piece of information?
Qlik Replicate proposes one way to do that. When capturing a change on a table, the Change Data Capture permits to do a lookup (ie. a SQL statement) to fetch relationship details and build on-the-fly a consolidated object.
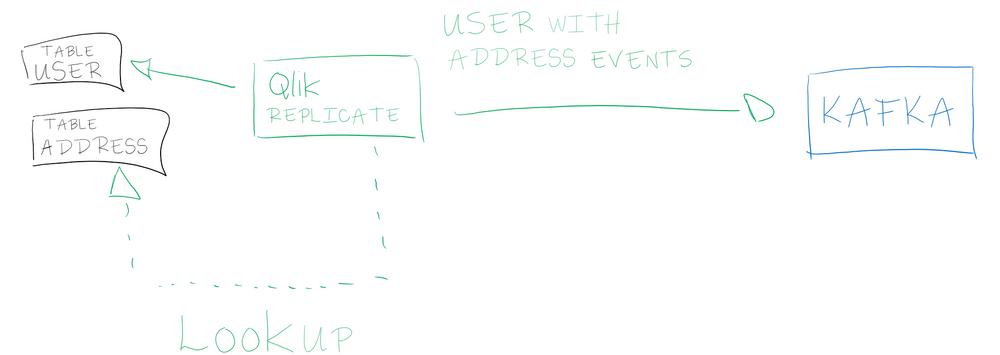
This feature permits to delegate to the Change Data Capture tool part of the data structuration. Another solution is to use "Outbox Pattern" which basically tries to also build a ready-to-be-streamed object but directly in the database rather than in an external tool.
At this point, it would be temping to think the Change Data Capture tool is a data cleansing solution. Keep in mind, we are talking about nothing more than lookups, the purpose is to prevent to propagate the database semantics/paradigm. The "business rules" should be carried by a processing out of the Change Data Capture.
Conclusion
Ordering is a complex topic which implies a lot of technical and functional considerations. This post aimed to explain both Qlik Replicate and Apache Kafka definition of "ordered events" and what happen when they are combined. If you know the object you want to build, maybe the easiest solution is shift-left and prepare it either in your database or in the CDC tool. As always, knowing how the data will be used helps to make an enlighten choice ;-)