
How to 'Kstreamplify' : your new way to develop Kafka Streams application



Spoiler alert
-
After Ns4Kafka feature to bring controllers on top of Kafka resources (Topics, Kafka Connect and Schema Registry)
-
After kafkactl CLI linked with Ns4Kafka that lets you deploy your Kafka resources using YAML descriptors.
We're thrilled to announce a brand new open source tool around Kafka: a Java library that brings new features on top of Kafka Streams and make it really easy to work with this streaming library.
Check it out, it's pure awesomeness ! Kstreamplify
Long Story Short
If you use Kafka Streams and :
- If you search facilities to bootstrap new applications in the blink of an eye
- If your dream is to have a library, somewhere, that would guarantee that your application wouldn't crash in a loop in production because you forgot to manage a poison pill message, or because you forgot to null-safe that map node...
- If you are looking for a capability already used in production by several applications made by a serious company for whom stream design is not a new story
Then simply follow the link : Kstreamplify
Prerequisites and context
What is Kafka ?
Apache Kafka is a distributed event store and stream-processing platform. It is an open-source system developed by the Apache Software Foundation written in Java and Scala. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. (Wikipedia)
What about Kafka Streams ?
Kafka Streams is a client library used to build stream processing applications and microservices.
It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka's server-side cluster technology.
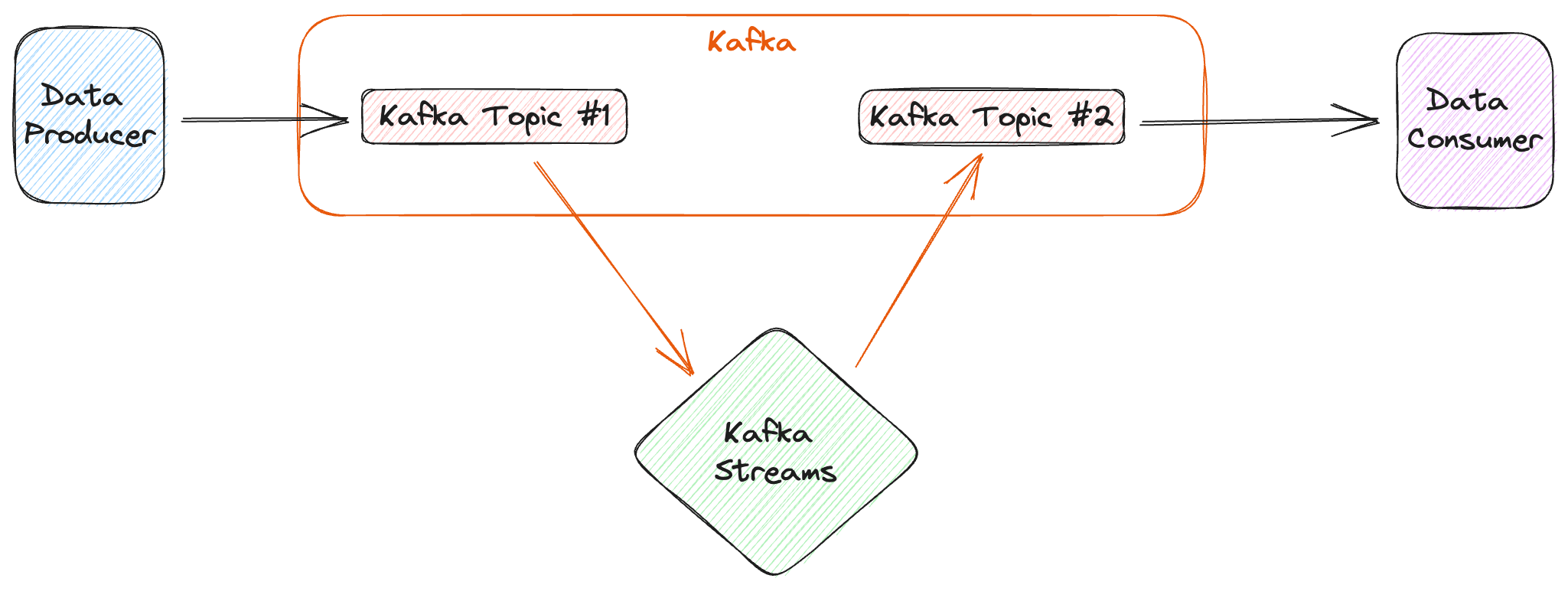
Kafka Streams is dedicated to "Kafka to Kafka" flows, if your need is to get data in or out of Kafka, there are other libraries or technologies, but that's another story...
Today, we will talk about how to use Kafka Streams the easiest way that is possible.
Why would we like to simplify our life :-)
From 2021, we wrote several articles around the replatforming of an application seen as the heart of the supply chain at Michelin.
You can find out below the detailed posts about replacing an ERP application, our Orchestrator, by an event based application implementing the concept of choregraphy.
(Links: Part1, Part2, Part3)
High Level Architecture
To support this replatforming we decided to implement a microservices architecture, based on Kafka as event hub.
The application, which is java based using Spring Boot framework, implements the choreography of events in our microservices. To technically support those features we used the Kafka Streams library.
From a pure functional point of view, this application is following around 20 business processes, each Business process is split into 20 steps and each step is waiting on an internal or external event. In addition to this complexity, this application is linked with 100 others applications and systems of the supply chain at Michelin.
Understanding this context will help you to understand the challenge we faced.
To rebuild this whole ecosystem we had to build around 400 Microservices based on more than 1200 topics.
To achieve this, we built a team composed of 10 developers and encountered some hard challenges.
Our challenges
- Ensure each team is not reinventing the wheel for each new service
- Share common rules/patterns for development and operability stand point
- Facilitate onboarding process for new developers and new teams
- Guarantee maintainability of this new solution
As nothing existed out of the box, the Product team has decided to create a new framework for Kafka Streams applications.
At Michelin, we have a strong and really active community of practices around Kafka topics and we decided to share this framework. First step has been an internal sharing among Michelin teams. That was really interesting to get feedbacks from other teams and enriching our library from other projects needs.
It was a great experience but we quickly find out that opening this to the open source community could be really profitable for Michelin and all other companies. Strong in this conviction, we took one step forward and decided to adapt it and make it available as an open source library.
In this article we will present the capabilities of our framework and how you can integrate it in your own technical stack. It has been designed to be really easy to set up.
Motivation
"
Our aim is to provide a comprehensive solution that simplifies the development process and addresses common pain points encountered while working with Kafka Streams."
In Michelin, we started to use Kafka in 2018 as our distributed event streaming platform. We were quickly interested in streaming features offered by Kafka Streams libraries. We set up our first big kafka project with our ERP orchestration replacement.
It was our first steps around this streaming technology and we overcame the first pitfalls by taking this opportunity to raise the skills of our developers. As we had a big squad working on this topic it went well and we managed to set up a really powerfull and resilient tool.
After this first step into streaming, our Kafka stack kept growing more and more and we initiated a Community of Practice around Kafka and Kafka Streams usage to help projects and developpers to step up and overcome the first difficulties sharing informations between all members.
One of the lessons learned by this community is that developing applications with Kafka Streams can be challenging for a developper and it often raises many questions. We encountered frequently some considerations such as efficient bootstrapping of Kafka Streams applications, handling unexpected business issues, and integrating Kubernetes probes, among others.
To assist developers in overcoming those challenges, we have built this library. Our aim is to provide a comprehensive solution that simplifies the development process and addresses common pain points encountered while working with Kafka Streams. In the meaning time, we accelerate our time to market on our applications.
KStreamplify key features
Architecture
We decided to base this framework on Michelin technical Golden Path.
Actually, the technical stack is the following one: Spring Boot and Java with the latest version of Kafka client library.
You will find below an overview of the modular architecture decided for this project :
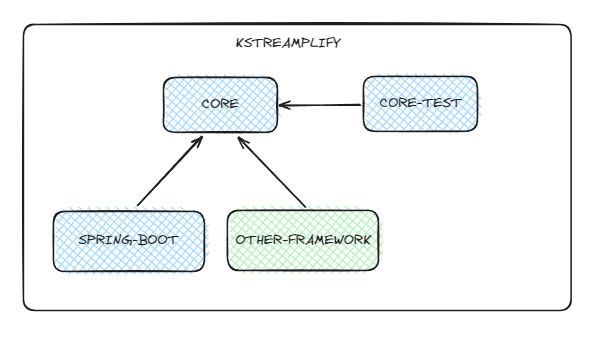
The modular aspect of the framework makes it easy to customize. It could be really simple for example to add a new framework like Quarkus or Micronaut.
Main features
Bored of bootstrapping your applications ? Properties injection, error handling, all technical prerequisites are already handled by the library. You want to create Kafka Streams applications and focus on topology for Business uscases implementation instead of bootstrapping ? KStreamplify will do it for you !
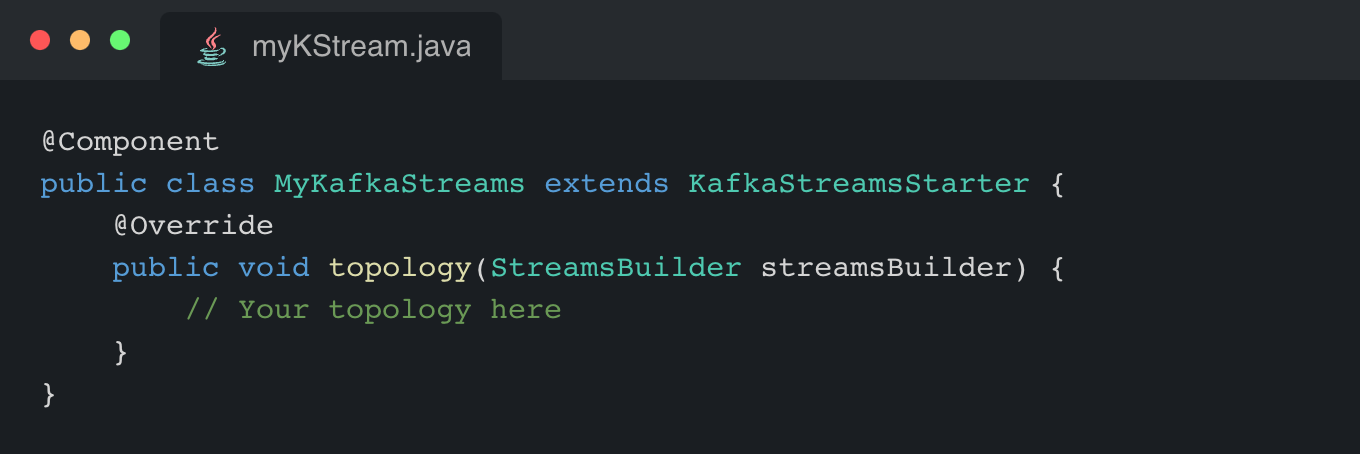
In our context, we decided to serialize our events in Avro on almost all our topics. This implies that Serializing/Deserializing is a real recurrent need.
As a reminder, in computing, serialization is the process of translating a data structure or object state into a format that can be stored. Everything you need to read or write your Avro data is embedded in the library: Common serializers and deserializers for all your Avro specific records.

Handling errors has always been a frustrating step developing an application. Thanks to kstreamplify a strong error handling mechanism is provided for any type of errors. Can it be a technical one like topology, production or deserialization errors or even business exception, you can route all those errors into a dead letter queue (DLQ) topic.
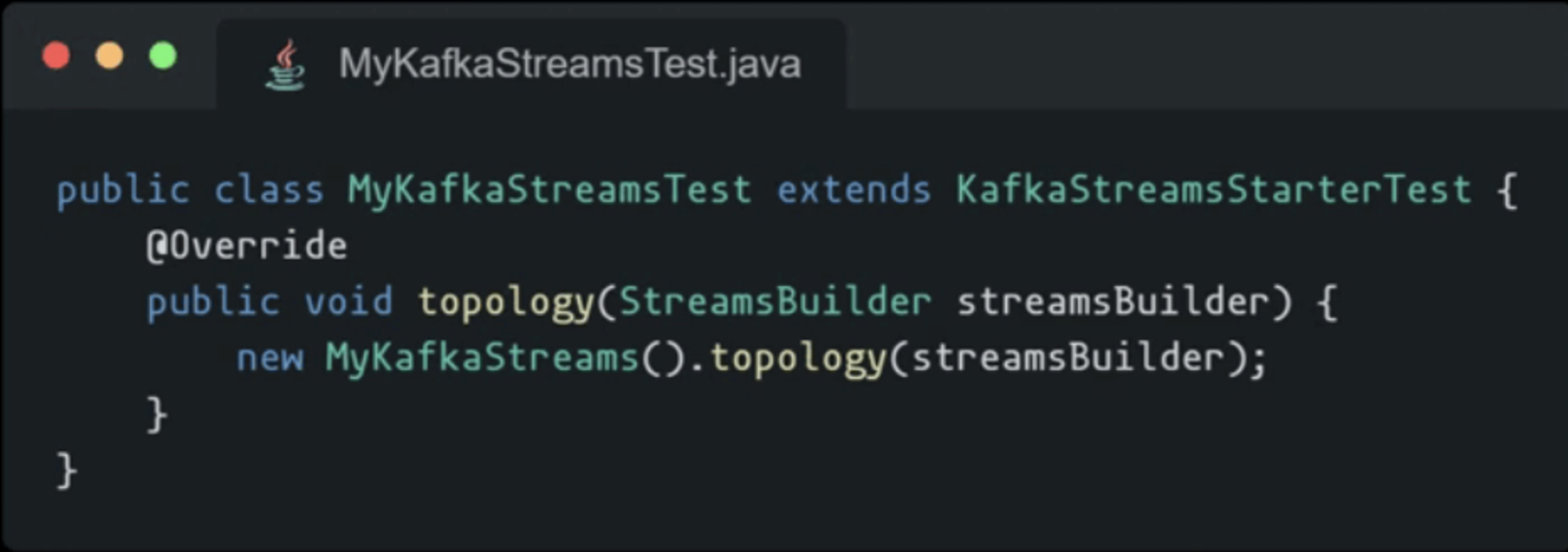
Please find below a simple example of a full Kafka Streams application :
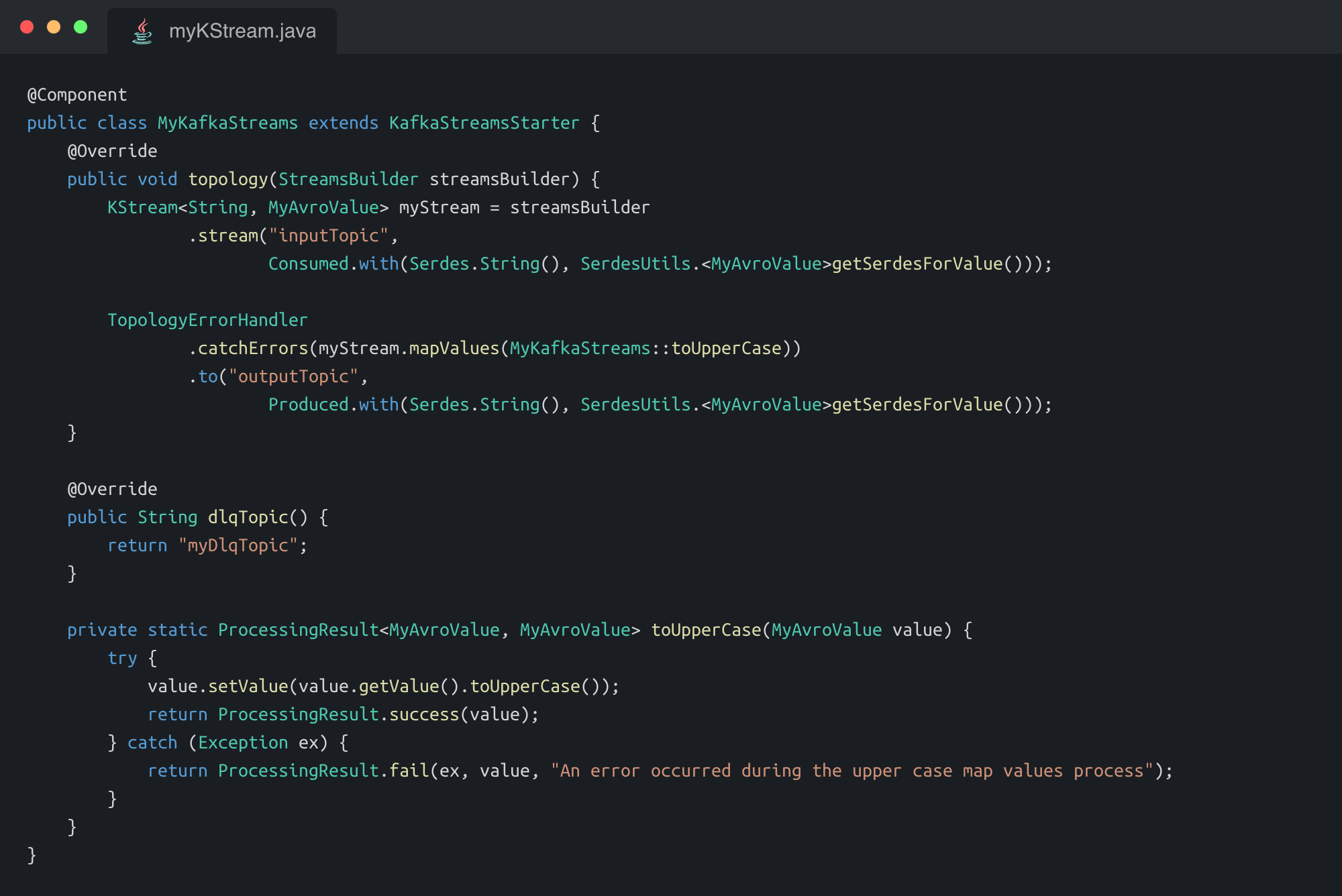
If you want to deploy your application on Kubernetes, this is where we provide the most value providing REST endpoints to handle liveness and readiness probes based on internal Kafka Streams states.
GET /ready: This endpoint is used as a readiness probe for Kubernetes deployment.
GET /liveness: This endpoint is used as a liveness probe for Kubernetes deployment.
When developing with Kafka streams, you have to live with topologies and to help you around these, you will now be able to simply use :
GET /topology: This endpoint returns the Kafka Streams topology as JSON.
Application development cannot go without testing. For this part also, we will help you to go faster and better. Let yourself be guided around the usage of Topology Test Driver. The library facilitates the bootstraping of the Topology Test Driver Api to easily write topology unit test for Kafka Streams applications.
Feel free to have an advanced look at Kstreamplify features directly on our github :
https://github.com/michelin/kstreamplify/blob/main/README.md#features
The World of the Open Source At Michelin
I would like to say a big thanks and congratulations to main contributors of the project : Clément Vacher, Adrien Calimé, Loïc Greffier, Sébastien Viale, Marie-Laure Momplot
In a futur blog post, we will explain you why it is important for a company like Michelin to contribute actively to the Open Source community providing new projects and helping others to get more efficient.
Don't miss it ! Keep in touch and stay tuned !